
GitHub - bencheeorg/benchee: Easy and extensible benchmarking in Elixir providing you with lots of statistics!Easy and extensible benchmarking in Elixir providing you with lots of statistics! - bencheeorg/benchee
Visit Site
GitHub - bencheeorg/benchee: Easy and extensible benchmarking in Elixir providing you with lots of statistics!
Benchee 





If you have benchmarked using elixir 1.14.0 - 1.16.0-rc.0, please check out known issues
Library for easy and nice (micro) benchmarking in Elixir. Benchee allows you to compare the performance of different pieces of code at a glance. It is also versatile and extensible, relying only on functions. There are also a bunch of plugins to draw pretty graphs and more!
Benchee runs each of your functions for a given amount of time after an initial warmup, it then measures their run time and optionally memory consumption. It then shows different statistical values like average, standard deviation etc. See features.
Benchee has a nice and concise main interface, its behavior can be altered through lots of configuration options:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(
%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
},
time: 10,
memory_time: 2
)
Produces the following output on the console:
Operating System: Linux
CPU Information: AMD Ryzen 9 5900X 12-Core Processor
Number of Available Cores: 24
Available memory: 31.25 GB
Elixir 1.16.0-rc.1
Erlang 26.1.2
JIT enabled: true
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 10 s
memory time: 2 s
reduction time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 28 s
Benchmarking flat_map ...
Benchmarking map.flatten ...
Calculating statistics...
Formatting results...
Name ips average deviation median 99th %
flat_map 3.79 K 263.87 μs ±15.49% 259.47 μs 329.29 μs
map.flatten 1.96 K 509.19 μs ±51.36% 395.23 μs 1262.27 μs
Comparison:
flat_map 3.79 K
map.flatten 1.96 K - 1.93x slower +245.32 μs
Memory usage statistics:
Name Memory usage
flat_map 625 KB
map.flatten 781.25 KB - 1.25x memory usage +156.25 KB
**All measurements for memory usage were the same**
The aforementioned plugins like benchee_html make it possible to generate nice looking HTML reports, where individual graphs can also be exported as PNG images:
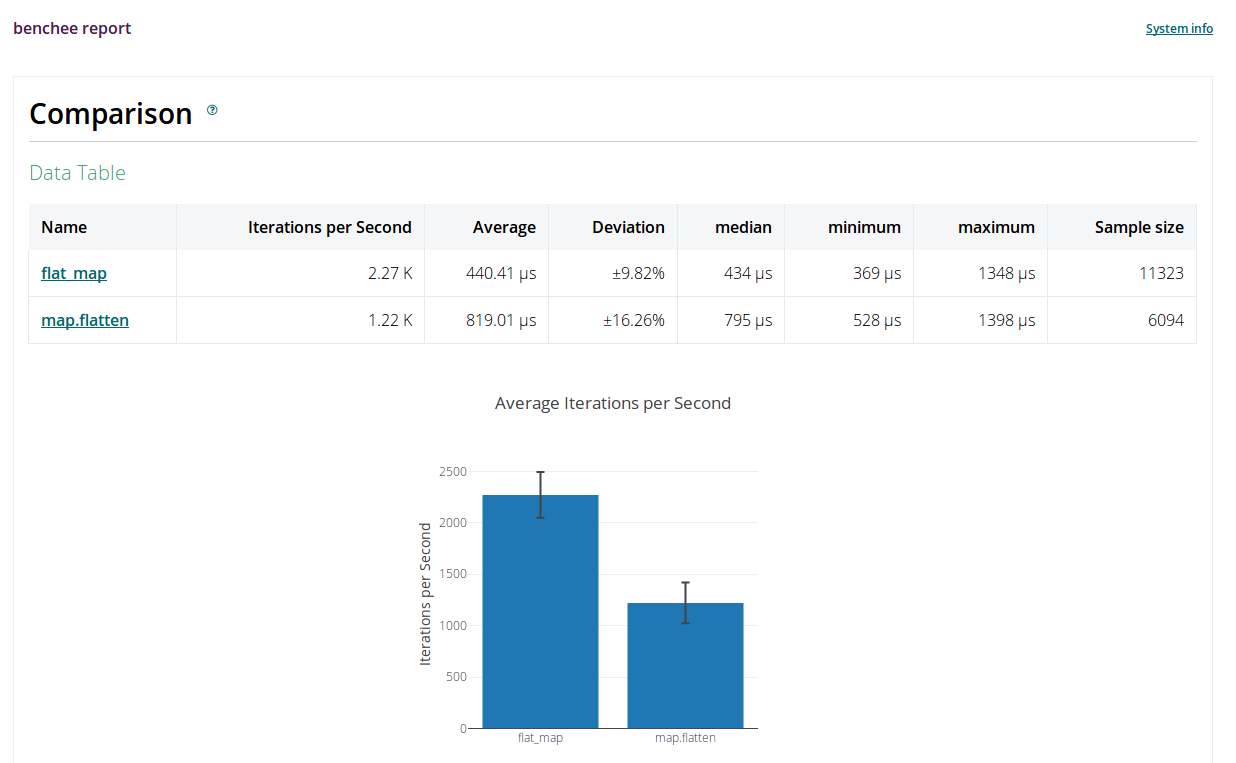
Table of Contents
- Table of Contents
- Features
- Installation
- Usage
- Known Issues
- Plugins
- Contributing
- Development
- Copyright and License
Features
- first runs the functions for a given warmup time without recording the results, to simulate a "warm"/running system
- measures memory usage
- provides you with lots of statistics
- plugin/extensible friendly architecture so you can use different formatters to display benchmarking results as HTML, markdown, JSON and more
- measure not only time, but also measure memory and reductions
- profile right after benchmarking
- as precise as it can get, measure with up to nanosecond precision (Operating System dependent)
- nicely formatted console output with units scaled to appropriately (nanoseconds to minutes)
- (optionally) measures the overhead of function calls so that the measured/reported times really are the execution time of your_code without that overhead.
- hooks to execute something before/after a benchmarking invocation, without it impacting the measured time
- execute benchmark jobs in parallel to gather more results in the same time, or simulate a system under load
- well documented & well tested
Statistics
Provides you with the following statistical data:
- average - average execution time/memory usage (the lower the better)
- ips - iterations per second, aka how often can the given function be executed within one second (the higher the better - good for graphing), only for run times
- deviation - standard deviation (how much do the results vary), given as a percentage of the average (raw absolute values also available)
- median - when all measured values are sorted, this is the middle value. More stable than the average and somewhat more likely to be a typical value you see, for the most typical value see mode. (the lower the better)
- 99th % - 99th percentile, 99% of all measured values are less than this - worst case performance-ish
In addition, you can optionally output an extended set of statistics:
- minimum - the smallest value measured for the job (fastest/least consumption)
- maximum - the biggest run time measured for the job (slowest/most consumption)
- sample size - the number of measurements taken
- mode - the measured values that occur the most. Often one value, but can be multiple values if they occur exactly as often. If no value occurs at least twice, this value will be
nil.
Installation
Add :benchee to your list of dependencies in mix.exs:
defp deps do
[
{:benchee, "~> 1.0", only: :dev}
]
end
Install via mix deps.get and then happy benchmarking as described in Usage :)
Elixir versions supported/tested against are 1.7+. It should theoretically still work with 1.4, 1.5 & 1.6 but we don't actively test/support it as installing them on current CI systems is not supported out of the box.
Usage
After installing just write a little Elixir benchmarking script:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(
%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
}
)
(names can also be specified as :atoms if you want to)
This produces the following output:
tobi@speedy:$ mix run samples/run_defaults.exs
Operating System: Linux
CPU Information: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Number of Available Cores: 8
Available memory: 15.61 GB
Elixir 1.8.1
Erlang 21.2.7
Benchmark suite executing with the following configuration:
warmup: 2 s
time: 5 s
memory time: 0 ns
parallel: 1
inputs: none specified
Estimated total run time: 14 s
Benchmarking flat_map...
Benchmarking map.flatten...
Name ips average deviation median 99th %
flat_map 2.34 K 427.78 μs ±16.02% 406.29 μs 743.01 μs
map.flatten 1.22 K 820.87 μs ±19.29% 772.61 μs 1286.35 μs
Comparison:
flat_map 2.34 K
map.flatten 1.22 K - 1.92x slower +393.09 μs
See Features for a description of the different statistical values and what they mean.
If you're looking to see how to make something specific work, please refer to the samples directory. Also, especially when wanting to extend Benchee, check out the hexdocs.
Configuration
Benchee takes a wealth of configuration options, however those are entirely optional. Benchee ships with sensible defaults for all of these.
In the most common Benchee.run/2 interface configuration options are passed as the second argument in the form of an keyword list:
Benchee.run(%{"some function" => fn -> magic end}, print: [benchmarking: false])
The available options are the following (also documented in hexdocs).
warmup- the time in seconds for which a benchmarking job should be run without measuring anything before "real" measurements start. This simulates a "warm"/running system. Defaults to 2.time- the time in seconds for how long each individual scenario (benchmarking job x input) should be run for measuring the execution times (run time performance). Defaults to 5.memory_time- the time in seconds for how long memory measurements should be conducted. Defaults to 0 (turned off).reduction_time- the time in seconds for how long reductions are measured should be conducted. Defaults to 0 (turned off).inputs- a map or list of two element tuples. If a map, the keys are descriptive input names and values are the actual input values. If a list of tuples, the first element in each tuple is the input name, and the second element in each tuple is the actual input value. Your benchmarking jobs will then be run with each of these inputs. For this to work your benchmarking function gets the current input passed in as an argument into the function. Defaults tonil, aka no input specified and functions are called without an argument. See Inputs.formatters- list of formatters either as a module implementing the formatter behaviour, a tuple of said module and options it should take or formatter functions. They are run when usingBenchee.run/2or you can invoke them throughBenchee.Formatter.output/1. Functions need to accept one argument (which is the benchmarking suite with all data) and then use that to produce output. Used for plugins & configuration. Also allows the configuration of the console formatter to print extended statistics. Defaults to the builtin console formatterBenchee.Formatters.Console. See Formatters.measure_function_call_overhead- Measure how long an empty function call takes and deduct this from each measured run time. This overhead should be negligible for all but the most micro benchmarks. Defaults to false.pre_check- whether or not to run each job with each input - including all given before or after scenario or each hooks - before the benchmarks are measured to ensure that your code executes without error. This can save time while developing your suites. Defaults tofalse.parallel- the function of each benchmarking job will be executed inparallelnumber processes. Ifparallel: 4then 4 processes will be spawned that all execute the same function for the given time. Whentimeseconds have passed, 4 new processes will be spawned for the next scenario (meaning a new input or another function to be benchmarked). This gives you more data in the same time, but also puts load on the system interfering with benchmark results. For more on the pros and cons of parallel benchmarking check the wiki. Defaults to 1 (no parallel execution).save- specify apathwhere to store the results of the current benchmarking suite, tagged with the specifiedtag. See Saving & Loading.load- load saved suite or suites to compare your current benchmarks against. Can be a string or a list of strings or patterns. See Saving & Loading.print- a map or keyword list from atoms totrueorfalseto configure if the output identified by the atom will be printed during the standard Benchee benchmarking process. All options are enabled by default (true). Options are::benchmarking- print when Benchee starts benchmarking a new job (Benchmarking name ...) as well as when statistics are being calculated or formatting begins.:configuration- a summary of configured benchmarking options including estimated total run time is printed before benchmarking starts:fast_warning- warnings are displayed if functions are executed too fast leading to inaccurate measures
:unit_scaling- the strategy for choosing a unit for durations, counts & memory measurements. May or may not be implemented by a given formatter (The console formatter implements it). When scaling a value, Benchee finds the "best fit" unit (the largest unit for which the result is at least 1). For example, 1_200_000 scales to1.2 M, while800_000scales to800 K. Theunit_scalingstrategy determines how Benchee chooses the best fit unit for an entire list of values, when the individual values in the list may have different best fit units. There are four strategies, defaulting to:best::best- the most frequent best fit unit will be used, a tie will result in the larger unit being selected.:largest- the largest best fit unit will be used:smallest- the smallest best fit unit will be used:none- no unit scaling will occur.
:before_scenario/after_scenario/before_each/after_each- read up on them in the hooks sectionprofile_after- accepts any of the following options:- a boolean -
truewill enable profiling with the default profiler (:eprof) andfalsewill disable profiling. Defaults tofalse. - a profiler - either as a tuple of
{profiler, opts}(e.g.,{:fprof, [sort: :own]}) or just the profiler (e.g.,:fprof), which is equivalent to{profiler, []}. The accepted built-in profilers are:cprof,:eprofand:fprof.
- a boolean -
Metrics to measure
Benchee can't only measure execution time, but also memory consumption and reductions!
You can measure one of these metrics, or all at the same time. The choice is up to you. Warmup will only occur once though, the time for measuring the metrics are governed by time, memory_time and reduction_time configuration values respectively.
By default only execution time is measured, memory and reductions need to be opted in by specifying a non 0 time amount.
Measuring time
This is the default, which you'll most likely want to use as you want to measure how fast your system processes something or responds to a request. Benchee does its best to measure time as accurately and as scoped to your function as possible.
Benchee.run(
%{
"something_great" => fn -> cool_stuff end
},
warmup: 1,
time: 5,
memory_time: 2,
reduction_time: 2
)
A note on time measurement accuracy
From system to system the resolution of the clock can vary.
Generally speaking we have seen accuracies down to 1 nanosecond on Linux and ~1 microsecond onb both OSX and Windows. We have also seen accuracy as low as 10ms on Windows in a CI environment. These numbers are not a limitation of Benchee, but of the Operating System (or at the very least how erlang makes it available).
If your benchmark takes 100s of microseconds this likely has no/little impact, but if you want to do extremely nano benchmarks we recommend doing them on Linux.
So, what happens if a function executes too fast for Benchee to measure? If Benchee recognizes this (not always possible) it will automatically take the function and repeat it multiple times. This way a function that takes 2 microseconds will take ~20 microseconds and differences can be measured even with microsecond accuracy. Naturally, this comes at several disadvantages:
- The looping/repetition code is now measured alongside the function
- essentially every single measurement is now an average across 10 runs making lots of statistics less meaningful
Benchee will print a big warning when this happens.
Measuring Memory Consumption
Starting with version 0.13, users can now get measurements of how much memory their benchmarked scenarios use. The measurement is limited to the process that Benchee executes your provided code in - i.e. other processes (like worker pools)/the whole BEAM isn't taken into account.
This measurement is not the actual effect on the size of the BEAM VM size, but the total amount of memory that was allocated during the execution of a given scenario. This includes all memory that was garbage collected during the execution of that scenario.
This measurement of memory does not affect the measurement of run times.
In cases where all measurements of memory consumption are identical, which happens very frequently, the full statistics will be omitted from the standard console formatter. If your function is deterministic, this should always be the case. Only in functions with some amount of randomness will there be variation in memory usage.
Memory measurement is disabled by default, you can choose to enable it by passing memory_time: your_seconds option to Benchee.run/2:
Benchee.run(
%{
"something_great" => fn -> cool_stuff end
},
memory_time: 2
)
Memory time can be specified separately as it will often be constant - so it might not need as much measuring time.
A full example, including an example of the console output, can be found here.
Measuring Reductions
Starting in versions 1.1.0 Benchee can measure reductions - but what are reductions?
In short, it's not very well defined but a "unit of work". The BEAM uses them to keep track of how long a process has run. As the Beam Book puts it as follows:
BEAM solves this by keeping track of how long a process has been running. This is done by counting reductions. The term originally comes from the mathematical term beta-reduction used in lambda calculus.
The definition of a reduction in BEAM is not very specific, but we can see it as a small piece of work, which shouldn’t take too long. Each function call is counted as a reduction. BEAM does a test upon entry to each function to check whether the process has used up all its reductions or not. If there are reductions left the function is executed otherwise the process is suspended.
Now, why would you want to measure this? Well, apart from BIFs & NIFs, which are not accurately tracked through this, it gives an impression of how much work the BEAM is doing. And the great thing is, this is independent of the load the system is under as well as the hardware. Hence, it gives you a way to check performance that is less volatile so suitable for CI for instance.
It can slightly differ between elixir & erlang versions, though.
Like memory measurements, this only tracks reductions directly in the function given to benchee, not processes spawned by it or other processes it uses.
Reduction measurement is disabled by default, you can choose to enable it by passing reduction_time: your_seconds option to Benchee.run/2:
Benchee.run(
%{
"something_great" => fn -> cool_stuff end
},
reduction_time: 2
)
Also like memory measurements, reduction measurements will often be constant unless something changes about the execution of the benchmarking function.
Inputs
:inputs is a very useful configuration that allows you to run the same benchmarking jobs with different inputs. We call this combination a "scenario". You specify the inputs as either a map from name (String or atom) to the actual input value or a list of tuples where the first element in each tuple is the name and the second element in the tuple is the value.
Why do this? Functions can have different performance characteristics on differently shaped inputs - be that structure or input size. One of such cases is comparing tail-recursive and body-recursive implementations of map. More information in the repository with the benchmark and the blog post.
As a little sample:
map_fun = fn i -> [i, i * i] end
Benchee.run(
%{
"flat_map" => fn input -> Enum.flat_map(input, map_fun) end,
"map.flatten" => fn input -> input |> Enum.map(map_fun) |> List.flatten() end
},
inputs: %{
"Small" => Enum.to_list(1..1_000),
"Medium" => Enum.to_list(1..10_000),
"Bigger" => Enum.to_list(1..100_000)
}
)
This means each function will be benchmarked with each input that is specified in the inputs. Then you'll get the output divided by input so you can see which function is fastest for which input, like so:
tobi@speedy:~/github/benchee(readme-overhaul)$ mix run samples/multiple_inputs.exs
(... general information ...)
##### With input Bigger #####
Name ips average deviation median 99th %
flat_map 150.81 6.63 ms ±12.65% 6.57 ms 8.74 ms
map.flatten 114.05 8.77 ms ±16.22% 8.42 ms 12.76 ms
Comparison:
flat_map 150.81
map.flatten 114.05 - 1.32x slower +2.14 ms
##### With input Medium #####
Name ips average deviation median 99th %
flat_map 2.28 K 437.80 μs ±10.72% 425.63 μs 725.09 μs
map.flatten 1.78 K 561.18 μs ±5.55% 553.98 μs 675.98 μs
Comparison:
flat_map 2.28 K
map.flatten 1.78 K - 1.28x slower +123.37 μs
##### With input Small #####
Name ips average deviation median 99th %
flat_map 26.31 K 38.01 μs ±15.47% 36.69 μs 67.08 μs
map.flatten 18.65 K 53.61 μs ±11.32% 52.79 μs 70.17 μs
Comparison:
flat_map 26.31 K
map.flatten 18.65 K - 1.41x slower +15.61 μs
Therefore, we highly recommend using this feature and checking different realistically structured and sized inputs for the functions you benchmark!
Formatters
Among all the configuration options, one that you probably want to use are the formatters. They format and print out the results of the benchmarking suite.
The :formatters option is specified a list of:
- modules implementing the
Benchee.Formatterbehaviour - a tuple of a module specified above and options for it
{module, options} - functions that take one argument (the benchmarking suite with all its results) and then do whatever you want them to
So if you are using the HTML plugin and you want to run both the console formatter and the HTML formatter this looks like this (after you installed it of course):
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(
%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten end
},
formatters: [
{Benchee.Formatters.HTML, file: "samples_output/my.html"},
Benchee.Formatters.Console
]
)
Console Formatter options
The console formatter supports 2 configuration options:
:comparison- if the comparison of the different benchmarking jobs (x times slower than) is shown. Enabled by default.extended_statistics- display more statistics, akaminimum,maximum,sample_sizeandmode. Disabled by default.
So if you want to see more statistics you simple pass extended_statistics: true to the console formatter:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(
%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
},
time: 10,
formatters: [{Benchee.Formatters.Console, extended_statistics: true}]
)
Which produces:
(... normal output ...)
Extended statistics:
Name minimum maximum sample size mode
flat_map 345.43 μs 1195.89 μs 23.73 K 405.64 μs
map.flatten 522.99 μs 2105.56 μs 12.03 K 767.83 μs, 768.44 μs
(Btw. notice how the modes of both are much closer and for map.flatten much less than the average of 766.99, see samples/run_extended_statistics)
Profiling after a run
Often time when benchmarking, you want to improve performance. However, Benchee only tells you how fast something is, it doesn't tell you what part of your code is slow. This is where profiling comes in.
Benchee offers you the profile_after option to run a profiler of your choice after a benchmarking run to see what's slow. This will run every scenario once.
By default it will run the :eprof profiler, different profilers with different options can be used - see configuration.
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
Benchee.run(
%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten() end
},
profile_after: true
)
After the normal benchmarking, this results prints profiles like:
Profiling flat_map with eprof...
Warmup...
Profile results of #PID<0.1885.0>
# CALLS % TIME µS/CALL
Total 30004 100.0 5665 0.19
Enum.flat_map/2 1 0.00 0 0.00
anonymous fn/2 in :elixir_compiler_1.__FILE__/1 1 0.00 0 0.00
:erlang.apply/2 1 0.04 2 2.00
:erlang.++/2 10000 18.38 1041 0.10
anonymous fn/1 in :elixir_compiler_1.__FILE__/1 10000 28.12 1593 0.16
Enum.flat_map_list/2 10001 53.47 3029 0.30
Profile done over 6 matching functions
Profiling map.flatten with eprof...
Warmup...
Profile results of #PID<0.1887.0>
# CALLS % TIME µS/CALL
Total 60007 100.0 8649 0.14
Enum.map/2 1 0.00 0 0.00
anonymous fn/2 in :elixir_compiler_1.__FILE__/1 1 0.00 0 0.00
List.flatten/1 1 0.00 0 0.00
:lists.flatten/1 1 0.00 0 0.00
:erlang.apply/2 1 0.02 2 2.00
anonymous fn/1 in :elixir_compiler_1.__FILE__/1 10000 16.35 1414 0.14
Enum."-map/2-lists^map/1-0-"/2 10001 26.38 2282 0.23
:lists.do_flatten/2 40001 57.24 4951 0.12
Note about after_each hooks: after_each hooks currently don't work when profiling a function, as they are not passed the return value of the function after the profiling run. It's already fixed on the elixir side and is waiting for release, likely in 1.14. It should then just work.
Saving, loading and comparing previous runs
Benchee can store the results of previous runs in a file and then load them again to compare them. For example this is useful to compare what was recorded on the main branch against a branch with performance improvements. You may also use this to benchmark across different exlixir/erlang versions.
Saving is done through the :save configuration option. You can specify a :path where results are saved, or you can use the default option of"benchmark.benchee" if you don't pass a :path. You can also pass a :tag option which annotates these results (for instance with a branch name or elixir version number). The default option for the :tag is a timestamp of when the benchmark was run.
Loading is done through the :load option specifying a path to the file to load (for instance "benchmark.benchee"). You can also specify multiple files to load through a list of paths (["my.benchee", "main_save.benchee"]) - each one of those can also be a glob expression to match even more files glob ("save_number*.benchee").
In the more verbose API loading is triggered via Benchee.load/1.
If all you want to do is to use :load without running any benchmarks then you can use Benchee.report/1 which will take a normal configuration with a :load key and just format the loaded saved results with the given formatters.
Benchee.run(
%{
"something_great" => fn -> cool_stuff end
},
save: [path: "save.benchee", tag: "first-try"]
)
Benchee.report(load: "save.benchee")
Hooks (Setup, Teardown etc.)
Most of the time, it's best to keep your benchmarks as simple as possible: plain old immutable functions work best. But sometimes you need other things to happen. When you want to add before or after hooks to your benchmarks, we've got you covered! Before you dig into this section though remember one thing: you usually don't need hooks!
Benchee has three types of hooks:
Of course, hooks are not included in the measurements. So they are there especially if you want to do something and want it to not be included in the measurements. Sadly there is the notable exception of too_fast_functions (the ones that execute faster than we can measure in native resolution). As we need to measure their repeated invocations to get halfway good measurements before_each and after_each hooks are included there. However, to the best of our knowledge this should only ever happen on Windows (because of the bad run time measurement accuracy).
Suite hooks
It is very easy in Benchee to do setup and teardown for the whole benchmarking suite (think: "before all" and "after all"). As Benchee is just plain old functions, just do your setup and teardown before/after you call Benchee:
your_setup()
Benchee.run(%{"Awesome stuff" => fn -> magic end})
your_teardown()
When might this be useful?
- Seeding the database with data to be used by all benchmarking functions
- Starting/shutting down a server, process, other dependencies
Scenario hooks
For the following discussions, it's important to know what benchee considers a "benchmarking scenario".
What is a scenario?
A scenario is the combination of one benchmarking function and one input. So, given this benchmark:
Benchee.run(
%{
"foo" => fn input -> ... end,
"bar" => fn input -> ... end
},
inputs: %{
"input 1" => 1,
"input 2" => 2
}
)
there are 4 scenarios:
- foo with input 1
- foo with input 2
- bar with input 1
- bar with input 2
A scenario includes warmup and actual run time (+ other measurements like memory).
before_scenario
Is executed before every scenario that it applies to (see hook configuration). before_scenario hooks take the input of the scenario as an argument.
Since the return value of a before_scenario becomes the input for next steps (see hook arguments and return values), there usually are 3 kinds of before scenarios:
- you just want to invoke a side effect: in that case return the given input unchanged
- you want to alter the given input: in that case alter the given input
- you want to keep the given input but add some other data: in that case return a tuple like
{original_input, new_fancy_data}
For before scenario hooks, the global hook is invoked first, then the local (see when does a hook happen?).
Usage:
Benchee.run(
%{
"foo" =>
{
fn {input, resource} -> foo(input, resource) end,
before_scenario: fn {input, resource} ->
resource = alter_resource(resource)
{input, resource}
end
},
"bar" =>
fn {input, resource} -> bar(input, resource) end
},
inputs: %{"input 1" => 1},
before_scenario: fn input ->
resource = start_expensive_resource()
{input, resource}
end
)
When might this be useful?
- Starting a process to be used in your scenario
- Recording the PID of
self()for use in your benchmark (each scenario is executed in its own process, so scenario PIDs aren't available in functions running before the suite) - Clearing the cache before a scenario
after_scenario
Is executed after a scenario has completed. After scenario hooks receive the return value of the last before_scenario that ran as an argument. The return value is discarded (see hook arguments and return values).
For after scenario hooks, the local hook is invoked first, then the global (see when does a hook happen?).
Usage:
Benchee.run(
%{
"bar" => fn -> bar() end
},
after_scenario: fn _input -> bust_my_cache() end
)
When might this be useful?
- Busting caches after a scenario completed
- Deleting all the records in the database that the scenario just created
- Terminating whatever was setup by
before_scenario
Benchmarking function hooks
You can also schedule hooks to run before and after each invocation of a benchmarking function.
before_each
Is executed before each invocation of the benchmarking function (before every measurement). Before each hooks receive the return value of their before_scenario hook as their argument. The return value of a before each hook becomes the input to the benchmarking function (see hook arguments and return values).
For before each hooks, the global hook is invoked first, then the local (see when does a hook happen?).
Usage:
Benchee.run(
%{
"bar" => fn record -> bar(record) end
},
inputs: %{ "record id" => 1},
before_each: fn input -> get_from_db(input) end
)
When might this be useful?
- Retrieving a record from the database and passing it on to the benchmarking function to do something(tm) without the retrieval from the database adding to the benchmark measurement
- Busting caches so that all measurements are taken in an uncached state
- Picking a random value from a collection and passing it to the benchmarking function for measuring performance with a wider spread of values
- you could also use this to benchmark with random data like
StreamData, devon shows how it's done here
after_each
Is executed directly after the invocation of the benchmarking function. After each hooks receive the return value of the benchmarking function as their argument. The return value is discarded (see hook arguments and return values).
For after each hooks, the local hook is invoked first, then the global (see when does a hook happen?).
Usage:
Benchee.run(
%{
"bar" => fn input -> bar(input) end
},
inputs: %{ "input 1" => 1},
after_each: fn result -> assert result == 42 end
)
When might this be useful?
- Running assertions that whatever your benchmarking function returns is truly what it should be (i.e. all "contestants" work as expected)
- Busting caches/terminating processes setup in
before_eachor elsewhere - Deleting files created by the benchmarking function
Hook arguments and return values
Before hooks form a chain, where the return value of the previous hook becomes the argument for the next one. The first defined before hook receives the scenario input as an argument, and returns a value that becomes the argument of the next in the chain. The benchmarking function receives the value of the last before hook as its argument (or the scenario input if there are no before hooks).
After hooks do not form a chain, and their return values are discarded. An after_each hook receives the return value of the benchmarking function as its argument. An after_scenario function receives the return value of the last before_scenario that ran (or the scenario's input if there is no before_scenario hook).
If you haven't defined any inputs, the hook chain is started with the special input argument returned by Benchee.Benchmark.no_input().
Hook configuration: global versus local
Hooks can be defined either globally as part of the configuration or locally for a specific benchmarking function. Global hooks will be executed for every scenario in the suite. Local hooks will only be executed for scenarios involving that benchmarking function.
Global hooks
Global hooks are specified as part of the general benchee configuration:
Benchee.run(
%{
"foo" => fn input -> ... end,
"bar" => fn input -> ... end
},
inputs: %{
"input 1" => 1,
"input 2" => 2,
},
before_scenario: fn input -> ... end
)
Here the before_scenario function will be executed for all 4 scenarios present in this benchmarking suite.
Local hooks
Local hooks are defined alongside the benchmarking function. To define a local hook, pass a tuple in the initial map, instead of just a single function. The benchmarking function comes first, followed by a keyword list specifying the hooks to run:
Benchee.run(
%{
"foo" => {fn input -> ... end, before_scenario: fn input -> ... end},
"bar" => fn input -> ... end
},
inputs: %{
"input 1" => 1,
"input 2" => 2
}
)
Here before_scenario is only run for the 2 scenarios associated with "foo", i.e. foo with input 1 and foo with input 2. It is not run for any "bar" benchmarks.
When does a hook happen? (Complete Example)
Yes the whole hooks system is quite a lot to take in. Here is an overview showing the order of hook execution, along with the argument each hook receives (see hook arguments and return values). The guiding principle whether local or global is run first is that local always executes closer to the benchmarking function.
Given the following code:
suite_set_up()
Benchee.run(
%{
"foo" =>
{
fn input -> foo(input) end,
before_scenario: fn input ->
local_before_scenario(input)
input + 1
end,
before_each: fn input ->
local_before_each(input)
input + 1
end,
after_each: fn value ->
local_after_each(value)
end,
after_scenario: fn input ->
local_after_scenario(input)
end
},
"bar" =>
fn input -> bar(input) end
},
inputs: %{"input 1" => 1},
before_scenario: fn input ->
global_before_scenario(input)
input + 1
end,
before_each: fn input ->
global_before_each(input)
input + 1
end,
after_each: fn value ->
global_after_each(value)
end,
after_scenario: fn input ->
global_after_scenario(input)
end
)
suite_tear_down()
Keeping in mind that the order of foo and bar could be different, here is how the hooks are called:
suite_set_up
# starting with the foo scenario
global_before_scenario(1)
local_before_scenario(2) # as before_scenario incremented it
global_before_each(3)
local_before_each(4)
foo(5) # let's say foo(5) returns 6
local_after_each(6)
global_after_each(6)
global_before_each(3)
local_before_each(4)
foo(5) # let's say foo(5) returns 6
local_after_each(6)
global_after_each(6)
# ... this block is repeated as many times as benchee has time
local_after_scenario(3)
global_after_scenario(3)
# now it's time for the bar scenario, it has no hooks specified for itself
# so only the global hooks are run
global_before_scenario(1)
global_before_each(2)
bar(3) # let's say foo(3) returns 4
global_after_each(4)
global_before_each(2)
bar(3) # let's say foo(3) returns 4
global_after_each(4)
# ... this block is repeated as many times as benchee has time
global_after_scenario(2)
suite_tear_down
More verbose usage
It is important to note that the benchmarking code shown in the beginning is the convenience interface. The same benchmark in its more verbose form looks like this:
list = Enum.to_list(1..10_000)
map_fun = fn i -> [i, i * i] end
[time: 3]
|> Benchee.init()
|> Benchee.system()
|> Benchee.benchmark("flat_map", fn -> Enum.flat_map(list, map_fun) end)
|> Benchee.benchmark(
"map.flatten",
fn -> list |> Enum.map(map_fun) |> List.flatten() end
)
|> Benchee.collect()
|> Benchee.statistics()
|> Benchee.relative_statistics()
|> Benchee.Formatter.output(Benchee.Formatters.Console)
# Instead of the last call you could also just use Benchee.Formatter.output()
# to just output all configured formatters
This is a take on the functional transformation of data applied to benchmarks:
- Configure the benchmarking suite to be run
- Gather System data
- Define the functions to be benchmarked
- Run benchmarks with the given configuration gathering raw run times per function
- Calculate statistics based on the raw run times
- Calculate statistics between the scenarios (faster/slower...)
- Format the statistics in a suitable way and print them out
This is also part of the official API and allows for more fine grained control. (It's also what Benchee does internally when you use Benchee.run/2).
Do you just want to have all the raw run times? Just work with the result of Benchee.collect/1! Just want to have the calculated statistics and use your own formatting? Grab the result of Benchee.statistics/1! Or, maybe you want to write to a file or send an HTTP post to some online service? Just grab the complete suite after statistics were generated.
It also allows you to alter behaviour, normally Benchee.load/1 is called right before the formatters so that neither the benchmarks are run again or statistics are computed again. However, you might want to run the benchmarks again or recompute the statistics. Then you can call Benchee.load/1 right at the start.
This way Benchee should be flexible enough to suit your needs and be extended at will. Have a look at the available plugins.
Usage from Erlang
Before you dig deep into this, it is inherently easier to setup a small elixir project, add a dependency to your erlang project and then run the benchmarks from elixir. The reason is easy - mix knows about rebar3 and knows how to work with it. The reverse isn't true so the road ahead is somewhat bumpy.
There is an example project to check out.
You can use the rebar3_elixir_compile plugin. In your rebar.config you can do the following which should get you started:
deps, [
{benchee, {elixir, "benchee", "0.9.0"}}
]}.
{plugins, [
{ rebar3_elixir_compile, ".*", {git, "https://github.com/barrel-db/rebar3_elixir_compile.git", {branch, "main"}}}
]}.
{provider_hooks, [
{pre, [{compile, {ex, compile}}]},
{pre, [{release, {ex, compile}}]}
]}.
{elixir_opts,
[
{env, dev}
]
}.
Then benchee already provides a :benchee interface for erlang compatibility which you can use. Sadly couldn't get it to work in an escript yet.
You can then invoke it like this (for instance):
tobi@comfy ~/github/benchee_erlang_try $ rebar3 shell
===> dependencies etc.
Erlang/OTP 18 [erts-7.3] [source] [64-bit] [smp:4:4] [async-threads:0] [hipe] [kernel-poll:false]
Eshell V7.3 (abort with ^G)
1> benchee:run(#{myFunc => fun() -> lists:sort([8, 2, 3, 4, 2, 1, 3, 4, 9, 10, 11, 12, 13, 20, 1000, -4, -5]) end}, [{warmup, 0}, {time, 2}]).
Operating System: Linux
CPU Information: Intel(R) Core(TM) i5-7200U CPU @ 2.50GHz
Number of Available Cores: 4
Available memory: 8.05 GB
Elixir 1.3.4
Erlang 18.3
Benchmark suite executing with the following configuration:
warmup: 0.0 μs
time: 2 s
parallel: 1
inputs: none specified
Estimated total run time: 2 s
Benchmarking myFunc...
Name ips average deviation median
myFunc 289.71 K 3.45 μs ±250.31% 3 μs
This doesn't seem to be too reliable right now, so suggestions and input are very welcome :)
Known Issues
There is a known issue affecting elixir versions from 1.14.0 to 1.16.0-rc.0: Optimizations (SSA and bool passes, see the original change) had been disabled affecting the performance of functions defined directly in the top level (i.e. outside of any module). The issue was fixed by re-enabling the optimization in 1.16.0-rc.1. The issue is best show-cased by the following benchmark where we'd expect ~equal results:
list = Enum.to_list(1..10_000)
defmodule Compiled do
def comprehension(list) do
for x <- list, rem(x, 2) == 1, do: x + 1
end
end
Benchee.run(%{
"module (optimized)" => fn -> Compiled.comprehension(list) end,
"top_level (non-optimized)" => fn -> for x <- list, rem(x, 2) == 1, do: x + 1 end
})
Which yields ~these results on an affected elixir version:
Comparison:
module (optimized) 18.24 K
top_level (non-optimized) 11.91 K - 1.53x slower +29.14 μs
So, how do you fix it/make sure a benchmark you ran is not affected? All of these work:
- benchmark on an unaffected/fixed version of elixir (<= 1.13.4 or >= 1.16.0-rc.1)
- put the code you want to benchmark into a module (just like it is done in
Compiledin the example above) - you can also invoke benchee from within a module, such as:
defmodule Compiled do
def comprehension(list) do
for x <- list, rem(x, 2) == 1, do: x + 1
end
end
defmodule MyBenchmark do
def run do
list = Enum.to_list(1..10_000)
Benchee.run(%{
"module (optimized)" => fn -> Compiled.comprehension(list) end,
"top_level (non-optimized)" => fn -> for x <- list, rem(x, 2) == 1, do: x + 1 end
})
end
end
MyBenchmark.run()
Also note that even if all your examples are top level functions you should still follow these tips (on affected elixir versions), as the missing optimization might affect them differently. Further note, that even though your examples use top level functions they may not be affected, as the specific disabled optimization may not impact them. Better safe than sorry though :)
Plugins
Benchee only has small runtime dependencies that were initially extracted from it. Further functionality is provided through plugins that then pull in dependencies, such as HTML generation and CSV export. They help provide excellent visualization or interoperability.
- benchee_html - generate HTML including a data table and many different graphs with the possibility to export individual graphs as PNG :)
- benchee_csv - generate CSV from your benchee benchmark results so you can import them into your favorite spreadsheet tool and make fancy graphs
- benchee_json - export suite results as JSON to feed anywhere or feed it to your JavaScript and make magic happen :)
- benchee_markdown - write markdown files containing your benchmarking results
With the HTML plugin for instance you can get fancy graphs like this boxplot:
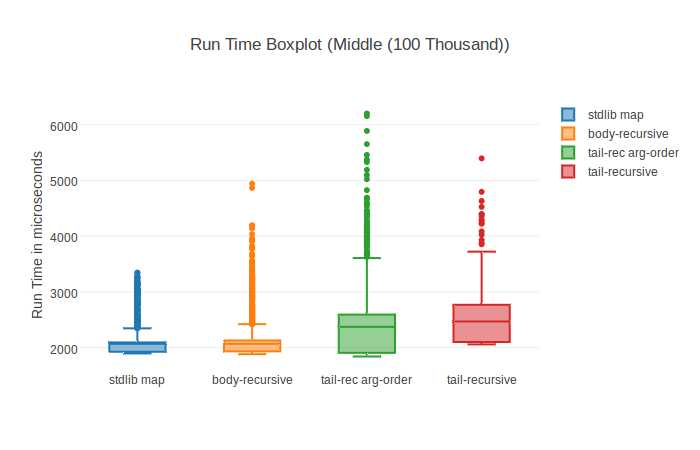
Of course there also are normal bar charts including standard deviation:
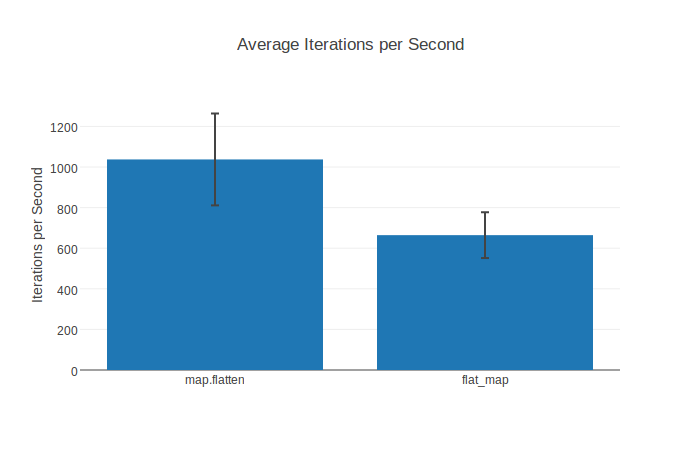
Contributing 
Contributions to Benchee are very welcome! Bug reports, documentation, spelling corrections, whole features, feature ideas, bugfixes, new plugins, fancy graphics... all of those (and probably more) are much appreciated contributions!
Keep in mind that the plugins live in their own repositories with their own issue tracker and they also like to get contributions :)
Please respect the Code of Conduct.
In addition to contributing code, you can help to triage issues. This can include reproducing bug reports, or asking for vital information such as version numbers or reproduction instructions. If you would like to start triaging issues, one easy way to get started is to subscribe to pragtob/benchee on CodeTriage.
You can also look directly at the open issues. There are help wanted and good first issue labels - those are meant as guidance, of course other issues can be tackled :)
A couple of (hopefully) helpful points:
- Feel free to ask for help and guidance on an issue/PR ("How can I implement this?", "How could I test this?", ...)
- Feel free to open early/not yet complete pull requests to get some early feedback
- When in doubt if something is a good idea open an issue first to discuss it
- In case I don't respond feel free to bump the issue/PR or ping me in other places
If you're on the elixir-lang slack also feel free to drop by in #benchee and say hi!
Development
Note that if the change includes adding new statistics you might need to introduce them to our statistics library Statistex first!
mix deps.getto install dependenciesmix testto run testsmix dialyzerto run dialyzer for type checking, might take a while on the first invocation (try building plts first withmix dialyzer --plt)mix credoto find code style problems- or run
mix guardto run all of them continuously on file change
Copyright and License
Copyright (c) 2016 Tobias Pfeiffer
This work is free. You can redistribute it and/or modify it under the terms of the MIT License. See the LICENSE.md file for more details.
Articlesto learn more about the elixir concepts.
- 1Getting Started with Elixir for Modern Applications
- 2Functional Programming in Elixir: Immutability and Higher-Order Functions
- 3Building Web Applications with Phoenix Framework
- 4Building Real-Time Web Apps with Phoenix Channels
- 5Concurrency in Elixir
- 6Building Fault-Tolerant Systems with Elixir and OTP
- 7Building Distributed Systems in Elixir with Clustering and Node Communication
- 8Handling Real-Time Data Streams in Elixir with GenStage
- 9Elixir Macros on Metaprogramming for Clean, Reusable Code
- 10Optimizing Elixir Applications for Performance and Scalability
Resourceswhich are currently available to browse on.
mail [email protected] to add your project or resources here 🔥.
- 1A Cloud at the lowest level
http://cloudi.org/CloudI is an open-source private cloud computing framework for efficient, secure, and internal data processing. CloudI provides scaling for previously unscalable source code with efficient fault-tolerant execution of ATS, C/C++, Erlang/Elixir, Go, Haskell, Java, JavaScript/node.js, OCaml, Perl, PHP, Python, Ruby, or Rust services. The bare essentials for efficient fault-tolerant processing on a cloud! - 2data_morph
https://hex.pm/packages/data_morphCreate Elixir structs, maps with atom keys, and keyword lists from CSV/TSV data. - 3ueberauth_auth0
https://hex.pm/packages/ueberauth_auth0An Ueberauth strategy for using Auth0 to authenticate your users. - 4Stuart Hunt / Neat-Ex · GitLab
https://gitlab.com/onnoowl/Neat-ExAn Elixir implementation of the NEAT algorithm, as described here. - 5GT8 Online / Open Source / Elixir / Weave · GitLab
https://gitlab.com/gt8/open-source/elixir/weaveA JIT Configuration Loader for Elixir - 6Luhn algorithm in Elixir
https://github.com/ma2gedev/luhn_exLuhn algorithm in Elixir. Contribute to ma2gedev/luhn_ex development by creating an account on GitHub. - 7Elixir implementation of Simhash
https://github.com/UniversalAvenue/simhash-exElixir implementation of Simhash. Contribute to UniversalAvenue/simhash-ex development by creating an account on GitHub. - 8Elixir implementation of CLOPE: A Fast and Effective Clustering Algorithm for Transactional Data
https://github.com/ayrat555/clopeElixir implementation of CLOPE: A Fast and Effective Clustering Algorithm for Transactional Data - ayrat555/clope - 9A consistent hash ring implemention for Elixir
https://github.com/reset/hash-ring-exA consistent hash ring implemention for Elixir. Contribute to reset/hash-ring-ex development by creating an account on GitHub. - 10Implementations of popular data structures and algorithms
https://github.com/aggelgian/erlang-algorithmsImplementations of popular data structures and algorithms - aggelgian/erlang-algorithms - 11An Elixir implementation of the Supermemo 2 algorithm
https://github.com/edubkendo/supermemoAn Elixir implementation of the Supermemo 2 algorithm - edubkendo/supermemo - 12An Elixir API wrapper for the Fleet REST API
https://github.com/jordan0day/fleet-apiAn Elixir API wrapper for the Fleet REST API. Contribute to jordan0day/fleet-api development by creating an account on GitHub. - 13Kubernetes API client for Elixir
https://github.com/obmarg/kazanKubernetes API client for Elixir. Contribute to obmarg/kazan development by creating an account on GitHub. - 14A small and user-friendly ETS wrapper for caching in Elixir
https://github.com/whitfin/stashA small and user-friendly ETS wrapper for caching in Elixir - whitfin/stash - 15(Not maintaining) A Slack-like app by Elixir, Phoenix & React(redux)
https://github.com/tony612/exchat(Not maintaining) A Slack-like app by Elixir, Phoenix & React(redux) - tony612/exchat - 16elementtui
https://codeberg.org/edwinvanl/elementtuiElementTui: an Elixir library to create terminal user interfaces (tui). - 17Rational number library for Elixir.
https://github.com/Qqwy/elixir-rationalRational number library for Elixir. Contribute to Qqwy/elixir-rational development by creating an account on GitHub. - 18Elixir app to serve Dragonfly images
https://github.com/cloud8421/dragonfly-serverElixir app to serve Dragonfly images. Contribute to cloud8421/dragonfly-server development by creating an account on GitHub. - 19LZ4 bindings for Erlang
https://github.com/szktty/erlang-lz4LZ4 bindings for Erlang. Contribute to szktty/erlang-lz4 development by creating an account on GitHub. - 20Variadic aritity tree with a zipper for Elixir!
https://github.com/Dkendal/zipper_treeVariadic aritity tree with a zipper for Elixir! Contribute to Dkendal/zipper_tree development by creating an account on GitHub. - 21:sparkles: A simple, clueless bot
https://github.com/techgaun/ex_mustang:sparkles: A simple, clueless bot. Contribute to techgaun/ex_mustang development by creating an account on GitHub. - 22State machine pattern for Ecto
https://github.com/asiniy/ecto_state_machineState machine pattern for Ecto. Contribute to asiniy/ecto_state_machine development by creating an account on GitHub. - 23Elixir implementation of a binary Galois LFSR
https://github.com/pma/lfsrElixir implementation of a binary Galois LFSR. Contribute to pma/lfsr development by creating an account on GitHub. - 24String metrics and phonetic algorithms for Elixir (e.g. Dice/Sorensen, Hamming, Jaccard, Jaro, Jaro-Winkler, Levenshtein, Metaphone, N-Gram, NYSIIS, Overlap, Ratcliff/Obershelp, Refined NYSIIS, Refined Soundex, Soundex, Weighted Levenshtein)
https://github.com/smashedtoatoms/the_fuzzString metrics and phonetic algorithms for Elixir (e.g. Dice/Sorensen, Hamming, Jaccard, Jaro, Jaro-Winkler, Levenshtein, Metaphone, N-Gram, NYSIIS, Overlap, Ratcliff/Obershelp, Refined NYSIIS, Ref... - 25A cron-style scheduler application for Elixir.
https://github.com/ausimian/timelierA cron-style scheduler application for Elixir. Contribute to ausimian/timelier development by creating an account on GitHub. - 26Extension of the Elixir standard library focused on data stuctures, data manipulation and performance
https://github.com/sabiwara/ajaExtension of the Elixir standard library focused on data stuctures, data manipulation and performance - sabiwara/aja - 27Spawn - Actor Mesh
https://github.com/eigr/spawnSpawn - Actor Mesh. Contribute to eigr/spawn development by creating an account on GitHub. - 28A multi-protocol network services monitor written in Elixir using Poolboy.
https://github.com/tchoutri/NvjornA multi-protocol network services monitor written in Elixir using Poolboy. - tchoutri/Nvjorn - 29Pure Elixir implementation of Fowler–Noll–Vo hash functions
https://github.com/asaaki/fnv.exPure Elixir implementation of Fowler–Noll–Vo hash functions - asaaki/fnv.ex - 30A playground for data structures in Elixir
https://github.com/hamiltop/structurezA playground for data structures in Elixir. Contribute to hamiltop/structurez development by creating an account on GitHub. - 31DefMemo - Ryuk's little puppy! Bring apples.
https://github.com/os6sense/DefMemoDefMemo - Ryuk's little puppy! Bring apples. Contribute to os6sense/DefMemo development by creating an account on GitHub. - 32💬 CHAT: Instant Messenger. ISO/IEC: 20922; ITU/IETF: 3394, 3565, 5280, 5480, 5652, 5755 8551, X.509, CMS, PKCS-10, PCKS-7, OCSP, LDAP, DNS; ANSI: X9-42, X9-62, X25519, X488; NIST: SECP384r1.
https://github.com/synrc/chat💬 CHAT: Instant Messenger. ISO/IEC: 20922; ITU/IETF: 3394, 3565, 5280, 5480, 5652, 5755 8551, X.509, CMS, PKCS-10, PCKS-7, OCSP, LDAP, DNS; ANSI: X9-42, X9-62, X25519, X488; NIST: SECP384r1. - synr... - 33An Elixir implementation of generic n-ary tree data structure
https://github.com/medhiwidjaja/nary_treeAn Elixir implementation of generic n-ary tree data structure - medhiwidjaja/nary_tree - 34Jump consistent hash implementation in Elixir (without NIFs)
https://github.com/whitfin/jumperJump consistent hash implementation in Elixir (without NIFs) - whitfin/jumper - 35Collision-resistant ids, in Elixir
https://github.com/duailibe/cuidCollision-resistant ids, in Elixir. Contribute to duailibe/cuid development by creating an account on GitHub. - 36arianvp/elixir-isaac
https://github.com/arianvp/elixir-isaacContribute to arianvp/elixir-isaac development by creating an account on GitHub. - 37Elixir library implementing complex numbers and math.
https://github.com/q60/complexElixir library implementing complex numbers and math. - q60/complex - 38Thin layer on top of Cryptex for more easily encrypting/decrypting, signing/verifying data in elixir
https://github.com/stocks29/ezcryptexThin layer on top of Cryptex for more easily encrypting/decrypting, signing/verifying data in elixir - stocks29/ezcryptex - 39A blocking queue written in Elixir.
https://github.com/joekain/BlockingQueueA blocking queue written in Elixir. Contribute to joekain/BlockingQueue development by creating an account on GitHub. - 40An Elixir library for generating struct constructors that handle external data with ease.
https://github.com/appcues/exconstructorAn Elixir library for generating struct constructors that handle external data with ease. - appcues/exconstructor - 41Datastructures for Elixir.
https://github.com/meh/elixir-datastructuresDatastructures for Elixir. Contribute to meh/elixir-datastructures development by creating an account on GitHub. - 42Metric stream related math functions.
https://github.com/dalmatinerdb/mmathMetric stream related math functions. Contribute to dalmatinerdb/mmath development by creating an account on GitHub. - 43A CSV reading/writing application for Elixir.
https://github.com/jimm/csvlixirA CSV reading/writing application for Elixir. Contribute to jimm/csvlixir development by creating an account on GitHub. - 44Fast HyperLogLog implementation for Elixir/Erlang
https://github.com/whitfin/hypexFast HyperLogLog implementation for Elixir/Erlang. Contribute to whitfin/hypex development by creating an account on GitHub. - 45Rotor plugin to compile CoffeeScript files
https://github.com/HashNuke/coffee_rotorRotor plugin to compile CoffeeScript files. Contribute to HashNuke/coffee_rotor development by creating an account on GitHub. - 46Plugin for compiling ASN.1 modules with Rebar3.
https://github.com/pyykkis/rebar3_asn1_compilerPlugin for compiling ASN.1 modules with Rebar3. Contribute to pyykkis/rebar3_asn1_compiler development by creating an account on GitHub. - 47Environmental variables manager based on Figaro for Elixir projects
https://github.com/KamilLelonek/figaro-elixirEnvironmental variables manager based on Figaro for Elixir projects - KamilLelonek/figaro-elixir - 48BEAM friendly spinlocks for Elixir/Erlang
https://github.com/whitfin/sleeplocksBEAM friendly spinlocks for Elixir/Erlang. Contribute to whitfin/sleeplocks development by creating an account on GitHub. - 49Library to manage OS environment variables and application configuration options with ease
https://github.com/gmtprime/skogsraLibrary to manage OS environment variables and application configuration options with ease - gmtprime/skogsra - 50Compile Diameter .dia files on Erlang Rebar3 projects
https://github.com/carlosedp/rebar3_diameter_compilerCompile Diameter .dia files on Erlang Rebar3 projects - carlosedp/rebar3_diameter_compiler - 51Tree structure & hierarchy for ecto models
https://github.com/asiniy/ecto_materialized_pathTree structure & hierarchy for ecto models. Contribute to asiniy/ecto_materialized_path development by creating an account on GitHub. - 52Elixir library implementing a parallel matrix multiplication algorithm and other utilities for working with matrices. Used for benchmarking computationally intensive concurrent code.
https://github.com/a115/exmatrixElixir library implementing a parallel matrix multiplication algorithm and other utilities for working with matrices. Used for benchmarking computationally intensive concurrent code. - GitHub - a1... - 53Queue data structure for Elixir-lang
https://github.com/princemaple/elixir-queueQueue data structure for Elixir-lang. Contribute to princemaple/elixir-queue development by creating an account on GitHub. - 54The AES-CMAC Algorithm
https://tools.ietf.org/html/rfc4493The National Institute of Standards and Technology (NIST) has recently specified the Cipher-based Message Authentication Code (CMAC), which is equivalent to the One-Key CBC MAC1 (OMAC1) submitted by Iwata and Kurosawa. This memo specifies an authentication algorithm based on CMAC with the 128-bit Advanced Encryption Standard (AES). This new authentication algorithm is named AES-CMAC. The purpose of this document is to make the AES-CMAC algorithm conveniently available to the Internet Community. This memo provides information for the Internet community. - 55An Elixir implementation of the CONREC algorithm for topographic or isochrone maps.
https://github.com/NAISorg/conrexAn Elixir implementation of the CONREC algorithm for topographic or isochrone maps. - NAISorg/conrex - 56Pusher server implementation compatible with Pusher client libraries.
https://github.com/edgurgel/poxaPusher server implementation compatible with Pusher client libraries. - edgurgel/poxa - 57Medical Examination - application for register health check callbacks and represent their state via HTTP.
https://github.com/xerions/medexMedical Examination - application for register health check callbacks and represent their state via HTTP. - xerions/medex - 58:bird: Cuckoo Filters in Elixir
https://github.com/gmcabrita/cuckoo:bird: Cuckoo Filters in Elixir. Contribute to gmcabrita/cuckoo development by creating an account on GitHub. - 59Extension of Enum functions like min_by, max_by, min_max_by, returning a list of results instead of just one.
https://github.com/seantanly/elixir-minmaxlistExtension of Enum functions like min_by, max_by, min_max_by, returning a list of results instead of just one. - seantanly/elixir-minmaxlist - 60Telegram Bot API low level API and framework
https://github.com/rockneurotiko/ex_gramTelegram Bot API low level API and framework. Contribute to rockneurotiko/ex_gram development by creating an account on GitHub. - 61Consolex is a tool that allows you to attach a web based console to any mix project
https://github.com/sivsushruth/consolexConsolex is a tool that allows you to attach a web based console to any mix project - sivsushruth/consolex - 62Enterprise Kubernetes management, accelerated. 🚀
https://github.com/pluralsh/pluralEnterprise Kubernetes management, accelerated. 🚀. Contribute to pluralsh/plural development by creating an account on GitHub. - 63Deque implementations in elixir
https://github.com/stocks29/dlistDeque implementations in elixir. Contribute to stocks29/dlist development by creating an account on GitHub. - 64stream count distinct element estimation
https://github.com/rozap/spacesavingstream count distinct element estimation. Contribute to rozap/spacesaving development by creating an account on GitHub. - 65Erlang Trie Implementation
https://github.com/okeuday/trieErlang Trie Implementation. Contribute to okeuday/trie development by creating an account on GitHub. - 66A task graph execution library for elixir
https://github.com/stocks29/graphexA task graph execution library for elixir. Contribute to stocks29/graphex development by creating an account on GitHub. - 67Implementation of the Rendezvous or Highest Random Weight (HRW) hashing algorithm in the Elixir Programming Language
https://github.com/timdeputter/RendezvousImplementation of the Rendezvous or Highest Random Weight (HRW) hashing algorithm in the Elixir Programming Language - timdeputter/Rendezvous - 68Mason uses superpowers to coerce maps into structs. This is helpful e.g. when you interface a REST API and want to create a struct from the response.
https://github.com/spacepilots/masonMason uses superpowers to coerce maps into structs. This is helpful e.g. when you interface a REST API and want to create a struct from the response. - spacepilots/mason - 69The Good Old game, built with Elixir, Phoenix, React and Redux
https://github.com/bigardone/phoenix-battleshipThe Good Old game, built with Elixir, Phoenix, React and Redux - bigardone/phoenix-battleship - 70Elixir library providing some handy parallel processing facilities that supports configuring number of workers and timeout.
https://github.com/seantanly/elixir-paratizeElixir library providing some handy parallel processing facilities that supports configuring number of workers and timeout. - seantanly/elixir-paratize - 71Open source API gateway with integrated cache and data transformations.
https://github.com/doomspork/hydraOpen source API gateway with integrated cache and data transformations. - doomspork/hydra - 72Elixir wrapper around OTP's gen_fsm
https://github.com/pavlos/gen_fsmElixir wrapper around OTP's gen_fsm. Contribute to pavlos/gen_fsm development by creating an account on GitHub. - 73A Tiny Encryption Algorithm implementation
https://github.com/keichan34/tea_crypto_erlA Tiny Encryption Algorithm implementation. Contribute to keichan34/tea_crypto_erl development by creating an account on GitHub. - 74buffer a large set of counters and flush periodically
https://github.com/camshaft/count_bufferbuffer a large set of counters and flush periodically - camshaft/count_buffer - 75Erlang 2-way map
https://github.com/okeuday/key2valueErlang 2-way map. Contribute to okeuday/key2value development by creating an account on GitHub. - 76Closure Table for Elixir - a simple solution for storing and manipulating complex hierarchies.
https://github.com/florinpatrascu/closure_tableClosure Table for Elixir - a simple solution for storing and manipulating complex hierarchies. - florinpatrascu/closure_table - 77:speech_balloon: An implementation of the non-cryptographic hash Murmur3
https://github.com/gmcabrita/murmur:speech_balloon: An implementation of the non-cryptographic hash Murmur3 - gmcabrita/murmur - 78Basic IRC client for writing bots
https://github.com/alco/chattyBasic IRC client for writing bots. Contribute to alco/chatty development by creating an account on GitHub. - 79Multi-dimensional arrays (tensors) and numerical definitions for Elixir
https://github.com/elixir-nx/nxMulti-dimensional arrays (tensors) and numerical definitions for Elixir - elixir-nx/nx - 80Not actively maintained - Authentication library for Phoenix, and other Plug-based, web applications
https://github.com/riverrun/phauxthNot actively maintained - Authentication library for Phoenix, and other Plug-based, web applications - riverrun/phauxth - 81Elixir library implementing rational numbers and math.
https://github.com/q60/rationalElixir library implementing rational numbers and math. - q60/rational - 82This software is no longer maintained. For archive/reference use only. -- Tiny Mersenne Twister (TinyMT) for Erlang
https://github.com/jj1bdx/tinymt-erlang/This software is no longer maintained. For archive/reference use only. -- Tiny Mersenne Twister (TinyMT) for Erlang - jj1bdx/tinymt-erlang - 83A parallelized stream implementation for Elixir
https://github.com/beatrichartz/parallel_streamA parallelized stream implementation for Elixir. Contribute to beatrichartz/parallel_stream development by creating an account on GitHub. - 84A latency / fault tolerance library to help isolate your applications from an uncertain world of slow or failed services.
https://github.com/tobz/elistrixA latency / fault tolerance library to help isolate your applications from an uncertain world of slow or failed services. - tobz/elistrix - 85sfmt-erlang: SIMD-oriented Fast Mersenne Twister (SFMT) for Erlang
https://github.com/jj1bdx/sfmt-erlang/sfmt-erlang: SIMD-oriented Fast Mersenne Twister (SFMT) for Erlang - jj1bdx/sfmt-erlang - 86A simple combinatorics library providing combination and permutation.
https://github.com/seantanly/elixir-combinationA simple combinatorics library providing combination and permutation. - seantanly/elixir-combination - 87An Elixir wrapper library for Erlang's array
https://github.com/takscape/elixir-arrayAn Elixir wrapper library for Erlang's array. Contribute to takscape/elixir-array development by creating an account on GitHub. - 88tf-idf elixir
https://github.com/OCannings/tf-idftf-idf elixir. Contribute to OCannings/tf-idf development by creating an account on GitHub. - 89A navigation tree representation with helpers to generate HTML out of it - depending of userroles
https://github.com/gutschilla/elixir-navigation-treeA navigation tree representation with helpers to generate HTML out of it - depending of userroles - gutschilla/elixir-navigation-tree - 90Terminal-based 2048 game written in Elixir
https://github.com/lexmag/tty2048Terminal-based 2048 game written in Elixir. Contribute to lexmag/tty2048 development by creating an account on GitHub. - 91Bitmap implementation in Elixir using binaries and integers. Fast space efficient data structure for lookups
https://github.com/hashd/bitmap-elixirBitmap implementation in Elixir using binaries and integers. Fast space efficient data structure for lookups - hashd/bitmap-elixir - 92Riak CS API wrapper for Elixir
https://github.com/ayrat555/ex_riak_csRiak CS API wrapper for Elixir. Contribute to ayrat555/ex_riak_cs development by creating an account on GitHub. - 93Parallel worker and capacity limiting library for Erlang
https://github.com/basho/sidejobParallel worker and capacity limiting library for Erlang - basho/sidejob - 94Erlang nif for xor_filter. 'Faster and Smaller Than Bloom and Cuckoo Filters'.
https://github.com/mpope9/exor_filterErlang nif for xor_filter. 'Faster and Smaller Than Bloom and Cuckoo Filters'. - mpope9/exor_filter - 95Elixir natural sort implementation for lists of strings.
https://github.com/DanCouper/natural_sortElixir natural sort implementation for lists of strings. - DanCouper/natural_sort - 96Slack OAuth2 Strategy for Überauth
https://github.com/ueberauth/ueberauth_slackSlack OAuth2 Strategy for Überauth. Contribute to ueberauth/ueberauth_slack development by creating an account on GitHub. - 97my website with collection of handy utils
https://github.com/q60/utilsmy website with collection of handy utils. Contribute to q60/utils development by creating an account on GitHub. - 98A multiplayer ship game built with Elixir, Phoenix Framework and Phaser. :rocket:
https://github.com/sergioaugrod/uai_shotA multiplayer ship game built with Elixir, Phoenix Framework and Phaser. :rocket: - sergioaugrod/uai_shot - 99Elixir implementation of bidirectional map and multimap
https://github.com/mkaput/elixir-bimapElixir implementation of bidirectional map and multimap - mkaput/elixir-bimap - 100Simple library to work with milliseconds
https://github.com/davebryson/elixir_millisecondsSimple library to work with milliseconds. Contribute to davebryson/elixir_milliseconds development by creating an account on GitHub. - 101🔎 CaptainFact - API. The one that serves and process all the data for https://captainfact.io
https://github.com/CaptainFact/captain-fact-api🔎 CaptainFact - API. The one that serves and process all the data for https://captainfact.io - CaptainFact/captain-fact-api - 102An Elixir library for performing 2D and 3D mathematics.
https://github.com/crertel/graphmathAn Elixir library for performing 2D and 3D mathematics. - crertel/graphmath - 103Elixir NIFs for interacting with llama_cpp.rust managed GGUF models.
https://github.com/noizu-labs-ml/ex_llamaElixir NIFs for interacting with llama_cpp.rust managed GGUF models. - noizu-labs-ml/ex_llama - 104Easy, powerful, and extendable configuration tooling for releases.
https://github.com/bitwalker/conformEasy, powerful, and extendable configuration tooling for releases. - bitwalker/conform - 105:awesome = Elixir's Task ++ Basho's sidejob library
https://github.com/PSPDFKit-labs/sidetask:awesome = Elixir's Task ++ Basho's sidejob library - PSPDFKit-labs/sidetask - 106TEA implementation in Elixir
https://github.com/keichan34/elixir_teaTEA implementation in Elixir. Contribute to keichan34/elixir_tea development by creating an account on GitHub. - 107utility package for loading, validating and documenting your app's configuration variables from env, json, jsonc and toml files at runtime and injecting them into your environment
https://github.com/massivefermion/enuxutility package for loading, validating and documenting your app's configuration variables from env, json, jsonc and toml files at runtime and injecting them into your environment - massiveferm... - 108Toggl tribute done with Elixir, Phoenix Framework, React and Redux.
https://github.com/bigardone/phoenix-togglToggl tribute done with Elixir, Phoenix Framework, React and Redux. - bigardone/phoenix-toggl - 109Guri - Slackbot command handler powered by Elixir
https://github.com/elvio/guriGuri - Slackbot command handler powered by Elixir. Contribute to elvio/guri development by creating an account on GitHub. - 110Run a release with one simple command
https://github.com/tsloughter/rebar3_runRun a release with one simple command. Contribute to tsloughter/rebar3_run development by creating an account on GitHub. - 111A CRDT library with δ-CRDT support.
https://github.com/asonge/loomA CRDT library with δ-CRDT support. Contribute to asonge/loom development by creating an account on GitHub. - 112AES CMAC (rfc 4493) in Elixir
https://github.com/kleinernik/elixir-aes-cmacAES CMAC (rfc 4493) in Elixir. Contribute to kleinernik/elixir-aes-cmac development by creating an account on GitHub. - 113Macros to use :timer.apply_after and :timer.apply_interval with a block
https://github.com/adamkittelson/block_timerMacros to use :timer.apply_after and :timer.apply_interval with a block - adamkittelson/block_timer - 114Rebar3 abnfc plugin
https://github.com/surik/rebar3_abnfc_pluginRebar3 abnfc plugin. Contribute to surik/rebar3_abnfc_plugin development by creating an account on GitHub. - 115Weaviate Rest Wrapper for Elixir
https://github.com/noizu-labs-ml/elixir-weaviateWeaviate Rest Wrapper for Elixir. Contribute to noizu-labs-ml/elixir-weaviate development by creating an account on GitHub. - 116A port of dotenv to Elixir
https://github.com/avdi/dotenv_elixirA port of dotenv to Elixir. Contribute to avdi/dotenv_elixir development by creating an account on GitHub. - 117A web-based document reader.
https://github.com/caddishouse/readerA web-based document reader. Contribute to caddishouse/reader development by creating an account on GitHub. - 118An app to search startup jobs scraped from websites written in Elixir, Phoenix, React and styled-components.
https://github.com/tsurupin/job_searchAn app to search startup jobs scraped from websites written in Elixir, Phoenix, React and styled-components. - GitHub - tsurupin/job_search: An app to search startup jobs scraped from websites wri... - 119OAuth 1.0 for Elixir
https://github.com/lexmag/oautherOAuth 1.0 for Elixir. Contribute to lexmag/oauther development by creating an account on GitHub. - 120Finite State Machine data structure
https://github.com/sasa1977/fsmFinite State Machine data structure. Contribute to sasa1977/fsm development by creating an account on GitHub. - 121Package providing functionality similar to Python's Pandas or R's data.frame()
https://github.com/JordiPolo/dataframePackage providing functionality similar to Python's Pandas or R's data.frame() - JordiPolo/dataframe - 122Elixir Indifferent access on maps/lists/tuples with custom key transforms.
https://github.com/vic/indifferentElixir Indifferent access on maps/lists/tuples with custom key transforms. - vic/indifferent - 123Erlang performance and debugging tools
https://github.com/massemanet/eperErlang performance and debugging tools. Contribute to massemanet/eper development by creating an account on GitHub. - 124An Elixir Debugger
https://github.com/maarek/etherAn Elixir Debugger. Contribute to maarek/ether development by creating an account on GitHub. - 125A tiny Elixir library for time-based one time passwords (TOTP)
https://github.com/dashbitco/nimble_totpA tiny Elixir library for time-based one time passwords (TOTP) - dashbitco/nimble_totp - 126Bounceapp/elixir-vercel
https://github.com/Bounceapp/elixir-vercelContribute to Bounceapp/elixir-vercel development by creating an account on GitHub. - 127ICalendar parser for Elixir.
https://github.com/fazibear/ex_icalICalendar parser for Elixir. Contribute to fazibear/ex_ical development by creating an account on GitHub. - 128sebastiw/rebar3_idl_compiler
https://github.com/sebastiw/rebar3_idl_compilerContribute to sebastiw/rebar3_idl_compiler development by creating an account on GitHub. - 129A sass plugin for elixir projects
https://github.com/zamith/sass_elixirA sass plugin for elixir projects. Contribute to zamith/sass_elixir development by creating an account on GitHub. - 130A signal synthesis library
https://github.com/bitgamma/synthexA signal synthesis library. Contribute to bitgamma/synthex development by creating an account on GitHub. - 131Rebar3 live plugin
https://github.com/pvmart/rebar3_liveRebar3 live plugin. Contribute to pvmart/rebar3_live development by creating an account on GitHub. - 132futures for elixir/erlang
https://github.com/exstruct/etudefutures for elixir/erlang. Contribute to exstruct/etude development by creating an account on GitHub. - 133Exon is a “mess manager” developed in Elixir and provides a simple API to manage & document your stuff.
https://github.com/tchoutri/ExonExon is a “mess manager” developed in Elixir and provides a simple API to manage & document your stuff. - tchoutri/Exon - 134Coverage Reports for Elixir
https://github.com/alfert/coverexCoverage Reports for Elixir. Contribute to alfert/coverex development by creating an account on GitHub. - 135Expressive and easy to use datetime functions in Elixir.
https://github.com/DevL/good_timesExpressive and easy to use datetime functions in Elixir. - DevL/good_times - 136Online estimation tool for Agile teams.
https://github.com/elpassion/sprint-pokerOnline estimation tool for Agile teams. Contribute to elpassion/sprint-poker development by creating an account on GitHub. - 137Trello tribute done in Elixir, Phoenix Framework, React and Redux.
https://github.com/bigardone/phoenix-trelloTrello tribute done in Elixir, Phoenix Framework, React and Redux. - bigardone/phoenix-trello - 138Ansible role to setup server with Elixir & Postgres to deploy apps
https://github.com/HashNuke/ansible-elixir-stackAnsible role to setup server with Elixir & Postgres to deploy apps - HashNuke/ansible-elixir-stack - 139Elixir implementation of ROCK: A Robust Clustering Algorithm for Categorical Attributes
https://github.com/ayrat555/rockElixir implementation of ROCK: A Robust Clustering Algorithm for Categorical Attributes - ayrat555/rock - 140Free, world-class retrospectives
https://github.com/stride-nyc/remote_retroFree, world-class retrospectives. Contribute to stride-nyc/remote_retro development by creating an account on GitHub. - 141Figaro for Elixir
https://github.com/trestrantham/ex_figaroFigaro for Elixir. Contribute to trestrantham/ex_figaro development by creating an account on GitHub. - 142💠 ECSV: Потоковий CSV парсер
https://github.com/erpuno/ecsv💠 ECSV: Потоковий CSV парсер. Contribute to erpuno/ecsv development by creating an account on GitHub. - 143Moment is designed to bring easy date and time handling to Elixir.
https://github.com/atabary/momentMoment is designed to bring easy date and time handling to Elixir. - atabary/moment - 144A visual tool to help developers understand Elixir recompilation in their projects
https://github.com/axelson/dep_viz/.A visual tool to help developers understand Elixir recompilation in their projects - axelson/dep_viz - 145An elixir date/time library
https://github.com/nurugger07/chronosAn elixir date/time library. Contribute to nurugger07/chronos development by creating an account on GitHub. - 146An Elixir module for returning an emoji clock for a given hour
https://github.com/nathanhornby/emojiclock-elixirAn Elixir module for returning an emoji clock for a given hour - nathanhornby/emojiclock-elixir - 147:u7533: Pretty printer for maps/structs collections (Elixir)
https://github.com/aerosol/tabula:u7533: Pretty printer for maps/structs collections (Elixir) - aerosol/Tabula - 148Server-side rendered SVG graphing components for Phoenix and LiveView
https://github.com/gridpoint-com/ploxServer-side rendered SVG graphing components for Phoenix and LiveView - gridpoint-com/plox - 149Library for working with RSA keys using Elixir and OpenSSL ports
https://github.com/anoskov/rsa-exLibrary for working with RSA keys using Elixir and OpenSSL ports - anoskov/rsa-ex - 150An example of CircleCI integration with Elixir
https://github.com/nirvana/belvedereAn example of CircleCI integration with Elixir. Contribute to nirvana/belvedere development by creating an account on GitHub. - 151Ahamtech/elixir-gandi
https://github.com/Ahamtech/elixir-GandiContribute to Ahamtech/elixir-gandi development by creating an account on GitHub. - 152A cron like system built in Elixir, that you can mount in your supervision tree
https://github.com/jbernardo95/cronexA cron like system built in Elixir, that you can mount in your supervision tree - jbernardo95/cronex - 153Elixir escript library (derived work from elixir)
https://github.com/liveforeverx/exscriptElixir escript library (derived work from elixir). Contribute to liveforeverx/exscript development by creating an account on GitHub. - 154a "compiler" (as in `Mix.compilers`) for Elixir that just runs make
https://github.com/jarednorman/dismakea "compiler" (as in `Mix.compilers`) for Elixir that just runs make - jarednorman/dismake - 155Rebar3 plugin to auto compile and reload on file change.
https://github.com/vans163/rebar3_autoRebar3 plugin to auto compile and reload on file change. - vans163/rebar3_auto - 156Guardian DB Redis adapter
https://github.com/alexfilatov/guardian_redisGuardian DB Redis adapter. Contribute to alexfilatov/guardian_redis development by creating an account on GitHub. - 157A modern, scriptable, dependency-based build tool loosely based on Make principles.
https://github.com/lycus/exmakeA modern, scriptable, dependency-based build tool loosely based on Make principles. - lycus/exmake - 158Phoenix routes helpers in JavaScript code.
https://github.com/khusnetdinov/phoenix_routes_jsPhoenix routes helpers in JavaScript code. Contribute to khusnetdinov/phoenix_routes_js development by creating an account on GitHub. - 159Scaffold generator for elixir phoenix absinthe projects
https://github.com/sashman/absinthe_genScaffold generator for elixir phoenix absinthe projects - sashman/absinthe_gen - 160Simple elixir library to define a static FSM.
https://github.com/awetzel/exfsmSimple elixir library to define a static FSM. Contribute to kbrw/exfsm development by creating an account on GitHub. - 161ETS-based fix-sized LRU cache for elixir
https://github.com/arago/lru_cacheETS-based fix-sized LRU cache for elixir. Contribute to arago/lru_cache development by creating an account on GitHub. - 162Application of a computer to improve the results obtained in working with the SuperMemo method - SuperMemo
https://www.supermemo.com/english/ol/sm2.htm.Application of a computer to improve the results obtained in working with the SuperMemo method. This text was taken from P.A.Wozniak. - 163Firmata protocol in Elixir
https://github.com/entone/firmataFirmata protocol in Elixir. Contribute to entone/firmata development by creating an account on GitHub. - 164Firex is a library for automatically generating command line interfaces (CLIs) from elixir module
https://github.com/msoedov/firexFirex is a library for automatically generating command line interfaces (CLIs) from elixir module - msoedov/firex - 165A configurable constraint solver
https://github.com/dkendal/aruspexA configurable constraint solver. Contribute to Dkendal/aruspex development by creating an account on GitHub. - 166:necktie: An Elixir presenter package used to transform map structures. "ActiveModel::Serializer for Elixir"
https://github.com/stavro/remodel:necktie: An Elixir presenter package used to transform map structures. "ActiveModel::Serializer for Elixir" - stavro/remodel - 167Command line arguments parser for Elixir
https://github.com/savonarola/optimusCommand line arguments parser for Elixir. Contribute to savonarola/optimus development by creating an account on GitHub. - 168RSASSA-PSS Public Key Cryptographic Signature Algorithm for Erlang and Elixir.
https://github.com/potatosalad/erlang-crypto_rsassa_pssRSASSA-PSS Public Key Cryptographic Signature Algorithm for Erlang and Elixir. - potatosalad/erlang-crypto_rsassa_pss - 169CSV for Elixir
https://github.com/CargoSense/ex_csvCSV for Elixir. Contribute to CargoSense/ex_csv development by creating an account on GitHub. - 170An Elixir implementation of the SipHash cryptographic hash family
https://github.com/whitfin/siphash-elixirAn Elixir implementation of the SipHash cryptographic hash family - whitfin/siphash-elixir - 171Elixir wrapper for the OpenBSD bcrypt password hashing algorithm
https://github.com/manelli/ex_bcryptElixir wrapper for the OpenBSD bcrypt password hashing algorithm - manelli/ex_bcrypt - 172a NIF for libntru. NTRU is a post quantum cryptography algorithm.
https://github.com/alisinabh/ntru_elixira NIF for libntru. NTRU is a post quantum cryptography algorithm. - alisinabh/ntru_elixir - 173A Google Secret Manager Provider for Hush
https://github.com/gordalina/hush_gcp_secret_managerA Google Secret Manager Provider for Hush. Contribute to gordalina/hush_gcp_secret_manager development by creating an account on GitHub. - 174Time calculations using business hours
https://github.com/hopsor/open_hoursTime calculations using business hours. Contribute to hopsor/open_hours development by creating an account on GitHub. - 175Sane, simple release creation for Erlang
https://github.com/erlware/relxSane, simple release creation for Erlang. Contribute to erlware/relx development by creating an account on GitHub. - 176Elixir package for Oauth authentication via Google Cloud APIs
https://github.com/peburrows/gothElixir package for Oauth authentication via Google Cloud APIs - peburrows/goth - 177Easy permission definitions in Elixir apps!
https://github.com/jarednorman/canadaEasy permission definitions in Elixir apps! Contribute to jarednorman/canada development by creating an account on GitHub. - 178A library for simple passwordless authentication
https://github.com/madebymany/passwordless_authA library for simple passwordless authentication. Contribute to madebymany/passwordless_auth development by creating an account on GitHub. - 179Set of Plugs / Lib to help with SSL Client Auth.
https://github.com/jshmrtn/phoenix-client-sslSet of Plugs / Lib to help with SSL Client Auth. Contribute to jshmrtn/phoenix-client-ssl development by creating an account on GitHub. - 180Convert hex doc to Dash.app's docset format.
https://github.com/yesmeck/hexdocsetConvert hex doc to Dash.app's docset format. Contribute to yesmeck/hexdocset development by creating an account on GitHub. - 181Elixir Deployment Automation Package
https://github.com/annkissam/akdElixir Deployment Automation Package. Contribute to annkissam/akd development by creating an account on GitHub. - 182Rebar3 neotoma (Parser Expression Grammar) compiler
https://github.com/zamotivator/rebar3_neotoma_pluginRebar3 neotoma (Parser Expression Grammar) compiler - excavador/rebar3_neotoma_plugin - 183CSV handling library for Elixir.
https://github.com/meh/cessoCSV handling library for Elixir. Contribute to meh/cesso development by creating an account on GitHub. - 184A Slack bot framework for Elixir; down the rabbit hole!
https://github.com/alice-bot/aliceA Slack bot framework for Elixir; down the rabbit hole! - alice-bot/alice - 185A static code analysis tool for the Elixir language with a focus on code consistency and teaching.
https://github.com/rrrene/credoA static code analysis tool for the Elixir language with a focus on code consistency and teaching. - rrrene/credo - 186Automatic cluster formation/healing for Elixir applications
https://github.com/bitwalker/libclusterAutomatic cluster formation/healing for Elixir applications - bitwalker/libcluster - 187IRC client adapter for Elixir projects
https://github.com/bitwalker/exircIRC client adapter for Elixir projects. Contribute to bitwalker/exirc development by creating an account on GitHub. - 188A library for managing pools of workers
https://github.com/general-CbIC/poolexA library for managing pools of workers. Contribute to general-CbIC/poolex development by creating an account on GitHub. - 189Digital goods shop & blog created using Elixir (Phoenix framework)
https://github.com/authentic-pixels/ex-shopDigital goods shop & blog created using Elixir (Phoenix framework) - bharani91/ex-shop - 190Bringing the power of the command line to chat
https://github.com/operable/cogBringing the power of the command line to chat. Contribute to operable/cog development by creating an account on GitHub. - 191Command Line application framework for Elixir
https://github.com/bennyhallett/anubisCommand Line application framework for Elixir. Contribute to BennyHallett/anubis development by creating an account on GitHub. - 192Simple Elixir Configuration Management
https://github.com/phoenixframework/ex_confSimple Elixir Configuration Management. Contribute to phoenixframework/ex_conf development by creating an account on GitHub. - 193gpg interface
https://github.com/rozap/exgpggpg interface. Contribute to rozap/exgpg development by creating an account on GitHub. - 194Strategies For Automatic Node Discovery
https://github.com/okeuday/nodefinderStrategies For Automatic Node Discovery. Contribute to okeuday/nodefinder development by creating an account on GitHub. - 195Calixir is a port of the Lisp calendar software calendrica-4.0 to Elixir.
https://github.com/rengel-de/calixirCalixir is a port of the Lisp calendar software calendrica-4.0 to Elixir. - rengel-de/calixir - 196Natural language for repeating dates
https://github.com/rcdilorenzo/repeatexNatural language for repeating dates. Contribute to rcdilorenzo/repeatex development by creating an account on GitHub. - 197Useful helper to read and use application configuration from environment variables.
https://github.com/Nebo15/confexUseful helper to read and use application configuration from environment variables. - Nebo15/confex - 198Kubex is the kubernetes integration for Elixir projects and it is written in pure Elixir.
https://github.com/ingerslevio/kubexKubex is the kubernetes integration for Elixir projects and it is written in pure Elixir. - ingerslevio/kubex - 199Weibo OAuth2 strategy for Überauth.
https://github.com/he9qi/ueberauth_weiboWeibo OAuth2 strategy for Überauth. Contribute to he9qi/ueberauth_weibo development by creating an account on GitHub. - 200⚡ MAD: Managing Application Dependencies LING/UNIX
https://github.com/synrc/mad⚡ MAD: Managing Application Dependencies LING/UNIX - synrc/mad - 201Central Authentication Service strategy for Überauth
https://github.com/marceldegraaf/ueberauth_casCentral Authentication Service strategy for Überauth - marceldegraaf/ueberauth_cas - 202Swagger integration to Phoenix framework
https://github.com/xerions/phoenix_swaggerSwagger integration to Phoenix framework. Contribute to xerions/phoenix_swagger development by creating an account on GitHub. - 203Dash.app formatter for ex_doc.
https://github.com/JonGretar/ExDocDashDash.app formatter for ex_doc. Contribute to JonGretar/ExDocDash development by creating an account on GitHub. - 204something to forget about configuration in releases
https://github.com/d0rc/sweetconfigsomething to forget about configuration in releases - d0rc/sweetconfig - 205Erlang PortAudio bindings
https://github.com/asonge/erlaudioErlang PortAudio bindings. Contribute to asonge/erlaudio development by creating an account on GitHub. - 206A powerful caching library for Elixir with support for transactions, fallbacks and expirations
https://github.com/whitfin/cachexA powerful caching library for Elixir with support for transactions, fallbacks and expirations - whitfin/cachex - 207:closed_lock_with_key: A code style linter for Elixir
https://github.com/lpil/dogma:closed_lock_with_key: A code style linter for Elixir - lpil/dogma - 208:pencil: Loki is library that includes helpers for building powerful interactive command line applications, tasks, modules.
https://github.com/khusnetdinov/loki:pencil: Loki is library that includes helpers for building powerful interactive command line applications, tasks, modules. - khusnetdinov/loki - 209Jalaali (also known as Jalali, Persian, Khorshidi, Shamsi) calendar implementation in Elixir.
https://github.com/jalaali/elixir-jalaaliJalaali (also known as Jalali, Persian, Khorshidi, Shamsi) calendar implementation in Elixir. - jalaali/elixir-jalaali - 210Elixir package that applies a function to each document in a BSON file.
https://github.com/Nebo15/bsoneachElixir package that applies a function to each document in a BSON file. - Nebo15/bsoneach - 211Microsoft Strategy for Überauth
https://github.com/swelham/ueberauth_microsoftMicrosoft Strategy for Überauth. Contribute to swelham/ueberauth_microsoft development by creating an account on GitHub. - 212Automatic recompilation of mix code on file change.
https://github.com/AgilionApps/remixAutomatic recompilation of mix code on file change. - AgilionApps/remix - 213Parse Cron Expressions, Compose Cron Expression Strings and Caluclate Execution Dates.
https://github.com/jshmrtn/crontabParse Cron Expressions, Compose Cron Expression Strings and Caluclate Execution Dates. - maennchen/crontab - 214A simple web server written in elixir to stack images
https://github.com/IcaliaLabs/medusa_serverA simple web server written in elixir to stack images - kurenn/medusa_server - 215Twitter Strategy for Überauth
https://github.com/ueberauth/ueberauth_twitterTwitter Strategy for Überauth. Contribute to ueberauth/ueberauth_twitter development by creating an account on GitHub. - 216A GitHub OAuth2 Provider for Elixir
https://github.com/chrislaskey/oauth2_githubA GitHub OAuth2 Provider for Elixir. Contribute to chrislaskey/oauth2_github development by creating an account on GitHub. - 217ALSA NIFs in C for Elixir.
https://github.com/dulltools/ex_alsaALSA NIFs in C for Elixir. Contribute to dulltools/ex_alsa development by creating an account on GitHub. - 218Erlang public_key cryptography wrapper for Elixir
https://github.com/trapped/elixir-rsaErlang public_key cryptography wrapper for Elixir. Contribute to trapped/elixir-rsa development by creating an account on GitHub. - 219Erlang/Elixir helpers
https://github.com/qhool/quaffErlang/Elixir helpers. Contribute to qhool/quaff development by creating an account on GitHub. - 220A simple tool to manage inspect debugger
https://github.com/marciol/inspectorA simple tool to manage inspect debugger. Contribute to marciol/inspector development by creating an account on GitHub. - 221rebar3 protobuffs provider using protobuffs from Basho
https://github.com/benoitc/rebar3_protobuffsrebar3 protobuffs provider using protobuffs from Basho - benoitc/rebar3_protobuffs - 222A toolkit for writing command-line user interfaces.
https://github.com/fuelen/owlA toolkit for writing command-line user interfaces. - fuelen/owl - 223A rebar3 plugin to enable the execution of Erlang QuickCheck properties
https://github.com/kellymclaughlin/rebar3-eqc-pluginA rebar3 plugin to enable the execution of Erlang QuickCheck properties - GitHub - kellymclaughlin/rebar3-eqc-plugin: A rebar3 plugin to enable the execution of Erlang QuickCheck properties - 224:hibiscus: A pure Elixir implementation of Scalable Bloom Filters
https://github.com/gmcabrita/bloomex:hibiscus: A pure Elixir implementation of Scalable Bloom Filters - gmcabrita/bloomex - 225A simple code profiler for Elixir using eprof.
https://github.com/parroty/exprofA simple code profiler for Elixir using eprof. Contribute to parroty/exprof development by creating an account on GitHub. - 226Guardian DB integration for tracking tokens and ensuring logout cannot be replayed.
https://github.com/ueberauth/guardian_dbGuardian DB integration for tracking tokens and ensuring logout cannot be replayed. - ueberauth/guardian_db - 227Request caching for Phoenix & Absinthe (GraphQL), short circuiting even the JSON decoding/encoding
https://github.com/MikaAK/request_cache_plugRequest caching for Phoenix & Absinthe (GraphQL), short circuiting even the JSON decoding/encoding - GitHub - MikaAK/request_cache_plug: Request caching for Phoenix & Absinthe (GraphQL), s... - 228Password hashing specification for the Elixir programming language
https://github.com/riverrun/comeoninPassword hashing specification for the Elixir programming language - riverrun/comeonin - 229A simple Elixir parser for the same kind of files that Python's configparser library handles
https://github.com/easco/configparser_exA simple Elixir parser for the same kind of files that Python's configparser library handles - easco/configparser_ex - 230Facebook OAuth2 Strategy for Überauth.
https://github.com/ueberauth/ueberauth_FacebookFacebook OAuth2 Strategy for Überauth. Contribute to ueberauth/ueberauth_facebook development by creating an account on GitHub. - 231[WIP] Another authentication hex for Phoenix.
https://github.com/khusnetdinov/sesamex[WIP] Another authentication hex for Phoenix. Contribute to khusnetdinov/sesamex development by creating an account on GitHub. - 232AWS Signature Version 4 Signing Library for Elixir
https://github.com/bryanjos/aws_authAWS Signature Version 4 Signing Library for Elixir - bryanjos/aws_auth - 233Middleware based authorization for Absinthe GraphQL powered by Bodyguard
https://github.com/coryodaniel/speakeasyMiddleware based authorization for Absinthe GraphQL powered by Bodyguard - coryodaniel/speakeasy - 234Google OAuth2 Strategy for Überauth.
https://github.com/ueberauth/ueberauth_googleGoogle OAuth2 Strategy for Überauth. Contribute to ueberauth/ueberauth_google development by creating an account on GitHub. - 235:fire: Phoenix variables in your JavaScript without headache.
https://github.com/khusnetdinov/phoenix_gon:fire: Phoenix variables in your JavaScript without headache. - khusnetdinov/phoenix_gon - 236Red-black tree implementation for Elixir.
https://github.com/SenecaSystems/red_black_treeRed-black tree implementation for Elixir. Contribute to tyre/red_black_tree development by creating an account on GitHub. - 237A simple and functional machine learning library for the Erlang ecosystem
https://github.com/mrdimosthenis/emelA simple and functional machine learning library for the Erlang ecosystem - mrdimosthenis/emel - 238Upgrade your pipelines with monads.
https://github.com/rob-brown/MonadExUpgrade your pipelines with monads. Contribute to rob-brown/MonadEx development by creating an account on GitHub. - 239Rule based authorization for Elixir
https://github.com/jfrolich/authorizeRule based authorization for Elixir. Contribute to jfrolich/authorize development by creating an account on GitHub. - 240An Elixir Authentication System for Plug-based Web Applications
https://github.com/ueberauth/ueberauthAn Elixir Authentication System for Plug-based Web Applications - ueberauth/ueberauth - 241A blazing fast matrix library for Elixir/Erlang with C implementation using CBLAS.
https://github.com/versilov/matrexA blazing fast matrix library for Elixir/Erlang with C implementation using CBLAS. - versilov/matrex - 242Elixir encryption library designed for Ecto
https://github.com/danielberkompas/cloakElixir encryption library designed for Ecto. Contribute to danielberkompas/cloak development by creating an account on GitHub. - 243A time- and memory-efficient data structure for positive integers.
https://github.com/Cantido/int_setA time- and memory-efficient data structure for positive integers. - Cantido/int_set - 244Kubernetes API Client for Elixir
https://github.com/coryodaniel/k8sKubernetes API Client for Elixir. Contribute to coryodaniel/k8s development by creating an account on GitHub. - 245Microbenchmarking tool for Elixir
https://github.com/alco/benchfellaMicrobenchmarking tool for Elixir. Contribute to alco/benchfella development by creating an account on GitHub. - 246Simple deployment and server automation for Elixir.
https://github.com/labzero/bootlegSimple deployment and server automation for Elixir. - labzero/bootleg - 247Generate Phoenix API documentation from tests
https://github.com/api-hogs/bureaucratGenerate Phoenix API documentation from tests. Contribute to api-hogs/bureaucrat development by creating an account on GitHub. - 248Converts Elixir to JavaScript
https://github.com/elixirscript/elixirscript/Converts Elixir to JavaScript. Contribute to elixirscript/elixirscript development by creating an account on GitHub. - 249An AWS Secrets Manager Provider for Hush
https://github.com/gordalina/hush_aws_secrets_managerAn AWS Secrets Manager Provider for Hush. Contribute to gordalina/hush_aws_secrets_manager development by creating an account on GitHub. - 250Quickly get started developing clustered Elixir applications for cloud environments.
https://github.com/CrowdHailer/elixir-on-dockerQuickly get started developing clustered Elixir applications for cloud environments. - CrowdHailer/elixir-on-docker - 251Computational parallel flows on top of GenStage
https://github.com/dashbitco/flowComputational parallel flows on top of GenStage. Contribute to dashbitco/flow development by creating an account on GitHub. - 252Tools to make Plug, and Phoenix authentication simple and flexible.
https://github.com/BlakeWilliams/doormanTools to make Plug, and Phoenix authentication simple and flexible. - BlakeWilliams/doorman - 253An OTP application for auto-discovering services with Consul
https://github.com/undeadlabs/discoveryAn OTP application for auto-discovering services with Consul - undeadlabs/discovery - 254Command-line progress bars and spinners for Elixir.
https://github.com/henrik/progress_barCommand-line progress bars and spinners for Elixir. - henrik/progress_bar - 255Wrapper around the Erlang crypto module for Elixir.
https://github.com/ntrepid8/ex_cryptoWrapper around the Erlang crypto module for Elixir. - ntrepid8/ex_crypto - 256An Elixir app which generates text-based tables for display
https://github.com/djm/table_rexAn Elixir app which generates text-based tables for display - djm/table_rex - 257AWS clients for Elixir
https://github.com/aws-beam/aws-elixirAWS clients for Elixir. Contribute to aws-beam/aws-elixir development by creating an account on GitHub. - 258GitHub OAuth2 Strategy for Überauth
https://github.com/ueberauth/ueberauth_githubGitHub OAuth2 Strategy for Überauth. Contribute to ueberauth/ueberauth_github development by creating an account on GitHub. - 259:bento: A fast, correct, pure-Elixir library for reading and writing Bencoded metainfo (.torrent) files.
https://github.com/folz/bento:bento: A fast, correct, pure-Elixir library for reading and writing Bencoded metainfo (.torrent) files. - folz/bento - 260Deploy Elixir applications via mix tasks
https://github.com/joeyates/exdmDeploy Elixir applications via mix tasks. Contribute to joeyates/exdm development by creating an account on GitHub. - 261User friendly CLI apps for Elixir
https://github.com/tuvistavie/ex_cliUser friendly CLI apps for Elixir. Contribute to danhper/ex_cli development by creating an account on GitHub. - 262ExPrompt is a helper package to add interactivity to your command line applications as easy as possible.
https://github.com/behind-design/ex_promptExPrompt is a helper package to add interactivity to your command line applications as easy as possible. - bjufre/ex_prompt - 263A date/time interval library for Elixir projects, based on Timex.
https://github.com/atabary/timex-intervalA date/time interval library for Elixir projects, based on Timex. - atabary/timex-interval - 264Phoenix API Docs
https://github.com/smoku/phoenix_api_docsPhoenix API Docs. Contribute to smoku/phoenix_api_docs development by creating an account on GitHub. - 265Erlang reltool utility functionality application
https://github.com/okeuday/reltool_utilErlang reltool utility functionality application. Contribute to okeuday/reltool_util development by creating an account on GitHub. - 266Atomic distributed "check and set" for short-lived keys
https://github.com/wooga/lockerAtomic distributed "check and set" for short-lived keys - wooga/locker - 267Elixir wrapper for Recon Trace.
https://github.com/redink/extraceElixir wrapper for Recon Trace. Contribute to redink/extrace development by creating an account on GitHub. - 268Yawolf/yocingo
https://github.com/Yawolf/yocingoContribute to Yawolf/yocingo development by creating an account on GitHub. - 269An Adapter-based Bot Framework for Elixir Applications
https://github.com/hedwig-im/hedwigAn Adapter-based Bot Framework for Elixir Applications - hedwig-im/hedwig - 270One task to efficiently run all code analysis & testing tools in an Elixir project. Born out of 💜 to Elixir and pragmatism.
https://github.com/karolsluszniak/ex_checkOne task to efficiently run all code analysis & testing tools in an Elixir project. Born out of 💜 to Elixir and pragmatism. - karolsluszniak/ex_check - 271In-memory and distributed caching toolkit for Elixir.
https://github.com/cabol/nebulexIn-memory and distributed caching toolkit for Elixir. - cabol/nebulex - 272LINE strategy for Ueberauth
https://github.com/alexfilatov/ueberauth_lineLINE strategy for Ueberauth. Contribute to alexfilatov/ueberauth_line development by creating an account on GitHub. - 273Foursquare OAuth2 Strategy for Überauth
https://github.com/borodiychuk/ueberauth_foursquareFoursquare OAuth2 Strategy for Überauth. Contribute to borodiychuk/ueberauth_foursquare development by creating an account on GitHub. - 274tsharju/elixir_locker
https://github.com/tsharju/elixir_lockerContribute to tsharju/elixir_locker development by creating an account on GitHub. - 275A simple, secure, and highly configurable Elixir identity [username | email | id | etc.]/password authentication module to use with Ecto.
https://github.com/zmoshansky/aeacusA simple, secure, and highly configurable Elixir identity [username | email | id | etc.]/password authentication module to use with Ecto. - zmoshansky/aeacus - 276Leaseweb API Wrapper for Elixir and Erlang
https://github.com/Ahamtech/elixir-leasewebLeaseweb API Wrapper for Elixir and Erlang. Contribute to Ahamtech/elixir-leaseweb development by creating an account on GitHub. - 277Elixir crypto library to encrypt/decrypt arbitrary binaries
https://github.com/rubencaro/cipherElixir crypto library to encrypt/decrypt arbitrary binaries - rubencaro/cipher - 278date-time and time zone handling in Elixir
https://github.com/lau/calendardate-time and time zone handling in Elixir. Contribute to lau/calendar development by creating an account on GitHub. - 279An Elixir library to sign and verify HTTP requests using AWS Signature V4
https://github.com/handnot2/sigawsAn Elixir library to sign and verify HTTP requests using AWS Signature V4 - handnot2/sigaws - 280MojoAuth implementation in Elixir
https://github.com/mojolingo/mojo-auth.exMojoAuth implementation in Elixir. Contribute to mojolingo/mojo-auth.ex development by creating an account on GitHub. - 281Elixir tool for benchmarking EVM performance
https://github.com/membraneframework/beamchmarkElixir tool for benchmarking EVM performance. Contribute to membraneframework/beamchmark development by creating an account on GitHub. - 282[DISCONTINUED] HipChat client library for Elixir
https://github.com/ymtszw/hipchat_elixir[DISCONTINUED] HipChat client library for Elixir. Contribute to ymtszw/hipchat_elixir development by creating an account on GitHub. - 283A Facebook OAuth2 Provider for Elixir
https://github.com/chrislaskey/oauth2_facebookA Facebook OAuth2 Provider for Elixir. Contribute to chrislaskey/oauth2_facebook development by creating an account on GitHub. - 284Pretty print tables of Elixir structs and maps.
https://github.com/codedge-llc/scribePretty print tables of Elixir structs and maps. Contribute to codedge-llc/scribe development by creating an account on GitHub. - 285Elixir/Phoenix Cloud SDK and Deployment Tool
https://github.com/sashaafm/nomadElixir/Phoenix Cloud SDK and Deployment Tool. Contribute to sashaafm/nomad development by creating an account on GitHub. - 286Supercharge your environment variables in Elixir. Parse and validate with compile time access guarantees, defaults, fallbacks and app pre-boot validations.
https://github.com/emadalam/mahaulSupercharge your environment variables in Elixir. Parse and validate with compile time access guarantees, defaults, fallbacks and app pre-boot validations. - emadalam/mahaul - 287Simple authorization conventions for Phoenix apps
https://github.com/schrockwell/bodyguardSimple authorization conventions for Phoenix apps. Contribute to schrockwell/bodyguard development by creating an account on GitHub. - 288Get your Elixir into proper recipients, and serve it nicely to final consumers
https://github.com/rubencaro/bottlerGet your Elixir into proper recipients, and serve it nicely to final consumers - rubencaro/bottler - 289A flexible, easy to use set of clients AWS APIs for Elixir
https://github.com/CargoSense/ex_awsA flexible, easy to use set of clients AWS APIs for Elixir - ex-aws/ex_aws - 290encode and decode bittorrent peer wire protocol messages with elixir
https://github.com/alehander42/wireencode and decode bittorrent peer wire protocol messages with elixir - alehander92/wire - 291The GraphQL toolkit for Elixir
https://github.com/absinthe-graphql/absintheThe GraphQL toolkit for Elixir. Contribute to absinthe-graphql/absinthe development by creating an account on GitHub. - 292A mirror for https://git.sr.ht/~hwrd/beaker
https://github.com/hahuang65/beakerA mirror for https://git.sr.ht/~hwrd/beaker. Contribute to hahuang65/beaker development by creating an account on GitHub. - 293An Elixir Evolutive Neural Network framework à la G.Sher
https://github.com/zampino/exnnAn Elixir Evolutive Neural Network framework à la G.Sher - zampino/exnn - 294A Circuit Breaker for Erlang
https://github.com/jlouis/fuseA Circuit Breaker for Erlang. Contribute to jlouis/fuse development by creating an account on GitHub. - 295Erlang module to parse command line arguments using the GNU getopt syntax
https://github.com/jcomellas/getoptErlang module to parse command line arguments using the GNU getopt syntax - jcomellas/getopt - 296A blazing fast fully-automated CSV to database importer
https://github.com/Arp-G/csv2sqlA blazing fast fully-automated CSV to database importer - Arp-G/csv2sql - 297The Elixir based Kubernetes Development Framework
https://github.com/coryodaniel/bonnyThe Elixir based Kubernetes Development Framework. Contribute to coryodaniel/bonny development by creating an account on GitHub. - 298Automatic cluster formation/healing for Elixir applications.
https://github.com/Nebo15/skyclusterAutomatic cluster formation/healing for Elixir applications. - Nebo15/skycluster - 299A plugin to run Elixir ExUnit tests from rebar3 build tool
https://github.com/processone/rebar3_exunitA plugin to run Elixir ExUnit tests from rebar3 build tool - processone/rebar3_exunit - 300A benchmarking tool for Elixir
https://github.com/joekain/bmarkA benchmarking tool for Elixir. Contribute to joekain/bmark development by creating an account on GitHub. - 301An easy to use licensing system, using asymmetric cryptography to generate and validate licenses.
https://github.com/railsmechanic/zachaeusAn easy to use licensing system, using asymmetric cryptography to generate and validate licenses. - railsmechanic/zachaeus - 302Erlang, in-memory distributable cache
https://github.com/jr0senblum/jcErlang, in-memory distributable cache. Contribute to jr0senblum/jc development by creating an account on GitHub. - 303Cryptocurrency trading platform
https://github.com/cinderella-man/igthornCryptocurrency trading platform. Contribute to Cinderella-Man/igthorn development by creating an account on GitHub. - 304An Elixir wrapper for the holiday API Calendarific
https://github.com/Bounceapp/elixir-calendarificAn Elixir wrapper for the holiday API Calendarific - Bounceapp/elixir-calendarific - 305ets based key/value cache with row level isolated writes and ttl support
https://github.com/sasa1977/con_cacheets based key/value cache with row level isolated writes and ttl support - sasa1977/con_cache - 306A Naive Bayes machine learning implementation in Elixir.
https://github.com/fredwu/simple_bayesA Naive Bayes machine learning implementation in Elixir. - fredwu/simple_bayes - 307:evergreen_tree: Merkle Tree implementation in pure Elixir
https://github.com/yosriady/merkle_tree:evergreen_tree: Merkle Tree implementation in pure Elixir - yosriady/merkle_tree - 308A debug web toolbar for Phoenix projects to display all sorts of information about request
https://github.com/kagux/ex_debug_toolbarA debug web toolbar for Phoenix projects to display all sorts of information about request - kagux/ex_debug_toolbar - 309POT is an Erlang library for generating Google Authenticator compatible one time passwords
https://github.com/yuce/potPOT is an Erlang library for generating Google Authenticator compatible one time passwords - yuce/pot - 310An idiomatic Elixir wrapper for gen_statem in OTP 19 (and above).
https://github.com/antipax/gen_state_machineAn idiomatic Elixir wrapper for gen_statem in OTP 19 (and above). - ericentin/gen_state_machine - 311Transform ML models into a native code (Java, C, Python, Go, JavaScript, Visual Basic, C#, R, PowerShell, PHP, Dart, Haskell, Ruby, F#, Rust) with zero dependencies
https://github.com/BayesWitnesses/m2cgenTransform ML models into a native code (Java, C, Python, Go, JavaScript, Visual Basic, C#, R, PowerShell, PHP, Dart, Haskell, Ruby, F#, Rust) with zero dependencies - BayesWitnesses/m2cgen - 312🐺 A Fast, Secure and Reliable Terraform Backend, Set up in Minutes.
https://github.com/clivern/lynx🐺 A Fast, Secure and Reliable Terraform Backend, Set up in Minutes. - Clivern/Lynx - 313A library for performing and validating complex filters from a client (e.g. smart filters)
https://github.com/rcdilorenzo/filtrexA library for performing and validating complex filters from a client (e.g. smart filters) - rcdilorenzo/filtrex - 314A rebar3 port compiler
https://github.com/blt/port_compilerA rebar3 port compiler. Contribute to blt/port_compiler development by creating an account on GitHub. - 315A method caching macro for elixir using CAS on ETS.
https://github.com/melpon/memoizeA method caching macro for elixir using CAS on ETS. - melpon/memoize - 316An elixir module for parallel execution of functions/processes
https://github.com/StevenJL/parexAn elixir module for parallel execution of functions/processes - StevenJL/parex - 317An Elixir Slack bot! (work in progress)
https://github.com/koudelka/slackerAn Elixir Slack bot! (work in progress). Contribute to koudelka/slacker development by creating an account on GitHub. - 318Tracing for Elixir
https://github.com/fishcakez/dbgTracing for Elixir. Contribute to fishcakez/dbg development by creating an account on GitHub. - 319A username/password Strategy for Überauth
https://github.com/ueberauth/ueberauth_identityA username/password Strategy for Überauth. Contribute to ueberauth/ueberauth_identity development by creating an account on GitHub. - 320CSV Decoding and Encoding for Elixir
https://github.com/beatrichartz/csvCSV Decoding and Encoding for Elixir. Contribute to beatrichartz/csv development by creating an account on GitHub. - 321Elixir’s Platform as a Service
https://www.gigalixir.comThe only platform that fully supports Elixir and Phoenix. Unlock the full power of Elixir/Phoenix. No infrastructure, maintenance, or operations. - 322Flame Graph profiler for Erlang
https://github.com/proger/eflameFlame Graph profiler for Erlang. Contribute to proger/eflame development by creating an account on GitHub. - 323Robust, modular, and extendable user authentication system
https://github.com/danschultzer/powRobust, modular, and extendable user authentication system - pow-auth/pow - 324A simple and fast CSV parsing and dumping library for Elixir
https://github.com/plataformatec/nimble_csvA simple and fast CSV parsing and dumping library for Elixir - dashbitco/nimble_csv - 325Rebar3 yang compiler
https://github.com/surik/rebar3_yang_pluginRebar3 yang compiler. Contribute to surik/rebar3_yang_plugin development by creating an account on GitHub. - 326Simple OAuth2 client written for elixir
https://github.com/mgamini/oauth2cli-elixirSimple OAuth2 client written for elixir. Contribute to mgamini/oauth2cli-elixir development by creating an account on GitHub. - 327Elixir Plug library to enable SAML 2.0 SP SSO in Phoenix/Plug applications.
https://github.com/handnot2/samlyElixir Plug library to enable SAML 2.0 SP SSO in Phoenix/Plug applications. - handnot2/samly - 328An Elixir tool for checking safety of database migrations.
https://github.com/Artur-Sulej/excellent_migrationsAn Elixir tool for checking safety of database migrations. - Artur-Sulej/excellent_migrations - 329A thin Elixir wrapper for the redbug Erlang tracing debugger.
https://github.com/nietaki/rexbugA thin Elixir wrapper for the redbug Erlang tracing debugger. - nietaki/rexbug - 330JACK interface for Elixir using NIFs.
https://github.com/dulltools/ex_jackJACK interface for Elixir using NIFs. Contribute to dulltools/ex_jack development by creating an account on GitHub. - 331Elixir date recurrence library based on iCalendar events
https://github.com/peek-travel/cocktailElixir date recurrence library based on iCalendar events - peek-travel/cocktail - 332ExDoc produces HTML and EPUB documentation for Elixir projects
https://github.com/elixir-lang/ex_docExDoc produces HTML and EPUB documentation for Elixir projects - elixir-lang/ex_doc - 333Jupyter's kernel for Elixir programming language
https://github.com/pprzetacznik/IElixirJupyter's kernel for Elixir programming language. Contribute to pprzetacznik/IElixir development by creating an account on GitHub. - 334A simple yet efficient URL shortening service written in Elixir
https://github.com/Queertoo/QueerlinkA simple yet efficient URL shortening service written in Elixir - Queertoo/Queerlink - 335Super-simple build system for Elixir
https://github.com/HashNuke/rotorSuper-simple build system for Elixir. Contribute to HashNuke/rotor development by creating an account on GitHub. - 336Nx-powered Neural Networks
https://github.com/elixir-nx/axonNx-powered Neural Networks. Contribute to elixir-nx/axon development by creating an account on GitHub. - 337AWS APIs library for Erlang (Amazon EC2, S3, SQS, DDB, ELB and etc)
https://github.com/erlcloud/erlcloudAWS APIs library for Erlang (Amazon EC2, S3, SQS, DDB, ELB and etc) - erlcloud/erlcloud - 338⛔️ DEPRECATED A very simple tool for releasing elixir applications
https://github.com/miros/exreleasy⛔️ DEPRECATED A very simple tool for releasing elixir applications - miros/exreleasy - 339API Documentation Generator for the Phoenix Framework
https://github.com/KittyHeaven/blue_birdAPI Documentation Generator for the Phoenix Framework - KittyHeaven/blue_bird - 340An OAuth 2.0 client library for elixir.
https://github.com/parroty/oauth2exAn OAuth 2.0 client library for elixir. Contribute to parroty/oauth2ex development by creating an account on GitHub. - 341Generative AI client for multiple providers with plugin extension support
https://github.com/noizu-labs-ml/genaiGenerative AI client for multiple providers with plugin extension support - noizu-labs-ml/genai - 342A TUI (terminal UI) kit for Elixir
https://github.com/ndreynolds/ratatouilleA TUI (terminal UI) kit for Elixir. Contribute to ndreynolds/ratatouille development by creating an account on GitHub. - 343🛡 Modern elixir ACL/ABAC library for managing granular user abilities and permissions
https://github.com/MilosMosovsky/terminator🛡 Modern elixir ACL/ABAC library for managing granular user abilities and permissions - MilosMosovsky/terminator - 344:hatching_chick: Elixir authorization and resource-loading library for Plug applications.
https://github.com/cpjk/canary:hatching_chick: Elixir authorization and resource-loading library for Plug applications. - cpjk/canary - 345🪝 Add git hooks to Elixir projects
https://github.com/qgadrian/elixir_git_hooks🪝 Add git hooks to Elixir projects. Contribute to qgadrian/elixir_git_hooks development by creating an account on GitHub. - 346Apache/APR Style Password Hashing
https://github.com/kevinmontuori/Apache.PasswdMD5Apache/APR Style Password Hashing. Contribute to bunnylushington/Apache.PasswdMD5 development by creating an account on GitHub. - 347Simple Elixir wrapper for the Stockfighter API
https://github.com/shanewilton/stockasticSimple Elixir wrapper for the Stockfighter API. Contribute to QuinnWilton/stockastic development by creating an account on GitHub. - 348👤Minimalist Google OAuth Authentication for Elixir Apps. Tested, Documented & Maintained. Setup in 5 mins. 🚀
https://github.com/dwyl/elixir-auth-google👤Minimalist Google OAuth Authentication for Elixir Apps. Tested, Documented & Maintained. Setup in 5 mins. 🚀 - dwyl/elixir-auth-google - 349Visualize Erlang/Elixir Nodes On The Command Line
https://github.com/zhongwencool/observer_cliVisualize Erlang/Elixir Nodes On The Command Line. Contribute to zhongwencool/observer_cli development by creating an account on GitHub. - 350From Idea to Execution - Manage your trading operation across a distributed cluster
https://github.com/fremantle-industries/workbenchFrom Idea to Execution - Manage your trading operation across a distributed cluster - fremantle-industries/workbench - 351:watch: Cron-like job scheduler for Elixir
https://github.com/quantum-elixir/quantum-core:watch: Cron-like job scheduler for Elixir. Contribute to quantum-elixir/quantum-core development by creating an account on GitHub. - 352An authentication system generator for Phoenix 1.5 applications.
https://github.com/aaronrenner/phx_gen_authAn authentication system generator for Phoenix 1.5 applications. - aaronrenner/phx_gen_auth - 353AWS_MSK_IAM Authentication Plugin for Broadway Kafka
https://github.com/BigThinkcode/ex_aws_msk_iam_authAWS_MSK_IAM Authentication Plugin for Broadway Kafka - BigThinkcode/ex_aws_msk_iam_auth - 354💠 BPE: BPMN Process Engine ISO 19510
https://github.com/spawnproc/bpe💠 BPE: BPMN Process Engine ISO 19510. Contribute to synrc/bpe development by creating an account on GitHub. - 355Runtime and debugging tools for elixir
https://github.com/liveforeverx/exrunRuntime and debugging tools for elixir. Contribute to liveforeverx/exrun development by creating an account on GitHub. - 356Elixir State machine thin layer for structs
https://github.com/joaomdmoura/machineryElixir State machine thin layer for structs. Contribute to joaomdmoura/machinery development by creating an account on GitHub. - 357Hush is a runtime configuration loader for Elixir applications
https://github.com/gordalina/hushHush is a runtime configuration loader for Elixir applications - gordalina/hush - 358tzdata for Elixir. Born from the Calendar library.
https://github.com/lau/tzdatatzdata for Elixir. Born from the Calendar library. - lau/tzdata - 359an elixir library for dealing with bittorrent tracker requests and responses
https://github.com/alehander42/tracker_requestan elixir library for dealing with bittorrent tracker requests and responses - alehander92/tracker_request - 360A simple github oauth library
https://github.com/lidashuang/github_oauthA simple github oauth library. Contribute to defp/github_oauth development by creating an account on GitHub. - 361The ESTree Nodes and JavaScript AST to JavaScript Code Generator in Elixir
https://github.com/bryanjos/elixir-estreeThe ESTree Nodes and JavaScript AST to JavaScript Code Generator in Elixir - elixirscript/elixir-estree - 362Sorted Set library for Elixir
https://github.com/SenecaSystems/sorted_setSorted Set library for Elixir. Contribute to tyre/sorted_set development by creating an account on GitHub. - 363A* graph pathfinding in pure Elixir
https://github.com/herenowcoder/eastarA* graph pathfinding in pure Elixir. Contribute to wkhere/eastar development by creating an account on GitHub. - 364**DEPRECATED** caching made fun!
https://github.com/SpotIM/gen_spoxy**DEPRECATED** caching made fun! Contribute to OpenWeb-Archive/gen_spoxy development by creating an account on GitHub. - 365Add swagger compliant documentation to your maru API
https://github.com/falood/maru_swaggerAdd swagger compliant documentation to your maru API - elixir-maru/maru_swagger - 366Boot an Elixir application step by step (inspired by RabbitMQ)
https://github.com/eraserewind/booterBoot an Elixir application step by step (inspired by RabbitMQ) - hrefhref/booter - 367Elixir Plug to easily add HTTP basic authentication to an app
https://github.com/CultivateHQ/basic_authElixir Plug to easily add HTTP basic authentication to an app - paulanthonywilson/basic_auth - 368Apache httpasswd file reader/writer in Elixir
https://github.com/kevinmontuori/Apache.htpasswdApache httpasswd file reader/writer in Elixir. Contribute to bunnylushington/Apache.htpasswd development by creating an account on GitHub. - 369Elixir OpenAi Client
https://github.com/noizu-labs/elixir-openaiElixir OpenAi Client. Contribute to noizu-labs-ml/elixir-openai development by creating an account on GitHub. - 370♾️ ACTIVE: Filesystem Activities
https://github.com/synrc/active♾️ ACTIVE: Filesystem Activities. Contribute to 5HT/active development by creating an account on GitHub. - 371Connection behaviour for connection processes
https://github.com/fishcakez/connectionConnection behaviour for connection processes. Contribute to elixir-ecto/connection development by creating an account on GitHub. - 372XCribe is a doc generator for Rest APIs built with Phoenix. The documentation is generated by the test specs.
https://github.com/brainn-co/xcribeXCribe is a doc generator for Rest APIs built with Phoenix. The documentation is generated by the test specs. - Danielwsx64/xcribe - 373vk.com OAuth2 Strategy for Überauth.
https://github.com/sobolevn/ueberauth_vkvk.com OAuth2 Strategy for Überauth. Contribute to ueberauth/ueberauth_vk development by creating an account on GitHub. - 374An implementation of JSON-LD for Elixir
https://github.com/marcelotto/jsonld-exAn implementation of JSON-LD for Elixir. Contribute to rdf-elixir/jsonld-ex development by creating an account on GitHub. - 375BSON documents in Elixir language
https://github.com/ispirata/cyanideBSON documents in Elixir language. Contribute to secomind/cyanide development by creating an account on GitHub. - 376An implementation of RDF for Elixir
https://github.com/marcelotto/rdf-exAn implementation of RDF for Elixir. Contribute to rdf-elixir/rdf-ex development by creating an account on GitHub. - 377Use React template into your Elixir application for server rendering
https://github.com/awetzel/reaxtUse React template into your Elixir application for server rendering - kbrw/reaxt - 378An Elixir OAuth 2.0 Client Library
https://github.com/scrogson/oauth2An Elixir OAuth 2.0 Client Library. Contribute to ueberauth/oauth2 development by creating an account on GitHub. - 379An implementation of SPARQL for Elixir
https://github.com/marcelotto/sparql-exAn implementation of SPARQL for Elixir. Contribute to rdf-elixir/sparql-ex development by creating an account on GitHub. - 380Monads and other dark magic for Elixir
https://github.com/expede/witchcraftMonads and other dark magic for Elixir. Contribute to witchcrafters/witchcraft development by creating an account on GitHub. - 381A composable, real time, market data and trade execution toolkit. Built with Elixir, runs on the Erlang virtual machine
https://github.com/fremantle-capital/taiA composable, real time, market data and trade execution toolkit. Built with Elixir, runs on the Erlang virtual machine - fremantle-industries/tai - 382An OTP Process Pool Application
https://github.com/seth/poolerAn OTP Process Pool Application. Contribute to epgsql/pooler development by creating an account on GitHub. - 383Deployment for Elixir and Erlang
https://github.com/boldpoker/edeliverDeployment for Elixir and Erlang. Contribute to edeliver/edeliver development by creating an account on GitHub. - 384Easy and extensible benchmarking in Elixir providing you with lots of statistics!
https://github.com/PragTob/bencheeEasy and extensible benchmarking in Elixir providing you with lots of statistics! - bencheeorg/benchee - 385Prometheus - Monitoring system & time series database
https://prometheus.ioAn open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach. - 386image64
https://hex.pm/packages/image64A tool for working with base64 encoded images - 387Project management for all your teams
https://www.jetbrains.com/youtrack/Everything in one place. Track tasks, manage projects, maintain a knowledge base, support your customers, collaborate, and deliver great products. Designed with every member of your team in mind. Free for teams of up to 10. In our cloud or on your server. - 388pop3mail
https://hex.pm/packages/pop3mailPop3 client to download email (including attachments) from the inbox. Decodes multipart content, quoted-printables, base64 and encoded-words. Uses an Erlang pop - 389turn_the_page
https://hex.pm/packages/turn_the_pageFast, simple and lightweight pagination system for your Elixir application. - 390notifier
https://hex.pm/packages/notifierOSX notifications in a pluggable architecture for other kinds of notifications. - 391Application Monitoring & Error Tracking for Developers
https://www.honeybadger.io/.Full-stack application monitoring and error tracking that helps small teams move fast and fix things. - 392skribbl - Free Multiplayer Drawing & Guessing Game
https://skribbl.io/skribbl io is a free multiplayer drawing and guessing game. Draw and guess words with your friends and people all around the world! Score the most points and be the winner! - 393Dan McGuire / texas · GitLab
https://gitlab.com/dgmcguire/texasTexas is a powerful abstraction over updating your clients using server-side rendering and server-side Virtual DOM diff/patching. Embrace better abstractions that allow you to stop writing impossibly complex... - 394Cizen / Cizen · GitLab
https://gitlab.com/cizen/cizenBuild highly concurrent, monitorable, and extensible applications with a collection of automata. - 395Mike Chmielewski / rollex · GitLab
https://gitlab.com/olhado/rollexGitLab.com - 396Tailwind CSS Phoenix (Elixir) - Flowbite
https://flowbite.com/docs/getting-started/phoenix/Learn how to install Flowbite with Phoenix and Tailwind CSS to start building rich and interactive web applications based on the Elixir programming language - 397Home
https://rollbar.com/.Rollbar provides real-time error tracking & debugging tools for developers. ✓ JavaScript ✓PHP ✓Ruby ✓Python ✓Java ✓Android ✓iOS ✓.NET & more. - 398Phoenix Admin Panel built with PETAL · Backpex
https://backpex.live/.Backpex is a highly customizable admin panel for Phoenix LiveView apps. Production-ready, beautiful CRUD views in minutes, extend with ease. - 399A tutorial for shooting fault-tolerant portals for distributed data-transfer application in Elixir
https://github.com/josevalim/portalA tutorial for shooting fault-tolerant portals for distributed data-transfer application in Elixir - josevalim/portal - 400📨🔥 Elixir burner email (temporary address) detector
https://github.com/Betree/burnex📨🔥 Elixir burner email (temporary address) detector - Betree/burnex - 401Changelog is news and podcast for developers. This is our open source platform.
https://github.com/thechangelog/changelog.comChangelog is news and podcast for developers. This is our open source platform. - thechangelog/changelog.com - 402Compose, deliver and test your emails easily in Elixir
https://github.com/swoosh/swooshCompose, deliver and test your emails easily in Elixir - swoosh/swoosh - 403Notification dispatch library for Elixir applications
https://github.com/acutario/ravenxNotification dispatch library for Elixir applications - acutario/ravenx - 404Elixir library for waiting for things to happen
https://github.com/jvoegele/wait_for_itElixir library for waiting for things to happen. Contribute to jvoegele/wait_for_it development by creating an account on GitHub. - 405Tiny OTP application for feature toggles.
https://github.com/leorog/quarantineTiny OTP application for feature toggles. Contribute to leorog/quarantine development by creating an account on GitHub. - 406Monitor, Debug and Improve Your Entire Stack
https://newrelic.com/.Sign up for free, no credit card required. Get Instant Observability with New Relic One and Quickstarts that make it easy to instrument in a few clicks. - 407A very simple (and barely-functioning) Ruby runner for Elixir
https://github.com/YellowApple/RubixA very simple (and barely-functioning) Ruby runner for Elixir - YellowApple/Rubix - 408Elixir learning exercises
https://github.com/elixirkoans/elixir-koansElixir learning exercises. Contribute to elixirkoans/elixir-koans development by creating an account on GitHub. - 409:ets.fun2ms for Elixir, translate functions to match specifications
https://github.com/ericmj/ex2ms:ets.fun2ms for Elixir, translate functions to match specifications - ericmj/ex2ms - 410An Elixir library for generating GitHub-like identicons
https://github.com/rbishop/identiconAn Elixir library for generating GitHub-like identicons - rbishop/identicon - 411Elixir RSS/Atom parser
https://github.com/umurgdk/elixir-feedmeElixir RSS/Atom parser. Contribute to umurgdk/elixir-feedme development by creating an account on GitHub. - 412🎱 Logger backend app for Loggly requests
https://github.com/pragmaticivan/logglix🎱 Logger backend app for Loggly requests. Contribute to pragmaticivan/logglix development by creating an account on GitHub. - 413API server and website for Hex
https://github.com/hexpm/hexpmAPI server and website for Hex. Contribute to hexpm/hexpm development by creating an account on GitHub. - 414RabbitMQ adapter for Phoenix's PubSub layer
https://github.com/pma/phoenix_pubsub_rabbitmqRabbitMQ adapter for Phoenix's PubSub layer. Contribute to pma/phoenix_pubsub_rabbitmq development by creating an account on GitHub. - 415Backpex is a highly customizable administration panel for Phoenix LiveView applications.
https://github.com/naymspace/backpexBackpex is a highly customizable administration panel for Phoenix LiveView applications. - naymspace/backpex - 416Streaming encoder for JSON in elixir.
https://github.com/TreyE/json_stream_encoderStreaming encoder for JSON in elixir. Contribute to TreyE/json_stream_encoder development by creating an account on GitHub. - 417Build composable mail messages
https://github.com/DockYard/elixir-mailBuild composable mail messages. Contribute to DockYard/elixir-mail development by creating an account on GitHub. - 418Yet another library to handle JSON in Elixir.
https://github.com/meh/jazzYet another library to handle JSON in Elixir. Contribute to meh/jazz development by creating an account on GitHub. - 419Prometheus.erl Elixir Plugs
https://github.com/deadtrickster/prometheus-plugsPrometheus.erl Elixir Plugs. Contribute to deadtrickster/prometheus-plugs development by creating an account on GitHub. - 420Elegant error/exception handling in Elixir, with result monads.
https://github.com/CrowdHailer/OKElegant error/exception handling in Elixir, with result monads. - CrowdHailer/OK - 421LINQ-like match_spec generation for Elixir.
https://github.com/meh/exquisiteLINQ-like match_spec generation for Elixir. Contribute to meh/exquisite development by creating an account on GitHub. - 422Google Distance Matrix API Library for Elixir
https://github.com/C404/distance-matrix-apiGoogle Distance Matrix API Library for Elixir. Contribute to C404/distance-matrix-api development by creating an account on GitHub. - 423Easily define multiple function heads in elixir
https://github.com/pragdave/mdefEasily define multiple function heads in elixir. Contribute to pragdave/mdef development by creating an account on GitHub. - 424Plug support for Absinthe, the GraphQL toolkit for Elixir
https://github.com/absinthe-graphql/absinthe_plugPlug support for Absinthe, the GraphQL toolkit for Elixir - absinthe-graphql/absinthe_plug - 425A printf / sprintf library for Elixir. It works as a wrapper for :io.format.
https://github.com/parroty/exprintfA printf / sprintf library for Elixir. It works as a wrapper for :io.format. - parroty/exprintf - 426An Elixir Plug to add CORS.
https://github.com/mschae/cors_plugAn Elixir Plug to add CORS. Contribute to mschae/cors_plug development by creating an account on GitHub. - 427OOP in Elixir!
https://github.com/wojtekmach/oopOOP in Elixir! Contribute to wojtekmach/oop development by creating an account on GitHub. - 428An Elixir client for the Nu HTML Checker (v.Nu).
https://github.com/angelikatyborska/vnu-elixirAn Elixir client for the Nu HTML Checker (v.Nu). Contribute to angelikatyborska/vnu-elixir development by creating an account on GitHub. - 429Application template for SPAs with Phoenix, React and Redux
https://github.com/bigardone/phoenix-react-redux-templateApplication template for SPAs with Phoenix, React and Redux - bigardone/phoenix-react-redux-template - 430Filename sanitization for Elixir
https://github.com/ricn/zarexFilename sanitization for Elixir. Contribute to ricn/zarex development by creating an account on GitHub. - 431CRUD utilities for Phoenix and Ecto
https://github.com/bitgamma/crudexCRUD utilities for Phoenix and Ecto. Contribute to bitgamma/crudex development by creating an account on GitHub. - 432OBSOLETE - A VerneMQ/MQTT pubsub adapter for the Phoenix framework
https://github.com/larshesel/phoenix_pubsub_vernemqOBSOLETE - A VerneMQ/MQTT pubsub adapter for the Phoenix framework - larshesel/phoenix_pubsub_vernemq - 433An elixir framework to implement concurrent versions of common unix utilities, grep, find, etc..
https://github.com/bbense/elixgrepAn elixir framework to implement concurrent versions of common unix utilities, grep, find, etc.. - bbense/elixgrep - 434An elixir wrapper around the GeoNames API
https://github.com/pareeohnos/geonames-elixirAn elixir wrapper around the GeoNames API. Contribute to pareeohnos/geonames-elixir development by creating an account on GitHub. - 435Lightweight Elixir wrapper for Pandoc. Convert Markdown, CommonMark, HTML, Latex... to HTML, HTML5, opendocument, rtf, texttile, asciidoc, markdown, json and others
https://github.com/filterkaapi/pandexLightweight Elixir wrapper for Pandoc. Convert Markdown, CommonMark, HTML, Latex... to HTML, HTML5, opendocument, rtf, texttile, asciidoc, markdown, json and others - FilterKaapi/pandex - 436A module for working with LDAP from Elixir
https://github.com/jmerriweather/exldapA module for working with LDAP from Elixir. Contribute to jmerriweather/exldap development by creating an account on GitHub. - 437The enhanced elixir pipe operator which can specify the target position
https://github.com/taiansu/pipe_toThe enhanced elixir pipe operator which can specify the target position - taiansu/pipe_to - 438Generic Task behavior that helps encapsulate errors and recover from them in classic GenStage workers.
https://github.com/Nebo15/gen_taskGeneric Task behavior that helps encapsulate errors and recover from them in classic GenStage workers. - Nebo15/gen_task - 439🟪 AppSignal for Elixir package
https://github.com/appsignal/appsignal-elixir🟪 AppSignal for Elixir package. Contribute to appsignal/appsignal-elixir development by creating an account on GitHub. - 440Web application that indexes all popular torrent sites, and saves it to the local database.
https://github.com/sergiotapia/magnetissimoWeb application that indexes all popular torrent sites, and saves it to the local database. - sergiotapia/magnetissimo - 441gniquil/ex_minimatch
https://github.com/gniquil/ex_minimatchContribute to gniquil/ex_minimatch development by creating an account on GitHub. - 442Beautiful emails for your elixir application
https://github.com/jfrolich/smoothieBeautiful emails for your elixir application. Contribute to jfrolich/smoothie development by creating an account on GitHub. - 443🔥 NITRO: Nitrogen Web Framework RFC 6455
https://github.com/synrc/nitro🔥 NITRO: Nitrogen Web Framework RFC 6455. Contribute to synrc/nitro development by creating an account on GitHub. - 444the alchemist's happy path with elixir
https://github.com/vic/happythe alchemist's happy path with elixir. Contribute to vic/happy development by creating an account on GitHub. - 445Elixir/Erlang bindings for lexborisov's myhtml
https://github.com/Overbryd/myhtmlexElixir/Erlang bindings for lexborisov's myhtml. Contribute to Overbryd/myhtmlex development by creating an account on GitHub. - 446Elixir library to do pipeable transformations on html strings (with CSS selectors)
https://github.com/f34nk/modest_exElixir library to do pipeable transformations on html strings (with CSS selectors) - f34nk/modest_ex - 447US Address Parsing for Elixir.
https://github.com/smashedtoatoms/address_usUS Address Parsing for Elixir. Contribute to smashedtoatoms/address_us development by creating an account on GitHub. - 448Redirect http to https behind a load balancer (or other reverse proxy).
https://github.com/stocks29/plug_redirect_httpsRedirect http to https behind a load balancer (or other reverse proxy). - stocks29/plug_redirect_https - 449Plug for JWT authentication
https://github.com/bryanjos/plug_jwtPlug for JWT authentication. Contribute to bryanjos/plug_jwt development by creating an account on GitHub. - 450Elli elixir wrapper with some sugar sytnax goodies.
https://github.com/pigmej/exelliElli elixir wrapper with some sugar sytnax goodies. - pigmej/exelli - 451A mix task for creating new projects based on templates fetched from a Git-repo
https://github.com/gausby/scaffoldA mix task for creating new projects based on templates fetched from a Git-repo - gausby/scaffold - 452Elixir library to build Plug-like pipelines
https://github.com/mruoss/pluggableElixir library to build Plug-like pipelines. Contribute to mruoss/pluggable development by creating an account on GitHub. - 453HTTP Router with various macros to assist in developing your application and organizing your code
https://github.com/sugar-framework/elixir-http-routerHTTP Router with various macros to assist in developing your application and organizing your code - sugar-framework/elixir-http-router - 454A multi mars rover implementation in Elixir.
https://github.com/emadb/rovexA multi mars rover implementation in Elixir. . Contribute to emadb/rovex development by creating an account on GitHub. - 455Basic Access Authentication in Plug applications
https://github.com/lexmag/blaguthBasic Access Authentication in Plug applications. Contribute to lexmag/blaguth development by creating an account on GitHub. - 456Docs for the entice project
https://github.com/entice/enticeDocs for the entice project. Contribute to entice/entice development by creating an account on GitHub. - 457Peace of mind from prototype to production
https://github.com/phoenixframework/phoenixPeace of mind from prototype to production. Contribute to phoenixframework/phoenix development by creating an account on GitHub. - 458Segment-segment intersection classifier and calculator for Elixir
https://github.com/pkinney/segseg_exSegment-segment intersection classifier and calculator for Elixir - pkinney/segseg_ex - 459Simple, robust and performant Erlang web server
https://github.com/knutin/elliSimple, robust and performant Erlang web server. Contribute to knutin/elli development by creating an account on GitHub. - 460☕ REST: RFC-2616 Framework
https://github.com/synrc/rest☕ REST: RFC-2616 Framework. Contribute to synrc/rest development by creating an account on GitHub. - 461Wrapper for feeder. Elixir RSS parser
https://github.com/manukall/feeder_exWrapper for feeder. Elixir RSS parser. Contribute to manukall/feeder_ex development by creating an account on GitHub. - 462Library for editing bitmap files
https://github.com/evanfarrar/ex_bumpLibrary for editing bitmap files. Contribute to evanfarrar/ex_bump development by creating an account on GitHub. - 463Store your plug sessions in memcached
https://github.com/gutschilla/plug-session-memcachedStore your plug sessions in memcached. Contribute to gutschilla/plug-session-memcached development by creating an account on GitHub. - 464HTTP web server and client, supports http1 and http2
https://github.com/CrowdHailer/AceHTTP web server and client, supports http1 and http2 - CrowdHailer/Ace - 465Postmark adapter for sending template emails in Elixir
https://github.com/KamilLelonek/ex_postmarkPostmark adapter for sending template emails in Elixir - KamilLelonek/ex_postmark - 466A pure Erlang library for creating PNG images. It can currently create 8 and 16 bit RGB, RGB with alpha, indexed, grayscale and grayscale with alpha images.
https://github.com/yuce/pngA pure Erlang library for creating PNG images. It can currently create 8 and 16 bit RGB, RGB with alpha, indexed, grayscale and grayscale with alpha images. - yuce/png - 467Elixir binding to the granddaddy of HTML tools
https://github.com/f34nk/tidy_exElixir binding to the granddaddy of HTML tools. Contribute to f34nk/tidy_ex development by creating an account on GitHub. - 468Set up an Elixir Plug application with less boilerplate.
https://github.com/henrik/plug_and_playSet up an Elixir Plug application with less boilerplate. - henrik/plug_and_play - 469The clone of lolcat. written in elixir
https://github.com/restartr/ex-lolcatThe clone of lolcat. written in elixir. Contribute to ReSTARTR/ex-lolcat development by creating an account on GitHub. - 470Elixir library to create thumbnails from images and video screenshots.
https://github.com/talklittle/thumbnexElixir library to create thumbnails from images and video screenshots. - talklittle/thumbnex - 471An Elixir library for generating SVG images
https://github.com/mmmries/chunky_svgAn Elixir library for generating SVG images. Contribute to mmmries/chunky_svg development by creating an account on GitHub. - 472Make your plug pipeline act more enterprisey...
https://github.com/Frost/resinMake your plug pipeline act more enterprisey... Contribute to Frost/resin development by creating an account on GitHub. - 473Elixir binding for libgraphqlparser
https://github.com/graphql-elixir/graphql_parserElixir binding for libgraphqlparser. Contribute to graphql-elixir/graphql_parser development by creating an account on GitHub. - 474Help applications kill themselves
https://github.com/rubencaro/harakiriHelp applications kill themselves . Contribute to rubencaro/harakiri development by creating an account on GitHub. - 475The Redis PubSub adapter for the Phoenix framework
https://github.com/phoenixframework/phoenix_pubsub_redisThe Redis PubSub adapter for the Phoenix framework - phoenixframework/phoenix_pubsub_redis - 476A command line weather app built using elixir
https://github.com/tacticiankerala/elixir-weatherA command line weather app built using elixir. Contribute to tacticiankerala/elixir-weather development by creating an account on GitHub. - 477Airbrake reporter for Elixir's Plug (DEPRECATED in favor of https://github.com/romul/airbrake-elixir)
https://github.com/romul/airbrake_plugAirbrake reporter for Elixir's Plug (DEPRECATED in favor of https://github.com/romul/airbrake-elixir) - GitHub - romul/airbrake_plug: Airbrake reporter for Elixir's Plug (DEPRECATED in fav... - 478Roll the dice, in elixir
https://github.com/stocks29/diceRoll the dice, in elixir. Contribute to stocks29/dice development by creating an account on GitHub. - 479A butler plugin for Nick Cage photos
https://github.com/keathley/butler_cageA butler plugin for Nick Cage photos. Contribute to keathley/butler_cage development by creating an account on GitHub. - 480Simple Elixir file-system directory tree walker. It can handle large filesystems, as the tree is traversed lazily.
https://github.com/pragdave/dir_walkerSimple Elixir file-system directory tree walker. It can handle large filesystems, as the tree is traversed lazily. - GitHub - pragdave/dir_walker: Simple Elixir file-system directory tree walker. ... - 481A file watcher for Elixir language
https://github.com/ryo33/fwatch-exA file watcher for Elixir language. Contribute to ryo33/fwatch-ex development by creating an account on GitHub. - 482Phoenix Template Engine for Slime
https://github.com/slime-lang/phoenix_slimePhoenix Template Engine for Slime. Contribute to slime-lang/phoenix_slime development by creating an account on GitHub. - 483Elixir error messages to make the errors within the system easier to expect and predict, as well as read
https://github.com/MikaAK/elixir_error_messageElixir error messages to make the errors within the system easier to expect and predict, as well as read - GitHub - MikaAK/elixir_error_message: Elixir error messages to make the errors within the... - 484Adding youtrack as a logger backend to your elixir application.
https://github.com/unifysell/youtrack_logger_backendAdding youtrack as a logger backend to your elixir application. - unifysell/youtrack_logger_backend - 485NewRelic agent for Elixir
https://github.com/romul/newrelic.exNewRelic agent for Elixir. Contribute to romul/newrelic.ex development by creating an account on GitHub. - 486Elixir implementation of an interpreter for the Monkey programming language
https://github.com/fabrik42/writing_an_interpreter_in_elixirElixir implementation of an interpreter for the Monkey programming language - fabrik42/writing_an_interpreter_in_elixir - 487Configurable Elixir mix task to watch file changes and run the corresponding command.
https://github.com/rkotze/eye_dropsConfigurable Elixir mix task to watch file changes and run the corresponding command. - rkotze/eye_drops - 488An XML-RPC parser/formatter for Elixir, with full support for datatype mapping!
https://github.com/stevenschobert/weeboAn XML-RPC parser/formatter for Elixir, with full support for datatype mapping! - stevenschobert/weebo - 489Use Cloudflare Turnstile in Phoenix
https://github.com/jsonmaur/phoenix-turnstileUse Cloudflare Turnstile in Phoenix. Contribute to jsonmaur/phoenix-turnstile development by creating an account on GitHub. - 490HTML view helpers for Scrivener
https://github.com/mgwidmann/scrivener_htmlHTML view helpers for Scrivener. Contribute to mgwidmann/scrivener_html development by creating an account on GitHub. - 491An experiment with Phoenix Channels, GenEvents, React and Flux.
https://github.com/fxg42/phoenix-flux-reactAn experiment with Phoenix Channels, GenEvents, React and Flux. - fxg42/phoenix-flux-react - 492A simple & highly extendable, meta-notification system; Echo checks notification preferences & dispatch notifications to different adapters (ex. email, logger, analytics, sms, etc.).
https://github.com/zmoshansky/echoA simple & highly extendable, meta-notification system; Echo checks notification preferences & dispatch notifications to different adapters (ex. email, logger, analytics, sms, etc.). - zmos... - 493An Elixir client library for generating image URLs with imgix
https://github.com/ianwalter/imgexAn Elixir client library for generating image URLs with imgix - ianwalter/imgex - 494HTTP Digest Auth Library to create auth header to be used with HTTP Digest Authentication
https://github.com/techgaun/http_digexHTTP Digest Auth Library to create auth header to be used with HTTP Digest Authentication - techgaun/http_digex - 495An elixir wrapper for Open Notify's International Space Station API. http://open-notify.org/
https://github.com/cryptobird/ex_issAn elixir wrapper for Open Notify's International Space Station API. http://open-notify.org/ - dismae/ex_iss - 496An Elixir library for generating memorable slugs.
https://github.com/devshane/mnemonic_slugsAn Elixir library for generating memorable slugs. Contribute to devshane/mnemonic_slugs development by creating an account on GitHub. - 497Plug application and middleware that serves endpoint returns application's REVISION.
https://github.com/KazuCocoa/revision_plate_exPlug application and middleware that serves endpoint returns application's REVISION. - KazuCocoa/revision_plate_ex - 498Extensible Phoenix liveview components, without boilerplate
https://github.com/cblavier/phx_component_helpersExtensible Phoenix liveview components, without boilerplate - cblavier/phx_component_helpers - 499Elixir HTTP client, focused on performance
https://github.com/keathley/finchElixir HTTP client, focused on performance. Contribute to keathley/finch development by creating an account on GitHub. - 500HTTP server for Elixir
https://github.com/slogsdon/httpHTTP server for Elixir. Contribute to slogsdon/http development by creating an account on GitHub. - 501An alternative logger for Ecto queries
https://github.com/fuelen/ecto_dev_loggerAn alternative logger for Ecto queries. Contribute to fuelen/ecto_dev_logger development by creating an account on GitHub. - 502Gi is a library for manipulating Graphics Interfacing. Use utility mogrify, identify, ... of GraphicsMagick to resize, draw on base images....
https://github.com/LangPham/giGi is a library for manipulating Graphics Interfacing. Use utility mogrify, identify, ... of GraphicsMagick to resize, draw on base images.... - LangPham/gi - 503Elixir AppOptics client
https://github.com/sashman/app_optexElixir AppOptics client. Contribute to sashman/app_optex development by creating an account on GitHub. - 504:ribbon: Injects a ribbon into your web application depending on the environment
https://github.com/stnly/plug_ribbon:ribbon: Injects a ribbon into your web application depending on the environment - stnly/plug_ribbon - 505linguist integration functions into phoenix
https://github.com/jxs/phoenix_linguistlinguist integration functions into phoenix. Contribute to jxs/phoenix_linguist development by creating an account on GitHub. - 506parse transform for accurate line numbers
https://github.com/camshaft/lineoparse transform for accurate line numbers. Contribute to camshaft/lineo development by creating an account on GitHub. - 507A Gmail API client for Elixir
https://github.com/craigp/elixir-gmailA Gmail API client for Elixir. Contribute to craigp/elixir-gmail development by creating an account on GitHub. - 508Filesystem monitor for elixir
https://github.com/falood/exfswatchFilesystem monitor for elixir. Contribute to falood/file_system development by creating an account on GitHub. - 509Very simple plug which reads `X-Forwarded-For` or `Forwarded` header according to rfc7239 and fill `conn.remote_ip` with the root client ip.
https://github.com/awetzel/plug_forwarded_peerVery simple plug which reads `X-Forwarded-For` or `Forwarded` header according to rfc7239 and fill `conn.remote_ip` with the root client ip. - kbrw/plug_forwarded_peer - 510What used to be here -- this is a backwards-compat user and repo m(
https://github.com/talko/lhttpcWhat used to be here -- this is a backwards-compat user and repo m( - talko/lhttpc - 511Pure elixir library to extract tiff and exif metadata from jpeg files
https://github.com/pragdave/exexifPure elixir library to extract tiff and exif metadata from jpeg files - pragdave/exexif - 512Image Validator, Converter, and Uploader
https://github.com/elixir-ivcu/ivcuImage Validator, Converter, and Uploader. Contribute to elixir-ivcu/ivcu development by creating an account on GitHub. - 513Simple reCaptcha display/verify code for Elixir applications. Using Exrecaptcha with a CMS such as Phoenix is easy.
https://github.com/adanselm/exrecaptchaSimple reCaptcha display/verify code for Elixir applications. Using Exrecaptcha with a CMS such as Phoenix is easy. - adanselm/exrecaptcha - 514HTML Sanitizer for Phoenix
https://github.com/elixirstatus/phoenix_html_sanitizerHTML Sanitizer for Phoenix. Contribute to elixirstatus/phoenix_html_sanitizer development by creating an account on GitHub. - 515An Elixir Plug to verify HTTP requests signed with AWS Signature V4
https://github.com/handnot2/plug_sigawsAn Elixir Plug to verify HTTP requests signed with AWS Signature V4 - handnot2/plug_sigaws - 516Implementation of RFC 6901 which defines a string syntax for identifying a specific value within a JSON document
https://github.com/xavier/json_pointerImplementation of RFC 6901 which defines a string syntax for identifying a specific value within a JSON document - xavier/json_pointer - 517ExRated, the Elixir OTP GenServer with the naughty name that allows you to rate-limit calls to any service that requires it.
https://github.com/grempe/ex_ratedExRated, the Elixir OTP GenServer with the naughty name that allows you to rate-limit calls to any service that requires it. - grempe/ex_rated - 518A plug for responding to heartbeat requests.
https://github.com/whatyouhide/plug_heartbeatA plug for responding to heartbeat requests. Contribute to whatyouhide/plug_heartbeat development by creating an account on GitHub. - 519Flexible file upload and attachment library for Elixir
https://github.com/elixir-waffle/waffleFlexible file upload and attachment library for Elixir - elixir-waffle/waffle - 520PlugCanonicalHost ensures that all requests are served by a single canonical host.
https://github.com/remiprev/plug_canonical_hostPlugCanonicalHost ensures that all requests are served by a single canonical host. - remi/plug_canonical_host - 521Search, Sort and Pagination for ecto queries
https://github.com/Excipients/rummage_ectoSearch, Sort and Pagination for ecto queries. Contribute to annkissam/rummage_ecto development by creating an account on GitHub. - 522Ivar is an adapter based HTTP client that provides the ability to build composable HTTP requests.
https://github.com/swelham/ivarIvar is an adapter based HTTP client that provides the ability to build composable HTTP requests. - swelham/ivar - 523Mailman provides a clean way of defining mailers in your Elixir applications
https://github.com/kamilc/mailmanMailman provides a clean way of defining mailers in your Elixir applications - mailman-elixir/mailman - 524📁 FS: Windows, Linux, Mac Driver
https://github.com/synrc/fs📁 FS: Windows, Linux, Mac Driver. Contribute to 5HT/fs development by creating an account on GitHub. - 525Graphite client for Elixir
https://github.com/msoedov/graphitexGraphite client for Elixir. Contribute to msoedov/graphitex development by creating an account on GitHub. - 526An elixir plug to support legacy APIs that use a rails-like trailing format: http://api.dev/resources.json
https://github.com/mschae/trailing_format_plugAn elixir plug to support legacy APIs that use a rails-like trailing format: http://api.dev/resources.json - mschae/trailing_format_plug - 527Authentication module for Plug applications
https://github.com/sajmoon/mellonAuthentication module for Plug applications. Contribute to sajmoon/mellon development by creating an account on GitHub. - 528Small exercises to discover elixir by testing
https://github.com/dojo-toulouse/elixir-koansSmall exercises to discover elixir by testing. Contribute to dojo-toulouse/elixir-koans development by creating an account on GitHub. - 529Flipping tables with butler
https://github.com/keathley/butler_tableflipFlipping tables with butler. Contribute to keathley/butler_tableflip development by creating an account on GitHub. - 530Find Russian and Ukraine city by IP address and find country for other country Elixir
https://github.com/sergey-chechaev/elixir_ipgeobaseFind Russian and Ukraine city by IP address and find country for other country Elixir - sergey-chechaev/elixir_ipgeobase - 531Simple plug to secure your server with password
https://github.com/azranel/plug_passwordSimple plug to secure your server with password. Contribute to azranel/plug_password development by creating an account on GitHub. - 532I wonder what kind of Elixir is boiling in there.
https://github.com/meh/cauldronI wonder what kind of Elixir is boiling in there. Contribute to meh/cauldron development by creating an account on GitHub. - 533Eikōn is an Elixir library providing a read-only interface for image files.
https://github.com/tchoutri/EikonEikōn is an Elixir library providing a read-only interface for image files. - tchoutri/Eikon - 534Elixir Plug to manipulate HTTP response headers
https://github.com/c-rack/plug_response_headerElixir Plug to manipulate HTTP response headers. Contribute to c-rack/plug_response_header development by creating an account on GitHub. - 535An Elixir macro for easily piping arguments at any position.
https://github.com/vic/pipe_hereAn Elixir macro for easily piping arguments at any position. - vic/pipe_here - 536JWT.IO
http://jwt.io/.JSON Web Tokens are an open, industry standard RFC 7519 method for representing claims securely between two parties. - 537File upload persistence and processing for Phoenix / Plug
https://github.com/keichan34/exfileFile upload persistence and processing for Phoenix / Plug - keichan34/exfile - 538An Elixir library to make File Sizes human-readable
https://github.com/arvidkahl/sizeableAn Elixir library to make File Sizes human-readable - arvidkahl/sizeable - 539coderplanets.com API(GraphQL) server, build with elixir, phoenix, absinthe
https://github.com/coderplanets/coderplanets_servercoderplanets.com API(GraphQL) server, build with elixir, phoenix, absinthe - coderplanets/coderplanets_server - 540Use Commanded to build Elixir CQRS/ES applications
https://github.com/slashdotdash/commandedUse Commanded to build Elixir CQRS/ES applications - commanded/commanded - 541jsx but with maps for people who are into that kind of thing
https://github.com/talentdeficit/jsxnjsx but with maps for people who are into that kind of thing - talentdeficit/jsxn - 542Allows named arg style arguments in Elixir
https://github.com/mgwidmann/named_argsAllows named arg style arguments in Elixir. Contribute to mgwidmann/named_args development by creating an account on GitHub. - 543Pagination for Ecto and Pheonix.
https://github.com/elixirdrops/kerosenePagination for Ecto and Pheonix. Contribute to elixirdrops/kerosene development by creating an account on GitHub. - 544Phoenix Template Engine for Haml
https://github.com/chrismccord/phoenix_hamlPhoenix Template Engine for Haml. Contribute to chrismccord/phoenix_haml development by creating an account on GitHub. - 545The anaphoric macro collection for Elixir
https://github.com/sviridov/anaphora-elixirThe anaphoric macro collection for Elixir. Contribute to sviridov/anaphora-elixir development by creating an account on GitHub. - 546A JWT encoding and decoding library in Elixir
https://github.com/mschae/jwtexA JWT encoding and decoding library in Elixir. Contribute to mschae/jwtex development by creating an account on GitHub. - 547Exemplary real world application built with Elixir + Phoenix
https://github.com/gothinkster/elixir-phoenix-realworld-example-appExemplary real world application built with Elixir + Phoenix - gothinkster/elixir-phoenix-realworld-example-app - 548Send connection response time and count to statsd
https://github.com/jeffweiss/plug_statsdSend connection response time and count to statsd. Contribute to jeffweiss/plug_statsd development by creating an account on GitHub. - 549Simple Elixir implementation of a jsonapi.org server.
https://github.com/AgilionApps/relaxSimple Elixir implementation of a jsonapi.org server. - AgilionApps/relax - 550Rails compatible Plug session store
https://github.com/cconstantin/plug_rails_cookie_session_storeRails compatible Plug session store. Contribute to cconstantin/plug_rails_cookie_session_store development by creating an account on GitHub. - 551Plug that adds various HTTP Headers to make Phoenix/Elixir app more secure
https://github.com/techgaun/plug_secexPlug that adds various HTTP Headers to make Phoenix/Elixir app more secure - techgaun/plug_secex - 552An Elixir Plug for requiring and extracting a given header.
https://github.com/DevL/plug_require_headerAn Elixir Plug for requiring and extracting a given header. - DevL/plug_require_header - 553An Elixir library for non-strict parsing, manipulation, and wildcard matching of URLs.
https://github.com/gamache/fuzzyurl.exAn Elixir library for non-strict parsing, manipulation, and wildcard matching of URLs. - gamache/fuzzyurl.ex - 554Ensure backwards compatibility even if newer functions are used
https://github.com/leifg/backportsEnsure backwards compatibility even if newer functions are used - leifg/backports - 555Reactive Extensions for Elixir
https://github.com/alfert/reaxiveReactive Extensions for Elixir. Contribute to alfert/reaxive development by creating an account on GitHub. - 556Postgresql PubSub adapter for Phoenix apps
https://github.com/opendrops/phoenix-pubsub-postgresPostgresql PubSub adapter for Phoenix apps. Contribute to shankardevy/phoenix-pubsub-postgres development by creating an account on GitHub. - 557The extensible Erlang SMTP client and server library.
https://github.com/Vagabond/gen_smtpThe extensible Erlang SMTP client and server library. - gen-smtp/gen_smtp - 558Building blocks for working with HTML in Phoenix
https://github.com/phoenixframework/phoenix_htmlBuilding blocks for working with HTML in Phoenix. Contribute to phoenixframework/phoenix_html development by creating an account on GitHub. - 559A small, fast and fully compliant JSON parser in Elixir
https://github.com/whitfin/tinyA small, fast and fully compliant JSON parser in Elixir - whitfin/tiny - 560MochiWeb is an Erlang library for building lightweight HTTP servers.
https://github.com/mochi/mochiwebMochiWeb is an Erlang library for building lightweight HTTP servers. - mochi/mochiweb - 561WebSocket client library written in pure Elixir
https://github.com/narrowtux/TubeWebSocket client library written in pure Elixir. Contribute to narrowtux/Tube development by creating an account on GitHub. - 562Parses CloudFlare's CF-Connecting-IP header into Plug.Conn's remote_ip field.
https://github.com/c-rack/plug_cloudflareParses CloudFlare's CF-Connecting-IP header into Plug.Conn's remote_ip field. - c-rack/plug_cloudflare - 563Query locations for elevation data from the NASA Shuttle Radar Topography Mission
https://github.com/adriankumpf/srtmQuery locations for elevation data from the NASA Shuttle Radar Topography Mission - adriankumpf/srtm - 564Elixir logger to publish log messages in RabbitMQ
https://github.com/duartejc/roggerElixir logger to publish log messages in RabbitMQ. Contribute to duartejc/rogger development by creating an account on GitHub. - 565HTTP/1.1, HTTP/2, Websocket client (and more) for Erlang/OTP.
https://github.com/ninenines/gunHTTP/1.1, HTTP/2, Websocket client (and more) for Erlang/OTP. - ninenines/gun - 566Picture guessing and drawing multiplayer game
https://github.com/Arp-G/pictionaryPicture guessing and drawing multiplayer game. Contribute to Arp-G/pictionary development by creating an account on GitHub. - 567PlugCheckup provides a Plug for adding simple health checks to your app
https://github.com/ggpasqualino/plug_checkupPlugCheckup provides a Plug for adding simple health checks to your app - ggpasqualino/plug_checkup - 568Prometheus.io process collector in Erlang
https://github.com/deadtrickster/prometheus_process_collectorPrometheus.io process collector in Erlang. Contribute to deadtrickster/prometheus_process_collector development by creating an account on GitHub. - 569Chat anonymously with a randomly chosen stranger
https://github.com/cazrin/strangerChat anonymously with a randomly chosen stranger. Contribute to dnlgrv/stranger development by creating an account on GitHub. - 570antp/mailer
https://github.com/antp/mailerContribute to antp/mailer development by creating an account on GitHub. - 571Library containing Email related implementations in Elixir : dkim, spf, dmark, mimemail, smtp
https://github.com/awetzel/mailibexLibrary containing Email related implementations in Elixir : dkim, spf, dmark, mimemail, smtp - kbrw/mailibex - 572Macros expanding into code that can be safely used in guard clauses.
https://github.com/DevL/guardsafeMacros expanding into code that can be safely used in guard clauses. - DevL/guardsafe - 573Elixir library for dealing with CORS requests. 🏖
https://github.com/whatyouhide/corsicaElixir library for dealing with CORS requests. 🏖. Contribute to whatyouhide/corsica development by creating an account on GitHub. - 574:traffic_light: Feature flipping for the Elixir world
https://github.com/sorentwo/flippant:traffic_light: Feature flipping for the Elixir world - sorentwo/flippant - 575Cleaner request parameters in Elixir web applications 🙌
https://github.com/sheharyarn/better_paramsCleaner request parameters in Elixir web applications 🙌 - sheharyarn/better_params - 576Generic feed adding social features to current applications.
https://github.com/erneestoc/feedxGeneric feed adding social features to current applications. - GitHub - erneestoc/feedx: Generic feed adding social features to current applications. - 577Elixir library to convert office documents to other formats using LibreOffice.
https://github.com/ricn/librexElixir library to convert office documents to other formats using LibreOffice. - ricn/librex - 578Phoenix library helps generating meta tags for website.
https://github.com/hlongvu/phoenix_meta_tagsPhoenix library helps generating meta tags for website. - hlongvu/phoenix_meta_tags - 579IP information lookup provider
https://github.com/mneudert/geolixIP information lookup provider. Contribute to elixir-geolix/geolix development by creating an account on GitHub. - 580A Bugsnag notifier for Elixir's plug
https://github.com/jarednorman/plugsnagA Bugsnag notifier for Elixir's plug. Contribute to bugsnag-elixir/plugsnag development by creating an account on GitHub. - 581Prometheus.io Phoenix instrumenter
https://github.com/deadtrickster/prometheus-phoenixPrometheus.io Phoenix instrumenter. Contribute to deadtrickster/prometheus-phoenix development by creating an account on GitHub. - 582Scrape any website, article or RSS/Atom Feed with ease!
https://github.com/Anonyfox/elixir-scrapeScrape any website, article or RSS/Atom Feed with ease! - Anonyfox/elixir-scrape - 583Plug (Phoenix) integration for GraphQL Elixir
https://github.com/graphql-elixir/plug_graphqlPlug (Phoenix) integration for GraphQL Elixir . Contribute to graphql-elixir/plug_graphql development by creating an account on GitHub. - 584Geohash encoding and decoding for Elixir.
https://github.com/evuez/geohaxGeohash encoding and decoding for Elixir. Contribute to evuez/geohax development by creating an account on GitHub. - 585Time zone by geo coordinates lookup
https://github.com/UA3MQJ/wheretzTime zone by geo coordinates lookup. Contribute to UA3MQJ/wheretz development by creating an account on GitHub. - 586Functions with syntax for keyword arguments and defaults
https://github.com/RobertDober/lab42_defkwFunctions with syntax for keyword arguments and defaults - RobertDober/lab42_defkw - 587Client to thumbor using Elixir
https://github.com/globocom/thumbor-client-exClient to thumbor using Elixir. Contribute to globocom/thumbor-client-ex development by creating an account on GitHub. - 588A simple reCaptcha 2 library for Elixir applications.
https://github.com/samueljseay/recaptchaA simple reCaptcha 2 library for Elixir applications. - samueljseay/recaptcha - 589Elixir NIF for Geohash C Library
https://github.com/wstucco/geohash_nif/Elixir NIF for Geohash C Library. Contribute to wstucco/geohash_nif development by creating an account on GitHub. - 590A collection of authentication-related plugs
https://github.com/bitgamma/plug_authA collection of authentication-related plugs. Contribute to bitgamma/plug_auth development by creating an account on GitHub. - 591HTML sanitizer for Elixir
https://github.com/rrrene/html_sanitize_exHTML sanitizer for Elixir. Contribute to rrrene/html_sanitize_ex development by creating an account on GitHub. - 592Application Monitoring for Ruby on Rails, Elixir, Node.js & Python
https://appsignal.com/.AppSignal APM offers error tracking, performance monitoring, dashboards, host metrics, and alerts. Built for Ruby, Ruby on Rails, Elixir, Node.js, and JavaScript. - 593elixir module for the world in geo.json
https://github.com/camshaft/world_json_exelixir module for the world in geo.json. Contribute to camshaft/world_json_ex development by creating an account on GitHub. - 594An Elixir Logger backend for GELF
https://github.com/jschniper/gelf_loggerAn Elixir Logger backend for GELF. Contribute to jschniper/gelf_logger development by creating an account on GitHub. - 595rebind parse transform for erlang
https://github.com/camshaft/rebindrebind parse transform for erlang. Contribute to camshaft/rebind development by creating an account on GitHub. - 596Simple convention and DSL for transformation of elixir functions to an API for later documentation and or validation.
https://github.com/liveforeverx/apixSimple convention and DSL for transformation of elixir functions to an API for later documentation and or validation. - liveforeverx/apix - 597A few elixir libraries for working with django
https://github.com/nicksanders/exdjangoA few elixir libraries for working with django. Contribute to nicksanders/exdjango development by creating an account on GitHub. - 598A cross-platform file watcher for Elixir based on fswatch.
https://github.com/whitfin/sentixA cross-platform file watcher for Elixir based on fswatch. - whitfin/sentix - 599A platform agnostic tracing library
https://github.com/spandex-project/spandexA platform agnostic tracing library. Contribute to spandex-project/spandex development by creating an account on GitHub. - 600⭕ N2O: Distributed WebSocket Application Server ISO 20922
https://github.com/synrc/n2o⭕ N2O: Distributed WebSocket Application Server ISO 20922 - synrc/n2o - 601Macros for more flexible composition with the Elixir Pipe operator
https://github.com/batate/elixir-pipesMacros for more flexible composition with the Elixir Pipe operator - batate/elixir-pipes - 602A simple to use shallow ETag plug
https://github.com/sascha-wolf/etag_plugA simple to use shallow ETag plug. Contribute to alexocode/etag_plug development by creating an account on GitHub. - 603ExGuard is a mix command to handle events on file system modifications
https://github.com/slashmili/ex_guardExGuard is a mix command to handle events on file system modifications - slashmili/ex_guard - 604Path library for Elixir inspired by Python's pathlib
https://github.com/lowks/RadpathPath library for Elixir inspired by Python's pathlib - lowks/Radpath - 605Inline SVG component for Phoenix
https://github.com/jsonmaur/phoenix-svgInline SVG component for Phoenix. Contribute to jsonmaur/phoenix-svg development by creating an account on GitHub. - 606Decode and encode Logfmt lines in Elixir
https://github.com/jclem/logfmt-elixirDecode and encode Logfmt lines in Elixir. Contribute to jclem/logfmt-elixir development by creating an account on GitHub. - 607Provides live-reload functionality for Phoenix
https://github.com/phoenixframework/phoenix_live_reloadProvides live-reload functionality for Phoenix. Contribute to phoenixframework/phoenix_live_reload development by creating an account on GitHub. - 608Pagination for the Elixir ecosystem
https://github.com/drewolson/scrivenerPagination for the Elixir ecosystem. Contribute to mojotech/scrivener development by creating an account on GitHub. - 609Scrivener pagination with headers and web linking
https://github.com/doomspork/scrivener_headersScrivener pagination with headers and web linking. Contribute to beam-community/scrivener_headers development by creating an account on GitHub. - 610TypedStructor is a library for defining structs with types effortlessly.
https://github.com/elixir-typed-structor/typed_structorTypedStructor is a library for defining structs with types effortlessly. - elixir-typed-structor/typed_structor - 611Elixir module for easier URI manipulation.
https://github.com/kemonomachi/yuriElixir module for easier URI manipulation. Contribute to kemonomachi/yuri development by creating an account on GitHub. - 612An Elixir library for the IP2Location database
https://github.com/nazipov/ip2location-elixirAn Elixir library for the IP2Location database. Contribute to nazipov/ip2location-elixir development by creating an account on GitHub. - 613A collection of Plug middleware for web applications
https://github.com/sugar-framework/plugsA collection of Plug middleware for web applications - sugar-framework/plugs - 614An easy utility for responding with standard HTTP/JSON error payloads in Plug- and Phoenix-based applications
https://github.com/pkinney/explodeAn easy utility for responding with standard HTTP/JSON error payloads in Plug- and Phoenix-based applications - pkinney/explode - 615Readability is Elixir library for extracting and curating articles.
https://github.com/keepcosmos/readabilityReadability is Elixir library for extracting and curating articles. - keepcosmos/readability - 616🧾 FORM: Business X-Forms
https://github.com/spawnproc/forms🧾 FORM: Business X-Forms. Contribute to synrc/form development by creating an account on GitHub. - 617An Elixir web micro-framework.
https://github.com/hexedpackets/trotAn Elixir web micro-framework. Contribute to hexedpackets/trot development by creating an account on GitHub. - 618Modular web framework for Elixir
https://github.com/sugar-framework/sugarModular web framework for Elixir. Contribute to sugar-framework/sugar development by creating an account on GitHub. - 619A raygun client for Elixir
https://github.com/cobenian/raygunA raygun client for Elixir. Contribute to Cobenian/raygun development by creating an account on GitHub. - 620Utilities for working with jsonc, a superset of json
https://github.com/massivefermion/jsoncUtilities for working with jsonc, a superset of json - massivefermion/jsonc - 621dalmatinerdb/mstore
https://github.com/dalmatinerdb/mstoreContribute to dalmatinerdb/mstore development by creating an account on GitHub. - 622An Elixir implementation of the JSON Web Token (JWT) Standard, RFC 7519
https://github.com/garyf/json_web_token_exAn Elixir implementation of the JSON Web Token (JWT) Standard, RFC 7519 - garyf/json_web_token_ex - 623A high performance web crawler / scraper in Elixir.
https://github.com/fredwu/crawlerA high performance web crawler / scraper in Elixir. - fredwu/crawler - 624Helpers for Elixir exceptions
https://github.com/expede/exceptionalHelpers for Elixir exceptions. Contribute to expede/exceptional development by creating an account on GitHub. - 625Feature toggle library for elixir
https://github.com/securingsincity/molassesFeature toggle library for elixir. Contribute to securingsincity/molasses development by creating an account on GitHub. - 626Today I Learned
https://github.com/hashrocket/tilexToday I Learned. Contribute to hashrocket/tilex development by creating an account on GitHub. - 627A repository `similar` to Ecto.Repo that maps to an underlying http client, sending requests to an external rest api instead of a database
https://github.com/inaka/DayronA repository `similar` to Ecto.Repo that maps to an underlying http client, sending requests to an external rest api instead of a database - inaka/Dayron - 628Core Scenic library
https://github.com/boydm/scenicCore Scenic library. Contribute to ScenicFramework/scenic development by creating an account on GitHub. - 629Web DSL for Elixir
https://github.com/herenowcoder/webassemblyWeb DSL for Elixir. Contribute to wkhere/webassembly development by creating an account on GitHub. - 630JSON parser and genarator in Elixir.
https://github.com/guedes/exjsonJSON parser and genarator in Elixir. Contribute to guedes/exjson development by creating an account on GitHub. - 631Classical multiplayer snake game with Vim-style keybinding
https://github.com/theanht1/vim_snakeClassical multiplayer snake game with Vim-style keybinding - theanht1/vim_snake - 632URI encode nested GET parameters and array values in Elixir
https://github.com/shhavel/uri_queryURI encode nested GET parameters and array values in Elixir - shhavel/uri_query - 633WebDriver client for Elixir.
https://github.com/stuart/elixir-webdriverWebDriver client for Elixir. Contribute to stuart/elixir-webdriver development by creating an account on GitHub. - 634Creating letter avatar from a name
https://github.com/zhangsoledad/alchemic_avatarCreating letter avatar from a name. Contribute to zhangsoledad/alchemic_avatar development by creating an account on GitHub. - 635💧 Elixir NIF for cmark (C), a parser library following the CommonMark spec, a compatible implementation of Markdown.
https://github.com/asaaki/cmark.ex💧 Elixir NIF for cmark (C), a parser library following the CommonMark spec, a compatible implementation of Markdown. - asaaki/cmark.ex - 636Create low-latency, interactive user experiences for stateless microservices.
https://github.com/Accenture/reactive-interaction-gatewayCreate low-latency, interactive user experiences for stateless microservices. - Accenture/reactive-interaction-gateway - 637Application Monitoring for Ruby on Rails, Elixir, Node.js & Python
https://appsignal.com/AppSignal APM offers error tracking, performance monitoring, dashboards, host metrics, and alerts. Built for Ruby, Ruby on Rails, Elixir, Node.js, and JavaScript. - 638Native JSON library for Elixir
https://github.com/cblage/elixir-jsonNative JSON library for Elixir. Contribute to cblage/elixir-json development by creating an account on GitHub. - 639Elixir ~M sigil for map shorthand. `~M{id, name} ~> %{id: id, name: name}`
https://github.com/meyercm/shorter_mapsElixir ~M sigil for map shorthand. `~M{id, name} ~> %{id: id, name: name}` - meyercm/shorter_maps - 640Build software better, together
https://github.com/SenecaSystems/huffmanGitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 641Elixir implementation of Ethereum's RLP (Recursive Length Prefix) encoding
https://github.com/exthereum/ex_rlpElixir implementation of Ethereum's RLP (Recursive Length Prefix) encoding - mana-ethereum/ex_rlp - 642A REST toolkit for building highly-scalable and fault-tolerant HTTP APIs with Elixir
https://github.com/slogsdon/placidA REST toolkit for building highly-scalable and fault-tolerant HTTP APIs with Elixir - slogsdon/placid - 643An Elixir Plug for profiling code with fprof.
https://github.com/obmarg/plug_fprofAn Elixir Plug for profiling code with fprof. Contribute to obmarg/plug_fprof development by creating an account on GitHub. - 644Build web scrapers and automate interaction with websites in Elixir with ease!
https://github.com/gushonorato/mechanizeBuild web scrapers and automate interaction with websites in Elixir with ease! - gushonorato/mechanize - 645🌊 Elixir RSS/ATOM feed builder with a focus on standards compliance, security and extensibility
https://github.com/Betree/atomex🌊 Elixir RSS/ATOM feed builder with a focus on standards compliance, security and extensibility - Betree/atomex - 646User management lib for Phoenix Framework
https://github.com/trenpixster/addictUser management lib for Phoenix Framework. Contribute to trenpixster/addict development by creating an account on GitHub. - 647Elixir package that allows to add compatibility layers via API gateways.
https://github.com/Nebo15/multiverseElixir package that allows to add compatibility layers via API gateways. - Nebo15/multiverse - 648http proxy with Elixir. wait request with multi port and forward to each URIs
https://github.com/KazuCocoa/http_proxyhttp proxy with Elixir. wait request with multi port and forward to each URIs - KazuCocoa/http_proxy - 649A server-side rendering component library for Phoenix
https://github.com/msaraiva/surfaceA server-side rendering component library for Phoenix - surface-ui/surface - 650InfluxDB driver for Elixir
https://github.com/mneudert/instreamInfluxDB driver for Elixir. Contribute to mneudert/instream development by creating an account on GitHub. - 651Geohash encode/decode for Elixir
https://github.com/polmuz/elixir-geohashGeohash encode/decode for Elixir. Contribute to polmuz/elixir-geohash development by creating an account on GitHub. - 652A Geometry library for Elixir that calculates spatial relationships between two geometries
https://github.com/pkinney/topoA Geometry library for Elixir that calculates spatial relationships between two geometries - pkinney/topo - 653Fastest tool to access data in Elixir
https://github.com/hissssst/pathexFastest tool to access data in Elixir. Contribute to hissssst/pathex development by creating an account on GitHub. - 654jschneider1207/ElixirExif
https://github.com/sschneider1207/ElixirExifContribute to jschneider1207/ElixirExif development by creating an account on GitHub. - 655A lager backend that forwards all log messages to Elixir's Logger
https://github.com/PSPDFKit-labs/lager_loggerA lager backend that forwards all log messages to Elixir's Logger - PSPDFKit-labs/lager_logger - 656Pipe elixir functions that match ok/error tuples or custom patterns.
https://github.com/vic/ok_josePipe elixir functions that match ok/error tuples or custom patterns. - vic/ok_jose - 657Simple JSON Logger for Elixir apps.
https://github.com/LeeroyDing/json_loggerSimple JSON Logger for Elixir apps. Contribute to LeeroyDing/json_logger development by creating an account on GitHub. - 658A generic interface to different metrics systems in Erlang.
https://github.com/benoitc/erlang-metricsA generic interface to different metrics systems in Erlang. - benoitc/erlang-metrics - 659Rate limiter and overload protection for erlang application
https://github.com/liveforeverx/ratxRate limiter and overload protection for erlang application - liveforeverx/ratx - 660An interactive dependency plotter for your Hex Package
https://github.com/sivsushruth/mixgraphAn interactive dependency plotter for your Hex Package - sivsushruth/mixgraph - 661Phoenix and Ecto integration with support for concurrent acceptance testing
https://github.com/phoenixframework/phoenix_ectoPhoenix and Ecto integration with support for concurrent acceptance testing - phoenixframework/phoenix_ecto - 662Some helpers for phoenix html( truncate, time_ago_in_words, number_with_delimiter, url_for, current_page? )
https://github.com/ikeikeikeike/phoenix_html_simplified_helpersSome helpers for phoenix html( truncate, time_ago_in_words, number_with_delimiter, url_for, current_page? ) - GitHub - ikeikeikeike/phoenix_html_simplified_helpers: Some helpers for phoenix html( ... - 663An HTTP/2 client for Elixir (a work in progress!)
https://github.com/peburrows/riverAn HTTP/2 client for Elixir (a work in progress!). Contribute to peburrows/river development by creating an account on GitHub. - 664An exploration into a stand-alone library for Plug applications to easily adopt WebSockets.
https://github.com/slogsdon/plug-web-socketAn exploration into a stand-alone library for Plug applications to easily adopt WebSockets. - slogsdon/plug-web-socket - 665RFC 6570 compliant URI template processor for Elixir
https://github.com/pezra/ex-uri-templateRFC 6570 compliant URI template processor for Elixir - pezra/ex-uri-template - 666File upload and on-the-fly processing for Elixir
https://github.com/doomspork/artifactFile upload and on-the-fly processing for Elixir. Contribute to doomspork/artifact development by creating an account on GitHub. - 667Japan's Kanji Usage on Twitter in Realtime
https://github.com/SebastianSzturo/kaisuuJapan's Kanji Usage on Twitter in Realtime. Contribute to SebastianSzturo/kaisuu development by creating an account on GitHub. - 668provides a full user authentication experience for an API. Includes login,logout,register,forgot password, forgot username, confirmation email and all that other good stuff. Includes plug for checking for authenticated users and macro for generating the required routes.
https://github.com/AppDoctorIo/accesspassprovides a full user authentication experience for an API. Includes login,logout,register,forgot password, forgot username, confirmation email and all that other good stuff. Includes plug for check... - 669Exception tracking and logging from Elixir to Rollbar
https://github.com/elixir-addicts/rollbaxException tracking and logging from Elixir to Rollbar - ForzaElixir/rollbax - 670DEPRECATED - Phoenix Authentication library that wraps Guardian for extra functionality
https://github.com/britton-jb/sentinelDEPRECATED - Phoenix Authentication library that wraps Guardian for extra functionality - britton-jb/sentinel - 671All sorts of useful information about every country. A pure elixir port of the ruby Countries gem
https://github.com/navinpeiris/countriexAll sorts of useful information about every country. A pure elixir port of the ruby Countries gem - navinpeiris/countriex - 672Elixir coordinate conversion library using OSGeo's PROJ.4
https://github.com/CandyGumdrop/projElixir coordinate conversion library using OSGeo's PROJ.4 - CandyGumdrop/proj - 673Prometheus.io collector for Elixir.Ecto
https://github.com/deadtrickster/prometheus-ectoPrometheus.io collector for Elixir.Ecto. Contribute to deadtrickster/prometheus-ecto development by creating an account on GitHub. - 674An Elixir logger backend for posting errors to Slack.
https://github.com/craigp/slack_logger_backendAn Elixir logger backend for posting errors to Slack. - craigp/slack_logger_backend - 675Helper module for working with Erlang proplists, eep 18, map and mochijson-style JSON representations
https://github.com/jr0senblum/jwalkHelper module for working with Erlang proplists, eep 18, map and mochijson-style JSON representations - jr0senblum/jwalk - 676Plug adapter for the wait1 protocol
https://github.com/wait1/plug_wait1Plug adapter for the wait1 protocol. Contribute to wait1/wait1_ex development by creating an account on GitHub. - 677Reads netrc files implemented in Elixir
https://github.com/ma2gedev/netrcexReads netrc files implemented in Elixir. Contribute to ma2gedev/netrcex development by creating an account on GitHub. - 678Token authentication solution for Phoenix. Useful for APIs for e.g. single page apps.
https://github.com/manukall/phoenix_token_authToken authentication solution for Phoenix. Useful for APIs for e.g. single page apps. - manukall/phoenix_token_auth - 679Small, Fast event processing and monitoring for Erlang/OTP applications.
https://github.com/DeadZen/goldrushSmall, Fast event processing and monitoring for Erlang/OTP applications. - DeadZen/goldrush - 680A GraphQL client for Elixir
https://github.com/uesteibar/neuronA GraphQL client for Elixir. Contribute to uesteibar/neuron development by creating an account on GitHub. - 681Dynamic dispatching library for metrics and instrumentations.
https://github.com/beam-telemetry/telemetryDynamic dispatching library for metrics and instrumentations. - beam-telemetry/telemetry - 682An Elixir Geocoder/Reverse Geocoder
https://github.com/knrz/geocoderAn Elixir Geocoder/Reverse Geocoder. Contribute to CyrusOfEden/geocoder development by creating an account on GitHub. - 683Kitto is a framework for interactive dashboards written in Elixir
https://github.com/kittoframework/kittoKitto is a framework for interactive dashboards written in Elixir - kittoframework/kitto - 684This tiny library (2 macros only) allows you to define very simple rule handler using Elixir pattern matching.
https://github.com/awetzel/rulexThis tiny library (2 macros only) allows you to define very simple rule handler using Elixir pattern matching. - kbrw/rulex - 685Functional domain models with event sourcing in Elixir
https://github.com/slashdotdash/eventsourcedFunctional domain models with event sourcing in Elixir - slashdotdash/eventsourced - 686Elixir macro for extracting or transforming values inside a pipe flow.
https://github.com/vic/pitElixir macro for extracting or transforming values inside a pipe flow. - vic/pit - 687Parser for ABNF Grammars
https://github.com/marcelog/ex_abnfParser for ABNF Grammars. Contribute to marcelog/ex_abnf development by creating an account on GitHub. - 688A toy Scheme-like language on Elixir, just for fun
https://github.com/jwhiteman/lighthouse-schemeA toy Scheme-like language on Elixir, just for fun - jwhiteman/lighthouse-scheme - 689A Japanese dictionary API; a wrapper around Jisho's API (http://jisho.org)
https://github.com/nbw/jisho_elixirA Japanese dictionary API; a wrapper around Jisho's API (http://jisho.org) - GitHub - nbw/jisho_elixir: A Japanese dictionary API; a wrapper around Jisho's API (http://jisho.org) - 690An onetime key-value store for Elixir
https://github.com/ryo33/onetime-elixirAn onetime key-value store for Elixir. Contribute to ryo33/onetime-elixir development by creating an account on GitHub. - 691ConfigCat SDK for Elixir. ConfigCat is a hosted feature flag service: https://configcat.com. Manage feature toggles across frontend, backend, mobile, desktop apps. Alternative to LaunchDarkly. Management app + feature flag SDKs.
https://github.com/configcat/elixir-sdkConfigCat SDK for Elixir. ConfigCat is a hosted feature flag service: https://configcat.com. Manage feature toggles across frontend, backend, mobile, desktop apps. Alternative to LaunchDarkly. Mana... - 692Plug for writing access logs
https://github.com/mneudert/plug_accesslogPlug for writing access logs. Contribute to mneudert/plug_accesslog development by creating an account on GitHub. - 693Geographic calculations for Elixir
https://github.com/yltsrc/geocalcGeographic calculations for Elixir. Contribute to yltsrc/geocalc development by creating an account on GitHub. - 694🟪 AppSignal for Elixir package
https://github.com/appsignal/appsignal-elixir/🟪 AppSignal for Elixir package. Contribute to appsignal/appsignal-elixir development by creating an account on GitHub. - 695A simple egauge parser to retrieve and parse data from egauge devices
https://github.com/Brightergy/egaugexA simple egauge parser to retrieve and parse data from egauge devices - Brightergy/egaugex - 696Erlang set associative map for key lists
https://github.com/okeuday/keys1valueErlang set associative map for key lists. Contribute to okeuday/keys1value development by creating an account on GitHub. - 697Elixir Mix task to starring GitHub repository with `mix deps.get`ting dependent library
https://github.com/ma2gedev/mix-starElixir Mix task to starring GitHub repository with `mix deps.get`ting dependent library - ma2gedev/mix-star - 698Lexer in Elixir. Lexer in Elixir. Lexer in Elixir. Lexer in Elixir. Lexer in Elixir. Lexer in Elixir. Lexer in Elixir. Lexer in Elixir. Lexer in Elixir. Lexer in Elixir.
https://github.com/jamesotron/lex_luthorLexer in Elixir. Lexer in Elixir. Lexer in Elixir. Lexer in Elixir. Lexer in Elixir. Lexer in Elixir. Lexer in Elixir. Lexer in Elixir. Lexer in Elixir. Lexer in Elixir. - jimsynz/lex_luthor - 699The official Elixir SDK for Sentry (sentry.io)
https://github.com/getsentry/sentry-elixirThe official Elixir SDK for Sentry (sentry.io). Contribute to getsentry/sentry-elixir development by creating an account on GitHub. - 700Easily parsable single line, plain text and JSON logger for Plug and Phoenix applications
https://github.com/navinpeiris/logsterEasily parsable single line, plain text and JSON logger for Plug and Phoenix applications - navinpeiris/logster - 701A declarative, extensible framework for building Elixir applications.
https://github.com/ash-project/ashA declarative, extensible framework for building Elixir applications. - ash-project/ash - 702An Elixir Prometheus metrics collection library built on top of Telemetry with accompanying Grafana dashboards
https://github.com/akoutmos/prom_exAn Elixir Prometheus metrics collection library built on top of Telemetry with accompanying Grafana dashboards - akoutmos/prom_ex - 703A logging framework for Erlang/OTP
https://github.com/basho/lagerA logging framework for Erlang/OTP. Contribute to basho/lager development by creating an account on GitHub. - 704Image processing in Elixir
https://github.com/SenecaSystems/imagineerImage processing in Elixir. Contribute to tyre/imagineer development by creating an account on GitHub. - 705ExFCM is a simple wrapper around Firebase Cloud Messaging
https://github.com/Hajto/ExFCMExFCM is a simple wrapper around Firebase Cloud Messaging - Hajto/ExFCM - 706🍵 First-class Elixir match specifications.
https://github.com/christhekeele/matcha🍵 First-class Elixir match specifications. Contribute to christhekeele/matcha development by creating an account on GitHub. - 707Yet another elixir reloader.
https://github.com/falood/exsyncYet another elixir reloader. Contribute to falood/exsync development by creating an account on GitHub. - 708Spawn processes from the file system.
https://github.com/jtmoulia/spawndirSpawn processes from the file system. Contribute to jtmoulia/spawndir development by creating an account on GitHub. - 709Technical indicator library for Elixir with no dependencies.
https://github.com/thisiscetin/indicadoTechnical indicator library for Elixir with no dependencies. - thisiscetin/indicado - 710Elixir wrapper for the Spotify Web API
https://github.com/jsncmgs1/spotify_exElixir wrapper for the Spotify Web API. Contribute to jsncmgs1/spotify_ex development by creating an account on GitHub. - 711A SPARQL client for Elixir
https://github.com/marcelotto/sparql_clientA SPARQL client for Elixir. Contribute to rdf-elixir/sparql_client development by creating an account on GitHub. - 712Simplified module reloader for Elixir
https://github.com/herenowcoder/repriseSimplified module reloader for Elixir. Contribute to wkhere/reprise development by creating an account on GitHub. - 713Simple wrapper for growl, the notification system for OSX
https://github.com/zachallett/growlSimple wrapper for growl, the notification system for OSX - zachallett/growl - 714Elixir JWT library
https://github.com/bryanjos/jokenElixir JWT library. Contribute to joken-elixir/joken development by creating an account on GitHub. - 715SpiderMan,a base-on Broadway fast high-level web crawling & scraping framework for Elixir.
https://github.com/feng19/spider_manSpiderMan,a base-on Broadway fast high-level web crawling & scraping framework for Elixir. - feng19/spider_man - 716Elixir library to log custom application metrics, in a well-structured, human and machine readable format, for use by downstream log processing systems (Librato, Reimann, etc...)
https://github.com/rwdaigle/metrixElixir library to log custom application metrics, in a well-structured, human and machine readable format, for use by downstream log processing systems (Librato, Reimann, etc...) - rwdaigle/metrix - 717An Elixir library for defining structs with a type without writing boilerplate code.
https://github.com/ejpcmac/typed_structAn Elixir library for defining structs with a type without writing boilerplate code. - ejpcmac/typed_struct - 718A light Elixir wrapper around exometer.
https://github.com/pinterest/elixometerA light Elixir wrapper around exometer. Contribute to pinterest/elixometer development by creating an account on GitHub. - 719Elixir weighted random pick library optimised for quick take_one and take_n operations
https://github.com/JohnJocoo/weighted_randomElixir weighted random pick library optimised for quick take_one and take_n operations - JohnJocoo/weighted_random - 720Elixir library for DRYing CRUD in Phoenix Contexts and Absinthe Resolvers.
https://github.com/gabrielpra1/crudryElixir library for DRYing CRUD in Phoenix Contexts and Absinthe Resolvers. - jungsoft/crudry - 721An Elixir mix task that lists all the licenses used by your Mix project dependencies.
https://github.com/unnawut/licensirAn Elixir mix task that lists all the licenses used by your Mix project dependencies. - unnawut/licensir - 722A simple Elixir Markdown to HTML conversion library
https://github.com/devinus/markdownA simple Elixir Markdown to HTML conversion library - devinus/markdown - 723Make rendering React.js components in Phoenix easy
https://github.com/geolessel/react-phoenixMake rendering React.js components in Phoenix easy - geolessel/react-phoenix - 724Folsom consumer plugin for dalmatinerdb
https://github.com/dalmatinerdb/folsom_ddbFolsom consumer plugin for dalmatinerdb. Contribute to dalmatinerdb/folsom_ddb development by creating an account on GitHub. - 725Filtering from incoming params in Elixir/Ecto/Phoenix with easy to use DSL.
https://github.com/omohokcoj/filterableFiltering from incoming params in Elixir/Ecto/Phoenix with easy to use DSL. - omohokcoj/filterable - 726Interface for HTTP webservers, frameworks and clients
https://github.com/CrowdHailer/raxxInterface for HTTP webservers, frameworks and clients - CrowdHailer/raxx - 727Spell is a Web Application Messaging Protocol (WAMP) client implementation in Elixir. WAMP is an open standard WebSocket subprotocol that provides two application messaging patterns in one unified protocol: Remote Procedure Calls + Publish & Subscribe: http://wamp.ws/
https://github.com/MyMedsAndMe/spellSpell is a Web Application Messaging Protocol (WAMP) client implementation in Elixir. WAMP is an open standard WebSocket subprotocol that provides two application messaging patterns in one unified ... - 728Write Elixir code using statically-typed Elm-like syntax (compatible with Elm tooling)
https://github.com/wende/elchemyWrite Elixir code using statically-typed Elm-like syntax (compatible with Elm tooling) - wende/elchemy - 729Reusable, composable patterns across Elixir libraries
https://github.com/vic/expatReusable, composable patterns across Elixir libraries - vic/expat - 730Elixir client for Philips Hue connected light bulbs
https://github.com/xavier/huexElixir client for Philips Hue connected light bulbs - xavier/huex - 731Extremely simple Process pooling and task submission in Elixir
https://github.com/whitfin/expoolExtremely simple Process pooling and task submission in Elixir - whitfin/expool - 732Elixir MapReduce interfaces with Hadoop Streaming integration
https://github.com/whitfin/vesselElixir MapReduce interfaces with Hadoop Streaming integration - whitfin/vessel - 733🌲 Great Elixir logging made easy
https://github.com/timberio/timber-elixir🌲 Great Elixir logging made easy. Contribute to vectordotdev/timber-elixir development by creating an account on GitHub. - 734Better dependency injection in Elixir
https://github.com/BlakeWilliams/pactBetter dependency injection in Elixir. Contribute to BlakeWilliams/pact development by creating an account on GitHub. - 735Elixir Library for Japan municipality key converting
https://github.com/hykw/japan_municipality_keyElixir Library for Japan municipality key converting - hykw/japan_municipality_key - 736Simple Markov Chain written in Elixir
https://github.com/eljojo/ex_chainSimple Markov Chain written in Elixir. Contribute to eljojo/ex_chain development by creating an account on GitHub. - 737An Elixir client for Instrumental
https://github.com/undeadlabs/instrumental-exAn Elixir client for Instrumental. Contribute to undeadlabs/instrumental-ex development by creating an account on GitHub. - 738ExAdmin is an auto administration package for Elixir and the Phoenix Framework
https://github.com/smpallen99/ex_adminExAdmin is an auto administration package for Elixir and the Phoenix Framework - smpallen99/ex_admin - 739ex-azure/ex_azure_speech
https://github.com/ex-azure/ex_azure_speechContribute to ex-azure/ex_azure_speech development by creating an account on GitHub. - 740Browser detection for Elixir
https://github.com/tuvistavie/elixir-browserBrowser detection for Elixir. Contribute to danhper/elixir-browser development by creating an account on GitHub. - 741compile and load erlang modules from string input
https://github.com/okeuday/dynamic_compilecompile and load erlang modules from string input. Contribute to okeuday/dynamic_compile development by creating an account on GitHub. - 742Elixir library to create Apple Wallet (.pkpass) files
https://github.com/Bounceapp/ex_passbookElixir library to create Apple Wallet (.pkpass) files - Bounceapp/ex_passbook - 743Elixir binding for lager
https://github.com/khia/exlagerElixir binding for lager. Contribute to khia/exlager development by creating an account on GitHub. - 744an erlang application for consuming, producing and manipulating json. inspired by yajl
https://github.com/talentdeficit/jsxan erlang application for consuming, producing and manipulating json. inspired by yajl - talentdeficit/jsx - 745Elixir library to find geo location information given an IP address, hostname or Plug.Conn
https://github.com/navinpeiris/geoipElixir library to find geo location information given an IP address, hostname or Plug.Conn - navinpeiris/geoip - 746Easy parameters validation/casting with Ecto.Schema, akin to Rails' strong parameters.
https://github.com/vic/paramsEasy parameters validation/casting with Ecto.Schema, akin to Rails' strong parameters. - vic/params - 747Raylib binds to elixir for games programming
https://github.com/shiryel/rayexRaylib binds to elixir for games programming. Contribute to shiryel/rayex development by creating an account on GitHub. - 748Logstash backend for the Elixir Logger
https://github.com/marcelog/logger_logstash_backendLogstash backend for the Elixir Logger. Contribute to marcelog/logger_logstash_backend development by creating an account on GitHub. - 749Floki is a simple HTML parser that enables search for nodes using CSS selectors.
https://github.com/philss/flokiFloki is a simple HTML parser that enables search for nodes using CSS selectors. - philss/floki - 750Interact with hardware in Elixir - GPIOs, I2C and SPI
https://github.com/fhunleth/elixir_aleInteract with hardware in Elixir - GPIOs, I2C and SPI - fhunleth/elixir_ale - 751Continuous Integration, Deployment, and Delivery coordinator, written in Elixir.
https://github.com/AlloyCI/alloy_ciContinuous Integration, Deployment, and Delivery coordinator, written in Elixir. - AlloyCI/alloy_ci - 752An elixir library which helps with uploading image files or urls to cloudinary
https://github.com/smeevil/cloudexAn elixir library which helps with uploading image files or urls to cloudinary - smeevil/cloudex - 753introduce multi-path configuration by mindreframer · Pull Request #1 · Driftrock/quiet_logger
https://github.com/Driftrock/quiet_logger/pull/1problem: sometimes you might have more than one healthcheck, eg. in Kubernetes we have readiness / liveliness checks solution: extend the api to accept list of paths to ignore + tests - 754Tiny Erlang VM
https://github.com/bettio/AtomVMTiny Erlang VM. Contribute to atomvm/AtomVM development by creating an account on GitHub. - 755Work with external processes like a boss
https://github.com/alco/porcelainWork with external processes like a boss. Contribute to alco/porcelain development by creating an account on GitHub. - 756Image processing in Elixir (ImageMagick command line wrapper)
https://github.com/route/mogrifyImage processing in Elixir (ImageMagick command line wrapper) - elixir-mogrify/mogrify - 757Open Source API Gateway in Elixir
https://github.com/AntonFagerberg/racklaOpen Source API Gateway in Elixir. Contribute to AntonFagerberg/rackla development by creating an account on GitHub. - 758Yet Another HTTP client for Elixir powered by hackney
https://github.com/edgurgel/httpoisonYet Another HTTP client for Elixir powered by hackney - edgurgel/httpoison - 759Full Phoenix Support for Rummage. It can be used for searching, sorting and paginating collections in phoenix.
https://github.com/Excipients/rummage_phoenixFull Phoenix Support for Rummage. It can be used for searching, sorting and paginating collections in phoenix. - annkissam/rummage_phoenix - 760Elixir library for discovering favicons
https://github.com/ikeikeikeike/exfaviconElixir library for discovering favicons. Contribute to ikeikeikeike/exfavicon development by creating an account on GitHub. - 761Macro for tapping into a pattern match while using the pipe operator
https://github.com/mgwidmann/elixir-pattern_tapMacro for tapping into a pattern match while using the pipe operator - mgwidmann/elixir-pattern_tap - 762Streaming Elixir API built upon ElasticSearch's percolation.
https://github.com/chatgris/funnelStreaming Elixir API built upon ElasticSearch's percolation. - chatgris/funnel - 763Functional HTTP client for Elixir with support for HTTP/1 and HTTP/2 🌱
https://github.com/ericmj/mintFunctional HTTP client for Elixir with support for HTTP/1 and HTTP/2 🌱 - elixir-mint/mint - 764Elixir -> HTML/JavaScript based presentation framework intended for showing Elixir code
https://github.com/Cobenian/PresentexElixir -> HTML/JavaScript based presentation framework intended for showing Elixir code - Cobenian/Presentex - 765Parse RSS and Atom feeds
https://github.com/michaelnisi/feederParse RSS and Atom feeds. Contribute to michaelnisi/feeder development by creating an account on GitHub. - 766Erlang port driver for interacting with syslog via syslog(3)
https://github.com/Vagabond/erlang-syslogErlang port driver for interacting with syslog via syslog(3) - Vagabond/erlang-syslog - 767Elixir NIF for discount, a Markdown parser
https://github.com/asaaki/discount.exElixir NIF for discount, a Markdown parser. Contribute to asaaki/discount.ex development by creating an account on GitHub. - 768[Deprecated because ibrowse is not maintained] HTTP client for Elixir (use Tesla please)
https://github.com/myfreeweb/httpotion[Deprecated because ibrowse is not maintained] HTTP client for Elixir (use Tesla please) - valpackett/httpotion - 769A collection of GIS functions for Elixir
https://github.com/bryanjos/geoA collection of GIS functions for Elixir. Contribute to felt/geo development by creating an account on GitHub. - 770Compose web applications with functions
https://github.com/elixir-lang/plugCompose web applications with functions. Contribute to elixir-plug/plug development by creating an account on GitHub. - 771JSON:API Serializer and Query Handler for Elixir
https://github.com/jeregrine/jsonapiJSON:API Serializer and Query Handler for Elixir. Contribute to beam-community/jsonapi development by creating an account on GitHub. - 772Matplotlib for Elixir
https://github.com/MaxStrange/expyplotMatplotlib for Elixir. Contribute to MaxStrange/expyplot development by creating an account on GitHub. - 773ANSI rainbow for elixir, be a magician
https://github.com/tomgco/elixir-charmANSI rainbow for elixir, be a magician. Contribute to tomgco/elixir-charm development by creating an account on GitHub. - 774BUPE is a Elixir ePub generator and parser (supports EPUB v3)
https://github.com/milmazz/bupeBUPE is a Elixir ePub generator and parser (supports EPUB v3) - milmazz/bupe - 775Phoenix + Live View HEEX Components
https://github.com/petalframework/petal_componentsPhoenix + Live View HEEX Components . Contribute to petalframework/petal_components development by creating an account on GitHub. - 776:surfer: Traceable, extendable and minimalist **event bus** implementation for Elixir with built-in **event store** and **event watcher** based on ETS.
https://github.com/mustafaturan/event_bus:surfer: Traceable, extendable and minimalist **event bus** implementation for Elixir with built-in **event store** and **event watcher** based on ETS. - otobus/event_bus - 777JSONAPI.org Serialization in Elixir.
https://github.com/AgilionApps/ja_serializerJSONAPI.org Serialization in Elixir. Contribute to vt-elixir/ja_serializer development by creating an account on GitHub. - 778ExImageInfo is an Elixir library to parse images (binaries) and get the dimensions (size), detected mime-type and overall validity for a set of image formats. It is the fastest and supports multiple formats.
https://github.com/rNoz/ex_image_infoExImageInfo is an Elixir library to parse images (binaries) and get the dimensions (size), detected mime-type and overall validity for a set of image formats. It is the fastest and supports multipl... - 779A minesweeper clone in the terminal, written in Elixir.
https://github.com/kevlar1818/minesA minesweeper clone in the terminal, written in Elixir. - kevin-hanselman/mines - 780The flexible HTTP client library for Elixir, with support for middleware and multiple adapters.
https://github.com/teamon/teslaThe flexible HTTP client library for Elixir, with support for middleware and multiple adapters. - elixir-tesla/tesla - 781A rapid admin generator for Elixir & Phoenix
https://github.com/infinitered/torchA rapid admin generator for Elixir & Phoenix. Contribute to mojotech/torch development by creating an account on GitHub. - 782Provides authentication for phoenix application
https://github.com/opendrops/passportProvides authentication for phoenix application. Contribute to shankardevy/passport development by creating an account on GitHub. - 783The owls are not what they seem
https://github.com/ahtung/format_parser.exThe owls are not what they seem. Contribute to dunyakirkali/format_parser.ex development by creating an account on GitHub. - 784"The mother of all demo apps" — Exemplary fullstack Medium.com clone powered by React, Angular, Node, Django, and many more
https://realworld.io/"The mother of all demo apps" — Exemplary fullstack Medium.com clone powered by React, Angular, Node, Django, and many more - gothinkster/realworld - 785Crawly, a high-level web crawling & scraping framework for Elixir.
https://github.com/oltarasenko/crawlyCrawly, a high-level web crawling & scraping framework for Elixir. - GitHub - elixir-crawly/crawly: Crawly, a high-level web crawling & scraping framework for Elixir. - 786Elixir port of libphonenumber
https://github.com/socialpaymentsbv/ex_phone_numberElixir port of libphonenumber. Contribute to ex-phone-number/ex_phone_number development by creating an account on GitHub. - 787Generate Erlang VM byte code from Haskell
https://github.com/hkgumbs/codec-beamGenerate Erlang VM byte code from Haskell. Contribute to kofigumbs/codec-beam development by creating an account on GitHub. - 788Automatically create slugs for Ecto schemas.
https://github.com/sobolevn/ecto_autoslug_fieldAutomatically create slugs for Ecto schemas. Contribute to wemake-services/ecto_autoslug_field development by creating an account on GitHub. - 789Application Performance Monitoring & Error Tracking Software
https://getsentry.com/.Self-hosted and cloud-based application performance monitoring & error tracking that helps software teams see clearer, solve quicker, & learn continuously. - 790NEAR | Blockchains, Abstracted
https://near.orgNEAR is the chain abstraction stack, empowering builders to create apps that scale to billions of users and across all blockchains. - 791stream_weaver
https://hex.pm/packages/stream_weaverLibrary for working with streams - 792exsms
https://hex.pm/packages/exsmsExsms: A Elixir library for sending transactional SMS - supports Sendinblue, mailjet, msg91, msg91_otp and textlocal - 793ecto_factory
https://hex.pm/packages/ecto_factoryEasily generate structs and maps based on your ecto schemas. - 794Ockam | Build Trust
https://www.ockam.io/learn/concepts/Modern applications are distributed, interconnected, and have Zero-Trust in network boundaries. These applications must exchange data with Trust. Ockam empowers developers to build applications that can Trust Data-in-Motion across complex, variable, and hostile networks. Ockam has a simple developer experience and powerful primitives that orchestrate end-to-end encryption, key management, authorization policy enforcement, and mutual authentication. - 795Timo Pallach / FlyingDdns · GitLab
https://gitlab.com/timopallach/FlyingDdnsA dyndns server written in elixir using the following components: PowerDNS as DNS server PostgreSQL as database backend phoenix as webfrontend (using elixir/erlang) relayd as http load balancer - 796Elixir library for signing and verifying BEAM files with Ed25519 signatures
https://github.com/benknowles/code_signingElixir library for signing and verifying BEAM files with Ed25519 signatures - benknowles/code_signing - 797Automatically generate a release for your Elixir project!
https://github.com/bitwalker/exrmAutomatically generate a release for your Elixir project! - bitwalker/exrm - 798Automates semantic release versioning and best practices for elixir packages.
https://github.com/tfiedlerdejanze/expublishAutomates semantic release versioning and best practices for elixir packages. - tfiedlerdejanze/expublish - 799Chemistry is a Testing Framework for Elixir
https://github.com/genericlady/chemistryChemistry is a Testing Framework for Elixir. Contribute to genericlady/chemistry development by creating an account on GitHub. - 800A mix task to execute eunit tests.
https://github.com/dantswain/mix_eunitA mix task to execute eunit tests. Contribute to dantswain/mix_eunit development by creating an account on GitHub. - 801KazuCocoa/elixir-gimei
https://github.com/KazuCocoa/elixir-gimeiContribute to KazuCocoa/elixir-gimei development by creating an account on GitHub. - 802Excel Parser written in Elixir (currently only Excel 2000)
https://github.com/leifg/excellentExcel Parser written in Elixir (currently only Excel 2000) - leifg/excellent - 803An HTML DSL for Elixir and Phoenix
https://github.com/mhanberg/templeAn HTML DSL for Elixir and Phoenix. Contribute to mhanberg/temple development by creating an account on GitHub. - 804Elixir library for writing integration tests and browser automation
https://github.com/HashNuke/houndElixir library for writing integration tests and browser automation - HashNuke/hound - 805A subdomain-safe name generator
https://github.com/jsonmaur/namorA subdomain-safe name generator. Contribute to jsonmaur/namor development by creating an account on GitHub. - 806Gibran is an Elixir natural language processor, and a port of WordsCounted.
https://github.com/abitdodgy/gibranGibran is an Elixir natural language processor, and a port of WordsCounted. - abitdodgy/gibran - 807🛡️ CA: Certificate Authority. ДСТУ: 4145. ITU/IETF: 3279, 5755, X.501, X.509, X.511, X.520.
https://github.com/synrc/ca🛡️ CA: Certificate Authority. ДСТУ: 4145. ITU/IETF: 3279, 5755, X.501, X.509, X.511, X.520. - synrc/ca - 808Socket acceptor pool for Elixir
https://github.com/slogsdon/poolSocket acceptor pool for Elixir. Contribute to slogsdon/pool development by creating an account on GitHub. - 809🔤 Natural language detection for Elixir
https://github.com/minibikini/paasaa🔤 Natural language detection for Elixir. Contribute to minibikini/paasaa development by creating an account on GitHub. - 810A toolkit for data mapping and language integrated query.
https://github.com/elixir-ecto/ectoA toolkit for data mapping and language integrated query. - elixir-ecto/ecto - 811BarrelDB Elixir client done in my GSoC '18. Mirror of https://gitlab.com/barrel-db/Clients/barrel_ex
https://github.com/jxub/barrel_exBarrelDB Elixir client done in my GSoC '18. Mirror of https://gitlab.com/barrel-db/Clients/barrel_ex - jxub/barrel_ex - 812Cassandra Ecto Adapter
https://github.com/cafebazaar/ecto-cassandraCassandra Ecto Adapter. Contribute to cafebazaar/ecto-cassandra development by creating an account on GitHub. - 813A thin veneer over HTTPotion that talks to Elastic Search
https://github.com/radar/elasticA thin veneer over HTTPotion that talks to Elastic Search - radar/elastic - 814Simple Stat Ex can be used to keep counters around hourly daily or other activity for an elixir project
https://github.com/Tyler-pierce/simplestatexSimple Stat Ex can be used to keep counters around hourly daily or other activity for an elixir project - Tyler-pierce/simplestatex - 815Interactive semantic versioning for Elixir packages
https://github.com/glasnoster/eliverInteractive semantic versioning for Elixir packages - glasnoster/eliver - 816Level for Elixir implements various helper functions and data types for working with Googles Level data store.
https://github.com/gausby/levelLevel for Elixir implements various helper functions and data types for working with Googles Level data store. - gausby/level - 817UUID generator and utilities for Elixir
https://github.com/zyro/elixir-uuidUUID generator and utilities for Elixir. Contribute to zyro/elixir-uuid development by creating an account on GitHub. - 818SQLite3 adapter for Ecto
https://github.com/jazzyb/sqlite_ectoSQLite3 adapter for Ecto. Contribute to jazzyb/sqlite_ecto development by creating an account on GitHub. - 819Simple rabbitmq bindings for elixir
https://github.com/d0rc/exrabbitSimple rabbitmq bindings for elixir. Contribute to d0rc/exrabbit development by creating an account on GitHub. - 820Mnesia wrapper for Elixir.
https://github.com/meh/amnesiaMnesia wrapper for Elixir. Contribute to meh/amnesia development by creating an account on GitHub. - 821Library for writing and manipulating (html) markup in Elixir.
https://github.com/zambal/emlLibrary for writing and manipulating (html) markup in Elixir. - zambal/eml - 822REST in peace.
https://github.com/meh/urnaREST in peace. Contribute to meh/urna development by creating an account on GitHub. - 823✉️ SMPP 3.4 protocol and framework implementation in Elixir
https://github.com/savonarola/smppex✉️ SMPP 3.4 protocol and framework implementation in Elixir - savonarola/smppex - 824Mysql driver for Elixir from Erlang
https://github.com/tjheeta/mysqlexMysql driver for Elixir from Erlang. Contribute to tjheeta/mysqlex development by creating an account on GitHub. - 825Elixir queue! A simple, in-memory queue with worker pooling and rate limiting in Elixir.
https://github.com/fredwu/opqElixir queue! A simple, in-memory queue with worker pooling and rate limiting in Elixir. - fredwu/opq - 826Automated changelog generation from git logs
https://github.com/Gazler/changexAutomated changelog generation from git logs. Contribute to Gazler/changex development by creating an account on GitHub. - 827Riak adapter for Ecto
https://github.com/pma/riak_ectoRiak adapter for Ecto. Contribute to pma/riak_ecto development by creating an account on GitHub. - 828Erlang/Elixir Release Assembler
https://github.com/yrashk/relexErlang/Elixir Release Assembler. Contribute to yrashk/relex development by creating an account on GitHub. - 829📝 Simple ordered model management with Ecto.
https://github.com/popo63301/ecto_list📝 Simple ordered model management with Ecto. Contribute to popo63301/ecto_list development by creating an account on GitHub. - 830An Elixir XLSX writer
https://github.com/xou/elixlsxAn Elixir XLSX writer. Contribute to xou/elixlsx development by creating an account on GitHub. - 831elixir server of engine.io
https://github.com/falood/eioelixir server of engine.io . Contribute to falood/eio development by creating an account on GitHub. - 832Postgrex.Extension and Ecto.Type for PostgreSQL isn module
https://github.com/Frost/isnPostgrex.Extension and Ecto.Type for PostgreSQL isn module - Frost/isn - 833Downloads remote file and stores it in the filesystem
https://github.com/asiniy/downloadDownloads remote file and stores it in the filesystem - asiniy/download - 834A useless library that does stuff the standard library does better.
https://github.com/lpil/paletteA useless library that does stuff the standard library does better. - lpil/palette - 835Security-focused static analysis for the Phoenix Framework
https://github.com/nccgroup/sobelowSecurity-focused static analysis for the Phoenix Framework - nccgroup/sobelow - 836Library for selective receive OTP processes
https://github.com/fishcakez/coreLibrary for selective receive OTP processes. Contribute to fishcakez/core development by creating an account on GitHub. - 837Elixir driver for the Datomic REST API
https://github.com/edubkendo/datomexElixir driver for the Datomic REST API. Contribute to edubkendo/datomex development by creating an account on GitHub. - 838An Erlang app for communicating with Elastic Search's rest interface.
https://github.com/tsloughter/erlastic_searchAn Erlang app for communicating with Elastic Search's rest interface. - tsloughter/erlastic_search - 839EctoWatch allows you to easily get notifications about database changes directly from PostgreSQL.
https://github.com/cheerfulstoic/ecto_watchEctoWatch allows you to easily get notifications about database changes directly from PostgreSQL. - cheerfulstoic/ecto_watch - 840Separate your read and write operations in replicated database setup
https://github.com/azranel/ecto_facadeSeparate your read and write operations in replicated database setup - azranel/ecto_facade - 841MessagePack Implementation for Elixir / msgpack.org[Elixir]
https://github.com/mururu/msgpack-elixirMessagePack Implementation for Elixir / msgpack.org[Elixir] - mururu/msgpack-elixir - 842High-performance and comprehensive MessagePack implementation for Elixir / msgpack.org[Elixir]
https://github.com/lexmag/msgpaxHigh-performance and comprehensive MessagePack implementation for Elixir / msgpack.org[Elixir] - lexmag/msgpax - 843Fixtures for Elixir apps
https://github.com/DockYard/ecto_fixturesFixtures for Elixir apps. Contribute to DockYard/ecto_fixtures development by creating an account on GitHub. - 844An opinionated InfluxDB UDP only client
https://github.com/timbuchwaldt/udpfluxAn opinionated InfluxDB UDP only client. Contribute to timbuchwaldt/udpflux development by creating an account on GitHub. - 845An adapter for using Timex DateTimes with Ecto
https://github.com/bitwalker/timex_ectoAn adapter for using Timex DateTimes with Ecto. Contribute to bitwalker/timex_ecto development by creating an account on GitHub. - 846An Elixir flavored HTTP client and DSL library for Elasticsearch
https://github.com/Zatvobor/tirexsAn Elixir flavored HTTP client and DSL library for Elasticsearch - Zatvobor/tirexs - 847Elixir client for Disque (https://github.com/antirez/disque), an in-memory, distributed job queue.
https://github.com/mosic/exdisqueElixir client for Disque (https://github.com/antirez/disque), an in-memory, distributed job queue. - mosic/exdisque - 848Character Code Converter
https://github.com/Joe-noh/cccCharacter Code Converter. Contribute to Joe-noh/ccc development by creating an account on GitHub. - 849QUIC protocol for Erlang & Elixir
https://github.com/emqx/quicQUIC protocol for Erlang & Elixir. Contribute to emqx/quic development by creating an account on GitHub. - 850Fast, pipelined, resilient Redis driver for Elixir. 🛍
https://github.com/whatyouhide/redixFast, pipelined, resilient Redis driver for Elixir. 🛍 - whatyouhide/redix - 851CalmAV wrapper for elixir
https://github.com/ramortegui/clamxirCalmAV wrapper for elixir. Contribute to ramortegui/clamxir development by creating an account on GitHub. - 852Elixir binding to Detergent erlang library used to call WSDL/SOAP Services
https://github.com/r-icarus/detergentexElixir binding to Detergent erlang library used to call WSDL/SOAP Services - r-icarus/detergentex - 853Elasticlunr is a small, full-text search library for use in the Elixir environment. It indexes JSON documents and provides a friendly search interface to retrieve documents.
https://github.com/heywhy/ex_elasticlunrElasticlunr is a small, full-text search library for use in the Elixir environment. It indexes JSON documents and provides a friendly search interface to retrieve documents. - heywhy/ex_elasticlunr - 854Helpers for accessing OTP application configuration
https://github.com/reset/libex-configHelpers for accessing OTP application configuration - reset/libex-config - 855An integration with Arc and Ecto.
https://github.com/stavro/arc_ectoAn integration with Arc and Ecto. Contribute to stavro/arc_ecto development by creating an account on GitHub. - 856edn (extensible data notation) encoder/decoder for Elixir
https://github.com/jfacorro/Edenedn (extensible data notation) encoder/decoder for Elixir - jfacorro/Eden - 857A simple to use SSDP client library
https://github.com/aytchell/siseA simple to use SSDP client library. Contribute to aytchell/sise development by creating an account on GitHub. - 858File not found · yeshan333/explore_ast_app
https://github.com/yeshan333/explore_ast_app/blob/main/examples/README.md.A plug app for exploring ast. Contribute to yeshan333/explore_ast_app development by creating an account on GitHub. - 859A job processing system that just verks! 🧛
https://github.com/edgurgel/verkA job processing system that just verks! 🧛. Contribute to edgurgel/verk development by creating an account on GitHub. - 860Helper modules for OTP applications
https://github.com/danielberkompas/immortalHelper modules for OTP applications. Contribute to danielberkompas/immortal development by creating an account on GitHub. - 861An NSQ client for Elixir and Erlang, written in Elixir.
https://github.com/wistia/elixir_nsqAn NSQ client for Elixir and Erlang, written in Elixir. - wistia/elixir_nsq - 862A Heap-based Priority Queue Implementation in Elixir.
https://github.com/takscape/elixir-heapqA Heap-based Priority Queue Implementation in Elixir. - takscape/elixir-heapq - 863Disk Elixir Terms Storage, dest wrapper.
https://github.com/meh/dextsDisk Elixir Terms Storage, dest wrapper. Contribute to meh/dexts development by creating an account on GitHub. - 864Composable query builder for Ecto
https://github.com/dockyard/inquisitorComposable query builder for Ecto. Contribute to DockYard/inquisitor development by creating an account on GitHub. - 865Transforms notifications from the Postgres LISTEN/NOTIFY mechanism into callback execution
https://github.com/bitgamma/boltunTransforms notifications from the Postgres LISTEN/NOTIFY mechanism into callback execution - bitgamma/boltun - 866RFC3986 URI parser
https://github.com/marcelog/ex_rfc3986RFC3986 URI parser. Contribute to marcelog/ex_rfc3986 development by creating an account on GitHub. - 867Property based Testing for Elixir (based upon PropEr)
https://github.com/alfert/propcheckProperty based Testing for Elixir (based upon PropEr) - alfert/propcheck - 868Enterprise-ready zero-trust access platform built on WireGuard®.
https://github.com/firezone/firezoneEnterprise-ready zero-trust access platform built on WireGuard®. - firezone/firezone - 869SOAP client for Elixir programming language
https://github.com/elixir-soap/soapSOAP client for Elixir programming language. Contribute to elixir-soap/soap development by creating an account on GitHub. - 870Ecto elixir adjacency list and tree traversal. Supports Ecto versions 2 and 3.
https://github.com/coryodaniel/arborEcto elixir adjacency list and tree traversal. Supports Ecto versions 2 and 3. - coryodaniel/arbor - 871A library that brings all the CSP joy to the Elixir land.
https://github.com/costaraphael/cspexA library that brings all the CSP joy to the Elixir land. - costaraphael/cspex - 872Integrated certification via Let's encrypt for Elixir-powered sites
https://github.com/sasa1977/site_encryptIntegrated certification via Let's encrypt for Elixir-powered sites - GitHub - sasa1977/site_encrypt: Integrated certification via Let's encrypt for Elixir-powered sites - 873Yet another Redis client for Elixir
https://github.com/dantswain/yarYet another Redis client for Elixir. Contribute to dantswain/yar development by creating an account on GitHub. - 874An emulsifying Erlang SOAP library
https://github.com/devinus/detergentAn emulsifying Erlang SOAP library. Contribute to devinus/detergent development by creating an account on GitHub. - 875Simple API for spawning RabbitMQ Producers and Consumers.
https://github.com/Nebo15/rbmqSimple API for spawning RabbitMQ Producers and Consumers. - Nebo15/rbmq - 876A minimal redis client with connection pooling for elixir
https://github.com/akdilsiz/elixir-redisclA minimal redis client with connection pooling for elixir - akdilsiz/elixir-rediscl - 877Neo4j driver for Elixir
https://github.com/florinpatrascu/bolt_sipsNeo4j driver for Elixir. Contribute to florinpatrascu/bolt_sips development by creating an account on GitHub. - 878Convert PDF docs to beautiful HTML files without losing text or format.
https://github.com/ricn/pdf2htmlexConvert PDF docs to beautiful HTML files without losing text or format. - ricn/pdf2htmlex - 879Simple + Powerful interface to the Mnesia Distributed Database 💾
https://github.com/sheharyarn/mementoSimple + Powerful interface to the Mnesia Distributed Database 💾 - sheharyarn/memento - 880PDF generation wrapper for Elixir using Puppeteer
https://github.com/coletiv/puppeteer-pdfPDF generation wrapper for Elixir using Puppeteer. Contribute to coletiv/puppeteer-pdf development by creating an account on GitHub. - 881Sphinx Fulltext Search Client for Elixir Projects (Phoenix Example Included)
https://github.com/Tyler-pierce/giza_sphinxsearchSphinx Fulltext Search Client for Elixir Projects (Phoenix Example Included) - Tyler-pierce/giza_sphinxsearch - 882Elixir driver for the Neo4j graph database server
https://github.com/florinpatrascu/neo4j_sipsElixir driver for the Neo4j graph database server. Contribute to florinpatrascu/neo4j_sips development by creating an account on GitHub. - 883TDS Adapter for Ecto
https://github.com/livehelpnow/tds_ectoTDS Adapter for Ecto. Contribute to livehelpnow/tds_ecto development by creating an account on GitHub. - 884pipelined erlang redis client
https://github.com/heroku/redopipelined erlang redis client. Contribute to heroku/redo development by creating an account on GitHub. - 885Protocols for dalmatinadb
https://github.com/dalmatinerdb/dprotoProtocols for dalmatinadb. Contribute to dalmatinerdb/dproto development by creating an account on GitHub. - 886Data anonymization for your Ecto models !
https://github.com/WTTJ/ecto_anonData anonymization for your Ecto models ! Contribute to WTTJ/ecto_anon development by creating an account on GitHub. - 887MongoDB driver for Elixir
https://github.com/checkiz/elixir-mongoMongoDB driver for Elixir. Contribute to checkiz/elixir-mongo development by creating an account on GitHub. - 888PostgreSQL driver for Elixir
https://github.com/elixir-ecto/postgrexPostgreSQL driver for Elixir. Contribute to elixir-ecto/postgrex development by creating an account on GitHub. - 889Rethinkdb client in pure elixir (JSON protocol)
https://github.com/hamiltop/rethinkdb-elixirRethinkdb client in pure elixir (JSON protocol). Contribute to hamiltop/rethinkdb-elixir development by creating an account on GitHub. - 890Job Queue for Elixir. Clustered or Local. Straight BEAM. Optional Ecto. 💪🍈
https://github.com/koudelka/honeydewJob Queue for Elixir. Clustered or Local. Straight BEAM. Optional Ecto. 💪🍈 - koudelka/honeydew - 891Elixir Priority Queue
https://github.com/falood/queuexElixir Priority Queue. Contribute to falood/queuex development by creating an account on GitHub. - 892Security oriented helper functions for Elixir
https://github.com/aforward/safetyboxSecurity oriented helper functions for Elixir. Contribute to aforward/safetybox development by creating an account on GitHub. - 893rodrigues/red
https://github.com/rodrigues/redContribute to rodrigues/red development by creating an account on GitHub. - 894Elixir Terms Storage, ets wrapper.
https://github.com/meh/extsElixir Terms Storage, ets wrapper. Contribute to meh/exts development by creating an account on GitHub. - 895A message queue framework, with support for middleware and multiple adapters.
https://github.com/conduitframework/conduitA message queue framework, with support for middleware and multiple adapters. - conduitframework/conduit - 896Version bumping and changelog generation for your mix project
https://github.com/mpanarin/versioceVersion bumping and changelog generation for your mix project - mpanarin/versioce - 897dice string parser and roller
https://github.com/olhado/dicerdice string parser and roller. Contribute to olhado/dicer development by creating an account on GitHub. - 898helpful tools for when I need to create an Elixir NIF .
https://github.com/rossjones/niftyhelpful tools for when I need to create an Elixir NIF . - rossjones/nifty - 899DalmatinerDB Query Engine
https://github.com/dalmatinerdb/dqeDalmatinerDB Query Engine. Contribute to dalmatinerdb/dqe development by creating an account on GitHub. - 900A dumb message bus for sharing data between microservices in a relatively decoupled mechanism
https://github.com/aforward/sadbusA dumb message bus for sharing data between microservices in a relatively decoupled mechanism - aforward/sadbus - 901Job processing library for Elixir - compatible with Resque / Sidekiq
https://github.com/akira/exqJob processing library for Elixir - compatible with Resque / Sidekiq - akira/exq - 902Create a deb for your elixir release with ease
https://github.com/johnhamelink/exrm_debCreate a deb for your elixir release with ease. Contribute to johnhamelink/exrm_deb development by creating an account on GitHub. - 903An Elixir library designed to be used as SIP protocol middleware.
https://github.com/balena/elixir-sippetAn Elixir library designed to be used as SIP protocol middleware. - balena/elixir-sippet - 904Elixir library to inflect Russian first, last, and middle names.
https://github.com/petrovich/petrovich_elixirElixir library to inflect Russian first, last, and middle names. - petrovich/petrovich_elixir - 905A bencode encoder and decoder written in Elixir
https://github.com/gausby/bencodeA bencode encoder and decoder written in Elixir. Contribute to gausby/bencode development by creating an account on GitHub. - 906Lorem Ipsum generator for Elixir
https://github.com/mgamini/elixiloremLorem Ipsum generator for Elixir. Contribute to mgamini/elixilorem development by creating an account on GitHub. - 907Ecto.LazyFloat - An Ecto.Float that accepts binary and integers
https://github.com/joshdholtz/ecto-lazy-floatEcto.LazyFloat - An Ecto.Float that accepts binary and integers - joshdholtz/ecto-lazy-float - 908parse mimetypes
https://github.com/camshaft/mimetype_parserparse mimetypes. Contribute to camshaft/mimetype_parser development by creating an account on GitHub. - 909Elixir implementation of the BORSH binary serializer.
https://github.com/alexfilatov/borshElixir implementation of the BORSH binary serializer. - alexfilatov/borsh - 910Erlang Priority Queues
https://github.com/okeuday/pqueueErlang Priority Queues. Contribute to okeuday/pqueue development by creating an account on GitHub. - 911Simple implementation of the hungry-consumer model in Elixir
https://github.com/pragdave/work_queueSimple implementation of the hungry-consumer model in Elixir - pragdave/work_queue - 912Simple Job Processing in Elixir with Mnesia :zap:
https://github.com/sheharyarn/queSimple Job Processing in Elixir with Mnesia :zap:. Contribute to sheharyarn/que development by creating an account on GitHub. - 913Database multitenancy for Elixir applications!
https://github.com/ateliware/triplexDatabase multitenancy for Elixir applications! Contribute to ateliware/triplex development by creating an account on GitHub. - 914Elixir AMQP consumer and publisher behaviours
https://github.com/meltwater/gen_rmqElixir AMQP consumer and publisher behaviours. Contribute to meltwater/gen_rmq development by creating an account on GitHub. - 915Elixir Faktory worker https://hexdocs.pm/faktory_worker
https://github.com/opt-elixir/faktory_workerElixir Faktory worker https://hexdocs.pm/faktory_worker - opt-elixir/faktory_worker - 916Ruby Marshal format implemented in Elixir
https://github.com/gaynetdinov/ex_marshalRuby Marshal format implemented in Elixir. Contribute to gaynetdinov/ex_marshal development by creating an account on GitHub. - 917An Elixir client for beanstalkd
https://github.com/jsvisa/elixir_talkAn Elixir client for beanstalkd. Contribute to jsvisa/elixir_talk development by creating an account on GitHub. - 918dalmatinerdb/ddb_client
https://github.com/dalmatinerdb/ddb_clientContribute to dalmatinerdb/ddb_client development by creating an account on GitHub. - 919Make requests to Tor network with Elixir
https://github.com/alexfilatov/torexMake requests to Tor network with Elixir. Contribute to alexfilatov/torex development by creating an account on GitHub. - 920Simplify your Ecto validation tests
https://github.com/danielberkompas/ecto_validation_caseSimplify your Ecto validation tests. Contribute to danielberkompas/ecto_validation_case development by creating an account on GitHub. - 921Publish your Elixir releases to Heroku with ease.
https://github.com/epsanchezma/exrm-herokuPublish your Elixir releases to Heroku with ease. Contribute to epsanchezma/exrm-heroku development by creating an account on GitHub. - 922Simple key/secret based authentication for APIs
https://github.com/edgurgel/signaturexSimple key/secret based authentication for APIs. Contribute to edgurgel/signaturex development by creating an account on GitHub. - 923RADIUS Protocol on Elixir
https://github.com/bearice/elixir-radiusRADIUS Protocol on Elixir. Contribute to bearice/elixir-radius development by creating an account on GitHub. - 924Base58 encoding/decoding for Elixir
https://github.com/jrdnull/base58Base58 encoding/decoding for Elixir. Contribute to jrdnull/base58 development by creating an account on GitHub. - 925🌍 MQS: AMQP Library
https://github.com/synrc/mqs🌍 MQS: AMQP Library. Contribute to voxoz/mqs development by creating an account on GitHub. - 926Arbitrary precision decimal arithmetic
https://github.com/ericmj/decimalArbitrary precision decimal arithmetic. Contribute to ericmj/decimal development by creating an account on GitHub. - 927Static Site Generator written in Elixir.
https://github.com/BennyHallett/obeliskStatic Site Generator written in Elixir. Contribute to BennyHallett/obelisk development by creating an account on GitHub. - 928Put your Elixir app production release inside minimal docker image
https://github.com/Recruitee/mix_dockerPut your Elixir app production release inside minimal docker image - Recruitee/mix_docker - 929Descriptive Statistics for Elixir
https://github.com/pusewicz/descriptive_statisticsDescriptive Statistics for Elixir. Contribute to pusewicz/descriptive_statistics development by creating an account on GitHub. - 930IP-to-AS-to-ASname lookup for Elixir
https://github.com/ephe-meral/asnIP-to-AS-to-ASname lookup for Elixir . Contribute to ephe-meral/asn development by creating an account on GitHub. - 931Erlang NIF for sqlite
https://github.com/mmzeeman/esqliteErlang NIF for sqlite. Contribute to mmzeeman/esqlite development by creating an account on GitHub. - 932Pure Elixir database driver for MariaDB / MySQL
https://github.com/xerions/mariaexPure Elixir database driver for MariaDB / MySQL. Contribute to xerions/mariaex development by creating an account on GitHub. - 933Stringify your ids
https://github.com/alco/hashids-elixirStringify your ids. Contribute to alco/hashids-elixir development by creating an account on GitHub. - 934An Elixir library for transforming the representation of data
https://github.com/edubkendo/kitsuneAn Elixir library for transforming the representation of data - edubkendo/kitsune - 935Common tasks for Erlang projects that use Mix
https://github.com/alco/mix-erlang-tasksCommon tasks for Erlang projects that use Mix. Contribute to alco/mix-erlang-tasks development by creating an account on GitHub. - 936FiFo Quickcheck helper
https://github.com/project-fifo/fqcFiFo Quickcheck helper. Contribute to project-fifo/fqc development by creating an account on GitHub. - 937an `eunit` task for mix based projects
https://github.com/talentdeficit/mixunitan `eunit` task for mix based projects. Contribute to talentdeficit/mixunit development by creating an account on GitHub. - 938Elixir module for tau
https://github.com/FranklinChen/tauElixir module for tau. Contribute to FranklinChen/tau development by creating an account on GitHub. - 939Ecto plugin with default configuration for repos for testing different ecto plugins with databases
https://github.com/xerions/ecto_itEcto plugin with default configuration for repos for testing different ecto plugins with databases - xerions/ecto_it - 940A helper library for adding templating to web applications
https://github.com/sugar-framework/templatesA helper library for adding templating to web applications - sugar-framework/templates - 941Simplify deployments in Elixir with OTP releases!
https://github.com/bitwalker/distillerySimplify deployments in Elixir with OTP releases! Contribute to bitwalker/distillery development by creating an account on GitHub. - 942Simple and reliable background job processing library for Elixir.
https://github.com/joakimk/toniqSimple and reliable background job processing library for Elixir. - joakimk/toniq - 943Enumerable type in Elixir
https://github.com/KamilLelonek/exnumeratorEnumerable type in Elixir. Contribute to KamilLelonek/exnumerator development by creating an account on GitHub. - 944Cursor-based pagination for Ecto.
https://github.com/Nebo15/ecto_pagingCursor-based pagination for Ecto. Contribute to Nebo15/ecto_paging development by creating an account on GitHub. - 945An Elixir toolkit for performing tasks on one or more servers, built on top of Erlang’s SSH application.
https://github.com/bitcrowd/sshkit.exAn Elixir toolkit for performing tasks on one or more servers, built on top of Erlang’s SSH application. - bitcrowd/sshkit.ex - 946Socket wrapping for Elixir.
https://github.com/meh/elixir-socketSocket wrapping for Elixir. Contribute to meh/elixir-socket development by creating an account on GitHub. - 947Elixir Tel URI parser compatible with RFC3966
https://github.com/marcelog/ex_rfc3966Elixir Tel URI parser compatible with RFC3966. Contribute to marcelog/ex_rfc3966 development by creating an account on GitHub. - 948Wrapper for erlang-mbcs
https://github.com/woxtu/elixir-mbcsWrapper for erlang-mbcs. Contribute to woxtu/elixir-mbcs development by creating an account on GitHub. - 949Plug for API versioning
https://github.com/sticksnleaves/versionaryPlug for API versioning. Contribute to sticksnleaves/versionary development by creating an account on GitHub. - 950Various utility functions for working with the local Wifi network in Elixir. These functions are mostly useful in scripts that could benefit from knowing the current location of the computer or the Wifi surroundings.
https://github.com/gausby/wifiVarious utility functions for working with the local Wifi network in Elixir. These functions are mostly useful in scripts that could benefit from knowing the current location of the computer or the... - 951An Elixir package that provides a Map-like interface (Map/Access/Enumerable/Collectable) backed by an ETS table
https://github.com/antipax/ets_mapAn Elixir package that provides a Map-like interface (Map/Access/Enumerable/Collectable) backed by an ETS table - ericentin/ets_map - 952ssdb client for elixir
https://github.com/lidashuang/ssdb-elixirssdb client for elixir. Contribute to defp/ssdb-elixir development by creating an account on GitHub. - 953Use tags to mix and match your exunit test context
https://github.com/vic/setup_tagUse tags to mix and match your exunit test context - vic/setup_tag - 954A functional query tool for Elixir
https://github.com/robconery/moebiusA functional query tool for Elixir. Contribute to robconery/moebius development by creating an account on GitHub. - 955ESpec for Phoenix web framework.
https://github.com/antonmi/espec_phoenixESpec for Phoenix web framework. Contribute to antonmi/espec_phoenix development by creating an account on GitHub. - 956REST behaviour and Plug router for hypermedia web applications in Elixir
https://github.com/christopheradams/plug_restREST behaviour and Plug router for hypermedia web applications in Elixir - christopheradams/plug_rest - 957Elasticsearch Elixir Bulk Processor is a configurable manager for efficiently inserting data into Elasticsearch. This processor uses GenStages (data-exchange steps) for handling backpressure, and various settings to control the bulk payloads being uploaded to Elasticsearch.
https://github.com/sashman/elasticsearch_elixir_bulk_processorElasticsearch Elixir Bulk Processor is a configurable manager for efficiently inserting data into Elasticsearch. This processor uses GenStages (data-exchange steps) for handling backpressure, and... - 958a Cassandra ORM for Elixir
https://github.com/blitzstudios/tritona Cassandra ORM for Elixir. Contribute to blitzstudios/triton development by creating an account on GitHub. - 959Protocol Buffers in Elixir made easy!
https://github.com/bitwalker/exprotobufProtocol Buffers in Elixir made easy! Contribute to bitwalker/exprotobuf development by creating an account on GitHub. - 960A Riak client written in Elixir.
https://github.com/drewkerrigan/riak-elixir-clientA Riak client written in Elixir. Contribute to drewkerrigan/riak-elixir-client development by creating an account on GitHub. - 961Keep your ETS tables running forever using bouncing GenServers
https://github.com/whitfin/eternalKeep your ETS tables running forever using bouncing GenServers - whitfin/eternal - 962LTSV parser implementation in Elixir
https://github.com/ma2gedev/ltsvexLTSV parser implementation in Elixir. Contribute to ma2gedev/ltsvex development by creating an account on GitHub. - 963Convenient HTML to PDF/A rendering library for Elixir based on Chrome & Ghostscript
https://github.com/bitcrowd/chromic_pdfConvenient HTML to PDF/A rendering library for Elixir based on Chrome & Ghostscript - bitcrowd/chromic_pdf - 964A simple testing DSL for Plugs
https://github.com/xavier/plug_test_helpersA simple testing DSL for Plugs. Contribute to xavier/plug_test_helpers development by creating an account on GitHub. - 965MAC-to-vendor search for Elixir
https://github.com/ephe-meral/macMAC-to-vendor search for Elixir. Contribute to ephe-meral/mac development by creating an account on GitHub. - 966Cayley driver for Elixir
https://github.com/mneudert/caylirCayley driver for Elixir. Contribute to mneudert/caylir development by creating an account on GitHub. - 967A port of ua-parser2 to Elixir. User agent parser library.
https://github.com/nazipov/ua_parser2-elixirA port of ua-parser2 to Elixir. User agent parser library. - nazipov/ua_parser2-elixir - 968A binary hex dumping library in Elixir.
https://github.com/polsab/pretty_hexA binary hex dumping library in Elixir. Contribute to polsab/pretty_hex development by creating an account on GitHub. - 969Port of RSolr to Elixir
https://github.com/dcarneiro/exsolrPort of RSolr to Elixir. Contribute to dcarneiro/exsolr development by creating an account on GitHub. - 970Ecto extension for ordered models
https://github.com/zovafit/ecto-orderedEcto extension for ordered models. Contribute to zovafit/ecto-ordered development by creating an account on GitHub. - 971Pug templates for Elixir
https://github.com/rstacruz/expugPug templates for Elixir. Contribute to rstacruz/expug development by creating an account on GitHub. - 972Bypass provides a quick way to create a custom plug that can be put in place instead of an actual HTTP server to return prebaked responses to client requests.
https://github.com/pspdfkit-labs/bypassBypass provides a quick way to create a custom plug that can be put in place instead of an actual HTTP server to return prebaked responses to client requests. - PSPDFKit-labs/bypass - 973MySQL/OTP – MySQL and MariaDB client for Erlang/OTP
https://github.com/mysql-otp/mysql-otpMySQL/OTP – MySQL and MariaDB client for Erlang/OTP - mysql-otp/mysql-otp - 974Simple SSH helpers for Elixir. SSH is useful, but we all love SSHEx !
https://github.com/rubencaro/sshexSimple SSH helpers for Elixir. SSH is useful, but we all love SSHEx ! - rubencaro/sshex - 975Profanity filter library for Elixir
https://github.com/xavier/expletiveProfanity filter library for Elixir. Contribute to xavier/expletive development by creating an account on GitHub. - 976An Inflector library for Elixir
https://github.com/nurugger07/inflexAn Inflector library for Elixir. Contribute to nurugger07/inflex development by creating an account on GitHub. - 977Native PDF generation for Elixir
https://github.com/SenecaSystems/gutenexNative PDF generation for Elixir. Contribute to tyre/gutenex development by creating an account on GitHub. - 978Create a data stream across your information systems to query, augment and transform data according to Elixir matching rules.
https://github.com/awetzel/adapCreate a data stream across your information systems to query, augment and transform data according to Elixir matching rules. - kbrw/adap - 979edn format parser for the erlang platform
https://github.com/marianoguerra/erldnedn format parser for the erlang platform. Contribute to marianoguerra/erldn development by creating an account on GitHub. - 980Coil is a minimalistic static content engine written in elixir
https://github.com/badosu/coilCoil is a minimalistic static content engine written in elixir - badosu/coil - 981EventSourceEncoder is a Elixir library to encode data into EventSource compliant data.
https://github.com/chatgris/event_source_encoderEventSourceEncoder is a Elixir library to encode data into EventSource compliant data. - chatgris/event_source_encoder - 982Ecto extension to support enums in models
https://github.com/gjaldon/ecto_enumEcto extension to support enums in models. Contribute to gjaldon/ecto_enum development by creating an account on GitHub. - 983Postgres change events (CDC) in Elixir
https://github.com/cpursley/walexPostgres change events (CDC) in Elixir. Contribute to cpursley/walex development by creating an account on GitHub. - 984Ecto adapter for Mnesia Erlang term database.
https://github.com/Nebo15/ecto_mnesiaEcto adapter for Mnesia Erlang term database. Contribute to Nebo15/ecto_mnesia development by creating an account on GitHub. - 985A blazing fast job processing system backed by GenStage & Redis.
https://github.com/scripbox/flumeA blazing fast job processing system backed by GenStage & Redis. - scripbox/flume - 986🎠 Because TDD is awesome
https://github.com/lpil/mix-test.watch🎠 Because TDD is awesome. Contribute to lpil/mix-test.watch development by creating an account on GitHub. - 987A collection of useful mathematical functions in Elixir with a slant towards statistics, linear algebra and machine learning
https://github.com/safwank/NumerixA collection of useful mathematical functions in Elixir with a slant towards statistics, linear algebra and machine learning - safwank/Numerix - 988An elixir module to translate simplified Chinese to traditional Chinese, and vice versa, based on wikipedia data
https://github.com/tyrchen/chinese_translationAn elixir module to translate simplified Chinese to traditional Chinese, and vice versa, based on wikipedia data - tyrchen/chinese_translation - 989Elixir RESTful Framework
https://github.com/falood/maruElixir RESTful Framework . Contribute to elixir-maru/maru development by creating an account on GitHub. - 990An Elixir wrapper around esqlite. Allows access to sqlite3 databases.
https://github.com/mmmries/sqlitexAn Elixir wrapper around esqlite. Allows access to sqlite3 databases. - elixir-sqlite/sqlitex - 991Rebar3 Hex library
https://github.com/hexpm/rebar3_hexRebar3 Hex library. Contribute to erlef/rebar3_hex development by creating an account on GitHub. - 992Sentiment analysis based on afinn-165, emojis and some enhancements.
https://github.com/uesteibar/veritaserumSentiment analysis based on afinn-165, emojis and some enhancements. - uesteibar/veritaserum - 993Database URL parser for Elixir
https://github.com/s-m-i-t-a/database_urlDatabase URL parser for Elixir. Contribute to s-m-i-t-a/database_url development by creating an account on GitHub. - 994The Text Mining Elixir
https://github.com/pjhampton/woollyThe Text Mining Elixir. Contribute to pjhampton/woolly development by creating an account on GitHub. - 995Ecto type for saving encrypted passwords using Comeonin
https://github.com/vic/comeonin_ecto_passwordEcto type for saving encrypted passwords using Comeonin - vic/comeonin_ecto_password - 996Tool that allows to write Erlang NIF libraries in Haskell
https://github.com/urbanserj/hsnifTool that allows to write Erlang NIF libraries in Haskell - urbanserj/hsnif - 997Elixir port of Nakatani Shuyo's natural language detector
https://github.com/dannote/tongueElixir port of Nakatani Shuyo's natural language detector - abiko-search/tongue - 998An Elixir library that provides a simple DSL for seeding databases through Ecto.
https://github.com/seaneshbaugh/exseedAn Elixir library that provides a simple DSL for seeding databases through Ecto. - seaneshbaugh/exseed - 999✏ MTX: Metrics Client
https://github.com/synrc/mtx✏ MTX: Metrics Client . Contribute to voxoz/mtx development by creating an account on GitHub. - 1000Emoji mapping to emoji converter to examine metaprogramming in Elixir.
https://github.com/danigulyas/smileEmoji mapping to emoji converter to examine metaprogramming in Elixir. - goulashify/smile - 1001Object Relational Mapper for Elixir
https://github.com/chrismccord/atlasObject Relational Mapper for Elixir. Contribute to chrismccord/atlas development by creating an account on GitHub. - 1002Transactional job queue with Ecto, PostgreSQL and GenStage
https://github.com/mbuhot/ecto_jobTransactional job queue with Ecto, PostgreSQL and GenStage - mbuhot/ecto_job - 1003A TOML parser for elixir
https://github.com/zamith/tomlexA TOML parser for elixir. Contribute to zamith/tomlex development by creating an account on GitHub. - 1004A static site generator for mid-sized sites.
https://github.com/pablomartinezalvarez/glayuA static site generator for mid-sized sites. Contribute to pablomartinezalvarez/glayu development by creating an account on GitHub. - 1005Mustache for Elixir
https://github.com/jui/mustachexMustache for Elixir. Contribute to jui/mustachex development by creating an account on GitHub. - 1006Run test when file is saved
https://github.com/joaothallis/elixir-auto-testRun test when file is saved. Contribute to joaothallis/elixir-auto-test development by creating an account on GitHub. - 1007Simplify comparison of Elixir data structures by ensuring fields are present but ignoring their values.
https://github.com/campezzi/ignorantSimplify comparison of Elixir data structures by ensuring fields are present but ignoring their values. - campezzi/ignorant - 1008A set of helpers to create http-aware modules that are easy to test.
https://github.com/Driftrock/mockingbirdA set of helpers to create http-aware modules that are easy to test. - GitHub - Driftrock/mockingbird: A set of helpers to create http-aware modules that are easy to test. - 1009Create PDFs with wkhtmltopdf or puppeteer/chromium from Elixir.
https://github.com/gutschilla/elixir-pdf-generatorCreate PDFs with wkhtmltopdf or puppeteer/chromium from Elixir. - gutschilla/elixir-pdf-generator - 1010Disque is a distributed message broker
https://github.com/antirez/disqueDisque is a distributed message broker. Contribute to antirez/disque development by creating an account on GitHub. - 1011HL7 Parser for Elixir
https://github.com/jcomellas/ex_hl7HL7 Parser for Elixir. Contribute to jcomellas/ex_hl7 development by creating an account on GitHub. - 1012Cirru Parser in Elixir
https://github.com/Cirru/parser.exCirru Parser in Elixir. Contribute to Cirru/parser.ex development by creating an account on GitHub. - 1013Check if your password has been pwned
https://github.com/thiamsantos/pwnedCheck if your password has been pwned. Contribute to thiamsantos/pwned development by creating an account on GitHub. - 1014DEPRECATED : An Elixir library (driver) for clients communicating with MQTT brokers(via the MQTT 3.1.1 protocol).
https://github.com/suvash/hulaakiDEPRECATED : An Elixir library (driver) for clients communicating with MQTT brokers(via the MQTT 3.1.1 protocol). - suvash/hulaaki - 1015Minimal implementation of Ruby's factory_girl in Elixir.
https://github.com/sinetris/factory_girl_elixirMinimal implementation of Ruby's factory_girl in Elixir. - sinetris/factory_girl_elixir - 1016Desktop notifications for ExUnit
https://github.com/navinpeiris/ex_unit_notifierDesktop notifications for ExUnit. Contribute to navinpeiris/ex_unit_notifier development by creating an account on GitHub. - 1017Elixir library to help selecting the right elements in your tests.
https://github.com/DefactoSoftware/test_selectorElixir library to help selecting the right elements in your tests. - DefactoSoftware/test_selector - 1018Automatic migrations for ecto
https://github.com/xerions/ecto_migrateAutomatic migrations for ecto. Contribute to xerions/ecto_migrate development by creating an account on GitHub. - 1019You need more reagents to conjure this server.
https://github.com/meh/reagentYou need more reagents to conjure this server. Contribute to meh/reagent development by creating an account on GitHub. - 1020HTTP request stubbing and expectation Elixir library
https://github.com/stevegraham/hypermockHTTP request stubbing and expectation Elixir library - stevegraham/hypermock - 1021Statistical functions and distributions for Elixir
https://github.com/msharp/elixir-statisticsStatistical functions and distributions for Elixir - msharp/elixir-statistics - 1022colorful is justice
https://github.com/Joe-noh/colorfulcolorful is justice. Contribute to Joe-noh/colorful development by creating an account on GitHub. - 1023HTML as code in Elixir
https://github.com/ijcd/taggartHTML as code in Elixir. Contribute to ijcd/taggart development by creating an account on GitHub. - 1024Build software better, together
https://github.com/gpedic/ex_shortuuid.GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 1025A library for run-time system code line-level coverage analysis.
https://github.com/yeshan333/ex_integration_coverallsA library for run-time system code line-level coverage analysis. - yeshan333/ex_integration_coveralls - 1026Output test coverage information in Cobertura-compatible format
https://github.com/PSPDFKit-labs/cobertura_coverOutput test coverage information in Cobertura-compatible format - PSPDFKit-labs/cobertura_cover - 1027Erlang driver for nanomsg
https://github.com/basho/enmErlang driver for nanomsg. Contribute to basho/enm development by creating an account on GitHub. - 1028Ecto PostgreSQL database performance insights. Locks, index usage, buffer cache hit ratios, vacuum stats and more.
https://github.com/pawurb/ecto_psql_extrasEcto PostgreSQL database performance insights. Locks, index usage, buffer cache hit ratios, vacuum stats and more. - pawurb/ecto_psql_extras - 1029Client Libraries for Erlang
https://github.com/crate/craterlClient Libraries for Erlang. Contribute to crate/craterl development by creating an account on GitHub. - 1030Ecto Model shortcuts to make your life easier! :tada:
https://github.com/sheharyarn/ecto_rutEcto Model shortcuts to make your life easier! :tada: - sheharyarn/ecto_rut - 1031Adapter for the Calendar library in Ecto
https://github.com/lau/calectoAdapter for the Calendar library in Ecto. Contribute to lau/calecto development by creating an account on GitHub. - 1032Allow you to make custom base conversion in Elixir.
https://github.com/igas/custom_baseAllow you to make custom base conversion in Elixir. - igas/custom_base - 1033CIDR library for Elixir that is compatible with Erlang's :inet and supports both IPv4 and IPv6
https://github.com/cobenian/inet_cidrCIDR library for Elixir that is compatible with Erlang's :inet and supports both IPv4 and IPv6 - Cobenian/inet_cidr - 1034BDD-like syntax for ExUnit
https://github.com/drewolson/ex_specBDD-like syntax for ExUnit. Contribute to drewolson/ex_spec development by creating an account on GitHub. - 1035Evaluate user input expressions
https://github.com/balance-platform/ex_pressionEvaluate user input expressions. Contribute to balance-platform/ex_pression development by creating an account on GitHub. - 1036An Ecto adapter for the Ravix RavenDB Driver
https://github.com/YgorCastor/ravix-ectoAn Ecto adapter for the Ravix RavenDB Driver. Contribute to YgorCastor/ravix-ecto development by creating an account on GitHub. - 1037Collection of ssl verification functions for Erlang
https://github.com/deadtrickster/ssl_verify_fun.erlCollection of ssl verification functions for Erlang - deadtrickster/ssl_verify_fun.erl - 1038Dynamically convert the case of your JSON API keys
https://github.com/sticksnleaves/accentDynamically convert the case of your JSON API keys - malomohq/accent - 1039A fast, easy to use and 100% conformant Elixir library for Google Protocol Buffers (aka protobuf)
https://github.com/ahamez/protoxA fast, easy to use and 100% conformant Elixir library for Google Protocol Buffers (aka protobuf) - ahamez/protox - 1040A wrapper for NMAP written in Elixir.
https://github.com/fklement/hadesA wrapper for NMAP written in Elixir. Contribute to fklement/hades development by creating an account on GitHub. - 1041Provides idiomatic Elixir bindings for Apache Thrift
https://github.com/pinterest/riffedProvides idiomatic Elixir bindings for Apache Thrift - pinterest/riffed - 1042Porter Stemmer in Elixir ~> 1.0.0
https://github.com/frpaulas/porterstemmerPorter Stemmer in Elixir ~> 1.0.0. Contribute to frpaulas/porterstemmer development by creating an account on GitHub. - 1043ShortUUID is a simple UUID shortener for Elixir.
https://github.com/gpedic/ex_shortuuidShortUUID is a simple UUID shortener for Elixir. Contribute to gpedic/ex_shortuuid development by creating an account on GitHub. - 1044OTP application for generating blog posts from a Git repository containing markdown files.
https://github.com/meddle0x53/blogitOTP application for generating blog posts from a Git repository containing markdown files. - meddle0x53/blogit - 1045A minimal filesystem-based publishing engine with Markdown support and code highlighting
https://github.com/dashbitco/nimble_publisherA minimal filesystem-based publishing engine with Markdown support and code highlighting - dashbitco/nimble_publisher - 1046Classless Inter-Domain Routing (CIDR) for Elixir
https://github.com/c-rack/cidr-elixirClassless Inter-Domain Routing (CIDR) for Elixir. Contribute to c-rack/cidr-elixir development by creating an account on GitHub. - 1047Redis commands for Elixir
https://github.com/artemeff/exredisRedis commands for Elixir. Contribute to artemeff/redis development by creating an account on GitHub. - 1048Validação,Formatação e Gerador Cpf/Cnpj em Elixir
https://github.com/williamgueiros/BrcpfcnpjValidação,Formatação e Gerador Cpf/Cnpj em Elixir. Contribute to williamgueiros/Brcpfcnpj development by creating an account on GitHub. - 1049HTTP Service Performance & Load Testing Framework
https://github.com/polleverywhere/chaperonHTTP Service Performance & Load Testing Framework. Contribute to polleverywhere/chaperon development by creating an account on GitHub. - 1050chinese pinyin lib for elixir
https://github.com/lidashuang/pinyinchinese pinyin lib for elixir. Contribute to defp/pinyin development by creating an account on GitHub. - 1051Generate Heroku-like memorable random names to use in your apps or anywhere else.
https://github.com/knrz/HaikunatorGenerate Heroku-like memorable random names to use in your apps or anywhere else. - CyrusOfEden/haikunator - 1052a library to handle bencode in elixir
https://github.com/alehander42/bencodera library to handle bencode in elixir. Contribute to alehander92/bencoder development by creating an account on GitHub. - 1053colors util written in Elixir
https://github.com/lidashuang/colorscolors util written in Elixir. Contribute to defp/colors development by creating an account on GitHub. - 1054Algolia integration to elixir application
https://github.com/WTTJ/algoliaxAlgolia integration to elixir application. Contribute to WTTJ/algoliax development by creating an account on GitHub. - 1055Track and record all the changes in your database with Ecto. Revert back to anytime in history.
https://github.com/izelnakri/paper_trailTrack and record all the changes in your database with Ecto. Revert back to anytime in history. - izelnakri/paper_trail - 1056gniquil/ex_brace_expansion
https://github.com/gniquil/ex_brace_expansionContribute to gniquil/ex_brace_expansion development by creating an account on GitHub. - 1057Fast, simple, and robust Cassandra/ScyllaDB driver for Elixir.
https://github.com/lexhide/xandraFast, simple, and robust Cassandra/ScyllaDB driver for Elixir. - whatyouhide/xandra - 1058Elixir Adapter for EventStore
https://github.com/exponentially/extremeElixir Adapter for EventStore. Contribute to exponentially/extreme development by creating an account on GitHub. - 1059Ecto adapter for GitHub API
https://github.com/wojtekmach/github_ectoEcto adapter for GitHub API. Contribute to wojtekmach/github_ecto development by creating an account on GitHub. - 1060Mix task to create mix projects that builds into Docker containers.
https://github.com/Nebo15/renewMix task to create mix projects that builds into Docker containers. - Nebo15/renew - 1061Elixir wrapper around the Erlang module, eleveldb.
https://github.com/skovsgaard/exleveldbElixir wrapper around the Erlang module, eleveldb. - skovsgaard/exleveldb - 1062Simple sentiment analysis using the AFINN-111 word list
https://github.com/dantame/sentientSimple sentiment analysis using the AFINN-111 word list - dantame/sentient - 1063A micro library for converting non-english digits in elixir.
https://github.com/alisinabh/numeroA micro library for converting non-english digits in elixir. - alisinabh/Numero - 1064Caustic Elixir Cryptocurrency Library (Bitcoin, Ethereum, etc.) with extensive cryptography and number theory library
https://github.com/agro1986/causticCaustic Elixir Cryptocurrency Library (Bitcoin, Ethereum, etc.) with extensive cryptography and number theory library - agro1986/caustic - 1065A Slugger for elixir.
https://github.com/h4cc/sluggerA Slugger for elixir. Contribute to h4cc/slugger development by creating an account on GitHub. - 1066Faker is a pure Elixir library for generating fake data.
https://github.com/igas/fakerFaker is a pure Elixir library for generating fake data. - elixirs/faker - 1067Elixir testing libraries with nested contexts, superior readability, and ease of use
https://github.com/batate/shouldiElixir testing libraries with nested contexts, superior readability, and ease of use - batate/shouldi - 1068Static website generator for Elixir fans
https://github.com/Dalgona/SerumStatic website generator for Elixir fans. Contribute to Dalgona/Serum development by creating an account on GitHub. - 1069:sunglasses: Emoji encoding swiss army knife for Elixir/Erlang
https://github.com/mroth/exmoji:sunglasses: Emoji encoding swiss army knife for Elixir/Erlang - mroth/exmoji - 1070Elixir library client for work with ClickHouse
https://github.com/sofakingworld/pillarElixir library client for work with ClickHouse. Contribute to balance-platform/pillar development by creating an account on GitHub. - 1071Ergonomic Mocking for Elixir
https://github.com/ihumanable/patchErgonomic Mocking for Elixir. Contribute to ihumanable/patch development by creating an account on GitHub. - 1072A templating library for generating reusable Elixir projects
https://github.com/rwdaigle/exgenA templating library for generating reusable Elixir projects - rwdaigle/exgen - 1073Data generation and property-based testing for Elixir. 🔮
https://github.com/whatyouhide/stream_dataData generation and property-based testing for Elixir. 🔮 - whatyouhide/stream_data - 1074SOCKS4, SOCKS4a and SOCKS5 protocols implementation in Erlang/OTP.
https://github.com/surik/tunnerlSOCKS4, SOCKS4a and SOCKS5 protocols implementation in Erlang/OTP. - surik/tunnerl - 1075PropEr: a QuickCheck-inspired property-based testing tool for Erlang
https://github.com/manopapad/properPropEr: a QuickCheck-inspired property-based testing tool for Erlang - proper-testing/proper - 1076JSON-related helpers for your Elixir testing needs
https://github.com/facto/test_that_jsonJSON-related helpers for your Elixir testing needs - joshrieken/test_that_json - 1077Idiomatic Elixir client for RabbitMQ
https://github.com/pma/amqpIdiomatic Elixir client for RabbitMQ. Contribute to pma/amqp development by creating an account on GitHub. - 1078Chatter library for Elixir, provides a secure broadcast between nodes.
https://github.com/dbeck/chatter_exChatter library for Elixir, provides a secure broadcast between nodes. - dbeck/chatter_ex - 1079Ectophile is an extension for Ecto models to instantly support file uploads.
https://github.com/gjaldon/ectophileEctophile is an extension for Ecto models to instantly support file uploads. - gjaldon/ectophile - 1080A polite, well mannered and thoroughly upstanding testing framework for Elixir
https://github.com/josephwilk/amritaA polite, well mannered and thoroughly upstanding testing framework for Elixir - josephwilk/amrita - 1081Shortcuts for common operations in ecto
https://github.com/MishaConway/ecto_shortcutsShortcuts for common operations in ecto. Contribute to MishaConway/ecto_shortcuts development by creating an account on GitHub. - 1082Unobtrusive Dependency Injector for Elixir
https://github.com/definject/definjectUnobtrusive Dependency Injector for Elixir. Contribute to jechol/definject development by creating an account on GitHub. - 1083ToxiproxyEx is an Elixir API client for the resilience testing tool Toxiproxy.
https://github.com/Jcambass/toxiproxy_exToxiproxyEx is an Elixir API client for the resilience testing tool Toxiproxy. - Jcambass/toxiproxy_ex - 1084A BDD library for Elixir developers
https://github.com/wesovilabs/exkorpionA BDD library for Elixir developers. Contribute to wesovilabs/exkorpion development by creating an account on GitHub. - 1085NEAR API in Elixir - a library for DApps development on the NEAR blockchain platform
https://github.com/alexfilatov/near_apiNEAR API in Elixir - a library for DApps development on the NEAR blockchain platform - alexfilatov/near-api-ex - 1086A mocking library for Erlang
https://github.com/eproxus/meckA mocking library for Erlang. Contribute to eproxus/meck development by creating an account on GitHub. - 1087Concurrent and multi-stage data ingestion and data processing with Elixir
https://github.com/dashbitco/broadwayConcurrent and multi-stage data ingestion and data processing with Elixir - dashbitco/broadway - 1088Elixir <-> Redis datastructure adapter
https://github.com/ephe-meral/ex_siderElixir <-> Redis datastructure adapter. Contribute to ephe-meral/ex_sider development by creating an account on GitHub. - 1089An opinionated Elixir wrapper around brod, the Erlang Kafka client, that supports encrypted connections to Heroku Kafka out of the box.
https://github.com/spreedly/kaffeAn opinionated Elixir wrapper around brod, the Erlang Kafka client, that supports encrypted connections to Heroku Kafka out of the box. - spreedly/kaffe - 1090Create a rpm for your elixir release with ease
https://github.com/smpallen99/exrm-rpmCreate a rpm for your elixir release with ease. Contribute to smpallen99/exrm-rpm development by creating an account on GitHub. - 1091💿 KVS: NVMe Key-Value Store
https://github.com/synrc/kvs💿 KVS: NVMe Key-Value Store. Contribute to synrc/kvs development by creating an account on GitHub. - 1092A BDD framework for your Elixir projects
https://github.com/sproutapp/pavlovA BDD framework for your Elixir projects. Contribute to sproutapp/pavlov development by creating an account on GitHub. - 1093Swagger based document driven development for ExUnit
https://github.com/coryodaniel/apocryphalSwagger based document driven development for ExUnit - coryodaniel/apocryphal - 1094Interactive watch mode for Elixir's mix test. https://hexdocs.pm/mix_test_interactive/
https://github.com/influxdata/mix_test_interactiveInteractive watch mode for Elixir's mix test. https://hexdocs.pm/mix_test_interactive/ - randycoulman/mix_test_interactive - 1095Parses and evaluates mathematical expressions in Elixir. Inspired by math.js
https://github.com/narrowtux/abacusParses and evaluates mathematical expressions in Elixir. Inspired by math.js - narrowtux/abacus - 1096Snapshot testing for Elixir
https://github.com/zachallaun/mnemeSnapshot testing for Elixir. Contribute to zachallaun/mneme development by creating an account on GitHub. - 1097Referer parser library
https://github.com/elixytics/ref_inspectorReferer parser library. Contribute to elixir-inspector/ref_inspector development by creating an account on GitHub. - 1098hypermedia api toolkit
https://github.com/exstruct/mazurkahypermedia api toolkit. Contribute to exstruct/mazurka development by creating an account on GitHub. - 1099Convenience library for random base64 strings modeled after my love for Ruby's SecureRandom
https://github.com/patricksrobertson/secure_random.exConvenience library for random base64 strings modeled after my love for Ruby's SecureRandom - patricksrobertson/secure_random.ex - 1100Ecto type which adds support for ShortUUID in Ecto schemas
https://github.com/gpedic/ecto_shortuuidEcto type which adds support for ShortUUID in Ecto schemas - gpedic/ecto_shortuuid - 1101A REST API testing framework for erlang
https://github.com/FabioBatSilva/efrisbyA REST API testing framework for erlang. Contribute to FabioBatSilva/efrisby development by creating an account on GitHub. - 1102Bitcoin utilities in Elixir
https://github.com/RiverFinancial/bitcoinexBitcoin utilities in Elixir. Contribute to RiverFinancial/bitcoinex development by creating an account on GitHub. - 1103Partitioned ETS tables for Erlang and Elixir
https://github.com/cabol/shardsPartitioned ETS tables for Erlang and Elixir. Contribute to cabol/shards development by creating an account on GitHub. - 1104Another scheduling system, focusing on the collection of results for one-time tasks, written in Elixir
https://github.com/Hentioe/honeycombAnother scheduling system, focusing on the collection of results for one-time tasks, written in Elixir - Hentioe/honeycomb - 1105Easy. Simple. Powerful. Generate (complex) SQL queries using magical Elixir SQL dust.
https://github.com/bettyblocks/sql_dustEasy. Simple. Powerful. Generate (complex) SQL queries using magical Elixir SQL dust. - bettyblocks/sql_dust - 1106Elixir PCAP library
https://github.com/cobenian/expcapElixir PCAP library. Contribute to Cobenian/expcap development by creating an account on GitHub. - 1107🍞 Story BDD tool for elixir using gherkin
https://github.com/meadsteve/white-bread🍞 Story BDD tool for elixir using gherkin. Contribute to meadery/white-bread development by creating an account on GitHub. - 1108Power Assert in Elixir. Shows evaluation results each expression.
https://github.com/ma2gedev/power_assert_exPower Assert in Elixir. Shows evaluation results each expression. - ma2gedev/power_assert_ex - 1109A simple Elixir package to elegantly mock module functions within (asynchronous) ExUnit tests using Erlang's :meck library
https://github.com/archan937/mecks_unitA simple Elixir package to elegantly mock module functions within (asynchronous) ExUnit tests using Erlang's :meck library - archan937/mecks_unit - 1110Create elixir functions with SQL as a body.
https://github.com/fazibear/defqlCreate elixir functions with SQL as a body. Contribute to fazibear/defql development by creating an account on GitHub. - 1111Simple injectable test dependencies for Elixir
https://github.com/sonerdy/doubleSimple injectable test dependencies for Elixir. Contribute to sonerdy/double development by creating an account on GitHub. - 1112moved to https://github.com/pouriya/sockerl - Sockerl is an advanced Erlang/Elixir socket framework for TCP protocols and provides fast, useful and easy-to-use API for implementing servers, clients and client connection pools.
https://github.com/Pouriya-Jahanbakhsh/sockerlmoved to https://github.com/pouriya/sockerl - Sockerl is an advanced Erlang/Elixir socket framework for TCP protocols and provides fast, useful and easy-to-use API for implementing servers, client... - 1113Yet another South American rodent...a Capybara like web app testing tool for Elixir.
https://github.com/stuart/tuco_tucoYet another South American rodent...a Capybara like web app testing tool for Elixir. - stuart/tuco_tuco - 1114A HBase driver for Erlang/Elixir using Jinterface and the Asynchbase Java client to query the database.
https://github.com/novabyte/diverA HBase driver for Erlang/Elixir using Jinterface and the Asynchbase Java client to query the database. - novabyte/diver - 1115No-nonsense Elasticsearch library for Elixir
https://github.com/infinitered/elasticsearch-elixirNo-nonsense Elasticsearch library for Elixir. Contribute to danielberkompas/elasticsearch-elixir development by creating an account on GitHub. - 1116An elixir haml parser
https://github.com/nurugger07/calliopeAn elixir haml parser. Contribute to nurugger07/calliope development by creating an account on GitHub. - 1117MT940 parser for Elixir
https://github.com/my-flow/mt940MT940 parser for Elixir. Contribute to my-flow/mt940 development by creating an account on GitHub. - 1118The new home of the Unicode Common Locale Data Repository
https://github.com/kipcole9/cldrThe new home of the Unicode Common Locale Data Repository - kipcole9/cldr - 1119Apache Druid client for Elixir
https://github.com/gameanalytics/panoramixApache Druid client for Elixir. Contribute to GameAnalytics/panoramix development by creating an account on GitHub. - 1120A couchdb connector for Elixir
https://github.com/locolupo/couchdb_connectorA couchdb connector for Elixir. Contribute to mkrogemann/couchdb_connector development by creating an account on GitHub. - 1121gjaldon/base58check
https://github.com/gjaldon/base58checkContribute to gjaldon/base58check development by creating an account on GitHub. - 1122Elixir range utilities: constant-time random sampling and set operations.
https://github.com/lnikkila/elixir-range-extrasElixir range utilities: constant-time random sampling and set operations. - lnikkila/elixir-range-extras - 1123An Elixir library for converting from and to arbitrary bases.
https://github.com/whatyouhide/convertatAn Elixir library for converting from and to arbitrary bases. - whatyouhide/convertat - 1124Minimalistic HTML templates for Elixir, inspired by Slim.
https://github.com/slime-lang/slimeMinimalistic HTML templates for Elixir, inspired by Slim. - slime-lang/slime - 1125Create test data for Elixir applications
https://github.com/thoughtbot/ex_machinaCreate test data for Elixir applications. Contribute to beam-community/ex_machina development by creating an account on GitHub. - 1126HTML tag-safe string truncation
https://github.com/seankay/curtailHTML tag-safe string truncation. Contribute to seankay/curtail development by creating an account on GitHub. - 1127antp/kovacs
https://github.com/antp/kovacsContribute to antp/kovacs development by creating an account on GitHub. - 1128A simple HTTP load tester in Elixir
https://github.com/benjamintanweihao/blitzyA simple HTTP load tester in Elixir. Contribute to benjamintanweihao/blitzy development by creating an account on GitHub. - 1129Binary pattern match Based Mustache template engine for Erlang/OTP.
https://github.com/soranoba/bbmustacheBinary pattern match Based Mustache template engine for Erlang/OTP. - soranoba/bbmustache - 1130Bencode implemented in Elixir
https://github.com/AntonFagerberg/elixir_bencodeBencode implemented in Elixir. Contribute to AntonFagerberg/elixir_bencode development by creating an account on GitHub. - 1131Elixir wrapper of Basho's Bitcask Key/Value store.
https://github.com/JonGretar/ExBitcaskElixir wrapper of Basho's Bitcask Key/Value store. - JonGretar/ExBitcask - 1132TaskBunny is a background processing application written in Elixir and uses RabbitMQ as a messaging backend
https://github.com/shinyscorpion/task_bunnyTaskBunny is a background processing application written in Elixir and uses RabbitMQ as a messaging backend - shinyscorpion/task_bunny - 1133Ravix is an Elixir Client for the amazing RavenDB
https://github.com/YgorCastor/ravixRavix is an Elixir Client for the amazing RavenDB. Contribute to YgorCastor/ravix development by creating an account on GitHub. - 1134A library to declaratively write testable effects
https://github.com/bravobike/efxA library to declaratively write testable effects. Contribute to bravobike/efx development by creating an account on GitHub. - 1135Blogs, docs, and static pages in Phoenix
https://github.com/jsonmaur/phoenix-pagesBlogs, docs, and static pages in Phoenix. Contribute to jsonmaur/phoenix-pages development by creating an account on GitHub. - 1136Isolate tests from the real world, inspired by Ruby's VCR.
https://github.com/derekkraan/walkmanIsolate tests from the real world, inspired by Ruby's VCR. - derekkraan/walkman - 1137ponos is a simple yet powerful load generator written in erlang
https://github.com/klarna/ponosponos is a simple yet powerful load generator written in erlang - klarna/ponos - 1138See Nerves.WpaSupplicant now
https://github.com/fhunleth/wpa_supplicant.exSee Nerves.WpaSupplicant now. Contribute to fhunleth/wpa_supplicant.ex development by creating an account on GitHub. - 1139A simple Elasticsearch REST client written in Elixir.
https://github.com/werbitzky/elastixA simple Elasticsearch REST client written in Elixir. - werbitzky/elastix - 1140Concurrent browser tests for your Elixir web apps.
https://github.com/keathley/wallabyConcurrent browser tests for your Elixir web apps. - elixir-wallaby/wallaby - 1141Neo4j models, for Neo4j.Sips
https://github.com/florinpatrascu/neo4j_sips_modelsNeo4j models, for Neo4j.Sips. Contribute to florinpatrascu/neo4j_sips_models development by creating an account on GitHub. - 1142Remove Emoji 😈🈲😱⁉️ ( for Elixir 1.4+ ~ 1.10.x )
https://github.com/guanting112/elixir_remove_emojiRemove Emoji 😈🈲😱⁉️ ( for Elixir 1.4+ ~ 1.10.x ) . Contribute to guanting112/elixir_remove_emoji development by creating an account on GitHub. - 1143Flexible type conversion lightweight library
https://github.com/ByeongUkChoi/transformerFlexible type conversion lightweight library. Contribute to ByeongUkChoi/transformer development by creating an account on GitHub. - 1144A simple module for Hex encoding / decoding in Elixir.
https://github.com/rjsamson/hexateA simple module for Hex encoding / decoding in Elixir. - rjsamson/hexate - 1145[unmaintained] FakerElixir generates fake data for you.
https://github.com/GesJeremie/faker-elixir[unmaintained] FakerElixir generates fake data for you. - GitHub - GesJeremie/faker-elixir: [unmaintained] FakerElixir generates fake data for you. - 1146Erlang Redis client
https://github.com/wooga/eredisErlang Redis client. Contribute to wooga/eredis development by creating an account on GitHub. - 1147Build software better, together
https://github.com/weavejester/hiccup.GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 1148Build software better, together
https://github.com/Vesuvium/dummyGitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 1149Mustache templates for Elixir
https://github.com/schultyy/Mustache.exMustache templates for Elixir. Contribute to schultyy/Mustache.ex development by creating an account on GitHub. - 1150A Unique Names Generator built in Elixir
https://github.com/jongirard/unique_names_generatorA Unique Names Generator built in Elixir. Contribute to jongirard/unique_names_generator development by creating an account on GitHub. - 1151An Elixir library for parsing and evaluating mathematical expressions
https://github.com/Rob-bie/ExprAn Elixir library for parsing and evaluating mathematical expressions - Rob-bie/expr - 1152Property-based testing library for Elixir (QuickCheck style).
https://github.com/parroty/excheckProperty-based testing library for Elixir (QuickCheck style). - parroty/excheck - 1153Build software better, together
https://github.com/senecasystems/hstoreGitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 1154A Elixir module to generate a random string based on a given string pattern.
https://github.com/caioceccon/random_string_generatorA Elixir module to generate a random string based on a given string pattern. - caioceccon/random_string_generator - 1155Render Elixir data-structures to HTML, inspired by Hiccup.
https://github.com/JuneKelly/sneezeRender Elixir data-structures to HTML, inspired by Hiccup. - JuneKelly/sneeze - 1156Execute and control OS processes from Erlang/OTP
https://github.com/saleyn/erlexecExecute and control OS processes from Erlang/OTP. Contribute to saleyn/erlexec development by creating an account on GitHub. - 1157Data generation framework for Elixir
https://github.com/batate/blacksmithData generation framework for Elixir. Contribute to batate/blacksmith development by creating an account on GitHub. - 1158Erlang Native UUID Generation
https://github.com/okeuday/uuidErlang Native UUID Generation. Contribute to okeuday/uuid development by creating an account on GitHub. - 1159💎 Robust job processing in Elixir, backed by modern PostgreSQL and SQLite3
https://github.com/sorentwo/oban💎 Robust job processing in Elixir, backed by modern PostgreSQL and SQLite3 - oban-bg/oban - 1160Extensible Data Notation
https://github.com/edn-format/ednExtensible Data Notation. Contribute to edn-format/edn development by creating an account on GitHub. - 1161Safe Rust bridge for creating Erlang NIF functions
https://github.com/hansihe/RustlerSafe Rust bridge for creating Erlang NIF functions - rusterlium/rustler - 1162A Ruby natural language processor.
https://github.com/abitdodgy/words_countedA Ruby natural language processor. Contribute to abitdodgy/words_counted development by creating an account on GitHub. - 1163Elixir Unit Converter
https://github.com/carturoch/ex_ucElixir Unit Converter. Contribute to carturoch/ex_uc development by creating an account on GitHub. - 1164A lightweight solution for handling and storing money.
https://github.com/theocodes/monetizedA lightweight solution for handling and storing money. - theocodes/monetized - 1165Build software better, together
https://github.com/Revmaker/gremlexGitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 1166Base62 encoder/decoder in pure Elixir
https://github.com/igas/base62Base62 encoder/decoder in pure Elixir. Contribute to elixirs/base62 development by creating an account on GitHub. - 1167Test the Elixir code in your markdown files!
https://github.com/MainShayne233/markdown_testTest the Elixir code in your markdown files! Contribute to MainShayne233/markdown_test development by creating an account on GitHub. - 1168Simple mocking library for asynchronous testing in Elixir.
https://github.com/appunite/mockerySimple mocking library for asynchronous testing in Elixir. - appunite/mockery - 1169Mocks and explicit contracts in Elixir
https://github.com/dashbitco/moxMocks and explicit contracts in Elixir. Contribute to dashbitco/mox development by creating an account on GitHub. - 1170Quick Erlang Random Number Generation
https://github.com/okeuday/quickrandQuick Erlang Random Number Generation. Contribute to okeuday/quickrand development by creating an account on GitHub. - 1171This library support parameterized test with test_with_params macro.
https://github.com/KazuCocoa/ex_parameterizedThis library support parameterized test with test_with_params macro. - KazuCocoa/ex_parameterized - 1172Elixir port of NanoID, a secure and URL-friendly unique ID generator. https://hex.pm/packages/nanoid
https://github.com/railsmechanic/nanoidElixir port of NanoID, a secure and URL-friendly unique ID generator. https://hex.pm/packages/nanoid - railsmechanic/nanoid - 1173KATT (Klarna API Testing Tool) is an HTTP-based API testing tool for Erlang.
https://github.com/for-GET/kattKATT (Klarna API Testing Tool) is an HTTP-based API testing tool for Erlang. - for-GET/katt - 1174Pure random data generation library, appropriate for realistic simulations in the Erlang ecosystem
https://github.com/mrdimosthenis/minigenPure random data generation library, appropriate for realistic simulations in the Erlang ecosystem - mrdimosthenis/minigen - 1175A library for defining modular dependencies (fixtures) for ExUnit tests.
https://github.com/obmarg/ex_unit_fixturesA library for defining modular dependencies (fixtures) for ExUnit tests. - obmarg/ex_unit_fixtures - 1176Build software better, together
https://github.com/cart96/unrealGitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 1177Mocking library for Elixir language
https://github.com/jjh42/mockMocking library for Elixir language. Contribute to jjh42/mock development by creating an account on GitHub. - 1178Build software better, together
https://github.com/jquadrin/faustGitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 1179MongoDB adapter for Ecto
https://github.com/michalmuskala/mongodb_ectoMongoDB adapter for Ecto. Contribute to elixir-mongo/mongodb_ecto development by creating an account on GitHub. - 1180An English (Porter2) stemming implementation in Elixir.
https://github.com/fredwu/stemmerAn English (Porter2) stemming implementation in Elixir. - fredwu/stemmer - 1181String similarity metrics for Elixir
https://github.com/lexmag/simetricString similarity metrics for Elixir. Contribute to lexmag/simetric development by creating an account on GitHub. - 1182A PEG parser/transformer with a pleasant Elixir DSL.
https://github.com/jtmoulia/neotomexA PEG parser/transformer with a pleasant Elixir DSL. - jtmoulia/neotomex - 1183An Elixir implementation of gRPC
https://github.com/tony612/grpc-elixirAn Elixir implementation of gRPC. Contribute to elixir-grpc/grpc development by creating an account on GitHub. - 1184Reactive publishing framework, filesystem-based with support for Markdown, nested hierarchies, and instant content rebuilding. Written in Elixir.
https://github.com/alfredbaudisch/pardall_markdownReactive publishing framework, filesystem-based with support for Markdown, nested hierarchies, and instant content rebuilding. Written in Elixir. - alfredbaudisch/pardall_markdown - 1185Xlsx parser for the Elixir language.
https://github.com/kennellroxco/xlsxirXlsx parser for the Elixir language. Contribute to jsonkenl/xlsxir development by creating an account on GitHub. - 1186ActionView::Helpers::NumberHelper for Elixir
https://github.com/danielberkompas/numberActionView::Helpers::NumberHelper for Elixir. Contribute to danielberkompas/number development by creating an account on GitHub. - 1187📏 Dimension based safety in elixir
https://github.com/meadsteve/unit_fun📏 Dimension based safety in elixir. Contribute to meadsteve/unit_fun development by creating an account on GitHub. - 1188Event store using PostgreSQL for persistence
https://github.com/slashdotdash/eventstoreEvent store using PostgreSQL for persistence. Contribute to commanded/eventstore development by creating an account on GitHub. - 1189TDS Driver for Elixir
https://github.com/livehelpnow/tdsTDS Driver for Elixir. Contribute to elixir-ecto/tds development by creating an account on GitHub. - 1190Rihanna is a high performance postgres-backed job queue for Elixir
https://github.com/samphilipd/rihannaRihanna is a high performance postgres-backed job queue for Elixir - samsondav/rihanna - 1191Build software better, together
https://github.com/Vesuvium/medusaGitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 1192Elixir Behaviour Driven Development
https://github.com/antonmi/especElixir Behaviour Driven Development. Contribute to antonmi/espec development by creating an account on GitHub. - 1193Orchestrate end-to-end encryption, cryptographic identities, mutual authentication, and authorization policies between distributed applications – at massive scale.
https://github.com/ockam-network/ockamOrchestrate end-to-end encryption, cryptographic identities, mutual authentication, and authorization policies between distributed applications – at massive scale. - build-trust/ockam - 1194User agent parser library
https://github.com/elixytics/ua_inspectorUser agent parser library. Contribute to elixir-inspector/ua_inspector development by creating an account on GitHub. - 1195Elixir library for working with Money safer, easier, and fun... Is an interpretation of the Fowler's Money pattern in fun.prog.
https://github.com/liuggio/moneyElixir library for working with Money safer, easier, and fun... Is an interpretation of the Fowler's Money pattern in fun.prog. - elixirmoney/money - 1196MongoDB driver for Elixir
https://github.com/ericmj/mongodbMongoDB driver for Elixir. Contribute to elixir-mongo/mongodb development by creating an account on GitHub. - 1197FakeServer integrates with ExUnit to make external APIs testing simpler
https://github.com/bernardolins/fake_serverFakeServer integrates with ExUnit to make external APIs testing simpler - bernardolins/fake_server - 1198MongoDB driver for Elixir
https://github.com/zookzook/elixir-mongodb-driverMongoDB driver for Elixir. Contribute to zookzook/elixir-mongodb-driver development by creating an account on GitHub. - 1199The BEAM Community
http://beamcommunity.github.io/Our goal is to host relevant projects in the Erlang and Elixir communities, making it easy for those projects to participate in the Google Summer of Code. - 1200random_user_api
https://hex.pm/packages/random_user_apiIt's a simple client of randomuser.me to get random user. - 1201Cloud Monitoring as a Service | Datadog
https://www.datadoghq.com/.See metrics from all of your apps, tools & services in one place with Datadog's cloud monitoring as a service solution. Try it for free. - 1202Livro de Elixir - Casa do Código
https://www.casadocodigo.com.br/products/livro-elixirNeste livro, Tiago Davi apresenta a linguagem de programação Elixir, que, por ser uma linguagem imutável e utilizar o paradigma funcional, nos permite pensar em termos de funções e transformação de dados. Você poderá executar código em pequenos processos, cada um com seu próprio estado, de modo que a construção de sistemas distribuídos e concorrentes seja feita de forma natural, transparente e fácil. - 1203Free PO editor
https://pofile.net/free-po-editorA powerful and easy-to-use PO file editor that helps translators work faster and better, at no cost. - 1204Engineering Elixir Applications
https://pragprog.com/titles/beamops/engineering-elixir-applications/Develop, deploy, and debug BEAM applications using BEAMOps: a new paradigm that focuses on scalability, fault tolerance, and owning each software delivery step. - 1205Build software better, together
https://github.com/attm2x/m2x-erlang.GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 1206Learn all about asynchronous elixir
https://github.com/Arp-G/async-elixirLearn all about asynchronous elixir. Contribute to Arp-G/async-elixir development by creating an account on GitHub. - 1207Build software better, together
https://github.com/JonGretar/HexokuGitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 1208The Phoenix LiveView Cookbook
https://www.liveviewcookbook.com/From beginner to expert: Elevate your Phoenix LiveView skills with the ebook containing tried and tested recipes for solving common problems. - 1209Elixir Merge
https://elixirmerge.comDaily Elixir newsletter - 1210ElixirWeekly - Elixir Community Newsletter, one email every Thursday.
https://elixirweekly.netWeekly Elixir Community Newsletter, covering community news you easily miss, shared on ElixirStatus and the web, in one email every Thursday. - 1211Elixir Mailgun Client
https://github.com/chrismccord/mailgunElixir Mailgun Client. Contribute to chrismccord/mailgun development by creating an account on GitHub. - 1212Publisher Subscriber utility for elixir
https://github.com/sonic182/pub_subxPublisher Subscriber utility for elixir. Contribute to sonic182/pub_subx development by creating an account on GitHub. - 1213Build software better, together
https://github.com/mtwtkman/exlingrGitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 1214The Elixir Fountain
https://soundcloud.com/elixirfountainYour weekly podcast for news & interviews from around the @Elixirlang Community hosted by @johnny_rugger RSS Feed: http://feed.elixirfountain.com - 1215Thinking Elixir Podcast
https://podcast.thinkingelixir.comNews and interviews for the Elixir community - 1216iOS and Android push notifications for Elixir
https://github.com/codedge-llc/pigeoniOS and Android push notifications for Elixir. Contribute to codedge-llc/pigeon development by creating an account on GitHub. - 1217An Elixir notifier to the Airbrake/Errbit. System-wide error reporting enriched with the information from Plug and Phoenix channels.
https://github.com/romul/airbrake-elixirAn Elixir notifier to the Airbrake/Errbit. System-wide error reporting enriched with the information from Plug and Phoenix channels. - romul/airbrake-elixir - 1218Elixir Outlaws
https://elixiroutlaws.comThe hallway track of the Elixir community - 1219ElixirTalk
https://soundcloud.com/elixirtalkDesmond Bowe and Chris Bell present a titillating discussion about Elixir application design and the state of the ecosystem. Ask us a question at https://github.com/elixirtalk/elixirtalk and follow u - 1220Phoenix Inside Out Series
https://shankardevy.com/phoenix-book/Rebuild a mini-Phoenix framework and learn to use Phoenix framework with confidence - 1221Études for Elixir
https://www.oreilly.com/library/view/etudes-for-elixir/9781491917640/This book includes descriptions of programs that you can write in Elixir. The programs will usually be short, and each one has been designed to provide practice material for a … - Selection from Études for Elixir [Book] - 1222Elixir - The Inquisitive Developer
https://inquisitivedeveloper.com/tag/lwm-elixir/A series where I learn Elixir and you can learn along with me. - 1223Elixir wrapper for xmerl_*
https://github.com/pwoolcoc/exmerlElixir wrapper for xmerl_*. Contribute to pwoolcoc/exmerl development by creating an account on GitHub. - 1224[NOT MAINTAINING] Qiniu sdk for Elixir
https://github.com/tony612/qiniu[NOT MAINTAINING] Qiniu sdk for Elixir. Contribute to tony612/qiniu development by creating an account on GitHub. - 1225Awesome Elixir | LibHunt
https://elixir.libhunt.comYour go-to Elixir Toolbox. A curated list of awesome Elixir and Erlang packages and resources.. 1604 projects organized into 91 categories. - 1226knewter/everyoneapi
https://github.com/knewter/everyoneapiContribute to knewter/everyoneapi development by creating an account on GitHub. - 1227maarek/ParsEx
https://github.com/maarek/ParsExContribute to maarek/ParsEx development by creating an account on GitHub. - 1228fluentd client for Elixir
https://github.com/trustatom-oss/elixir-fluent-clientfluentd client for Elixir. Contribute to trustatom-oss/elixir-fluent-client development by creating an account on GitHub. - 1229Simple wrapper for Forecast.IO API
https://github.com/r-icarus/forecast_ioSimple wrapper for Forecast.IO API. Contribute to r-icarus/forecast_io development by creating an account on GitHub. - 1230Today I Learned
https://til.hashrocket.com/elixirTIL is an open-source project by Hashrocket that exists to catalogue the sharing & accumulation of knowledge as it happens day-to-day. - 1231Erlang and Elixir for Imperative Programmers
https://leanpub.com/erlangandelixirforimperativeprogrammersIntroduction to Erlang and Elixir for developers with knowledge of Java, C++, C# and other imperative languages - 1232Elixir library for interacting with Google's Cloud Datastore
https://github.com/peburrows/diplomatElixir library for interacting with Google's Cloud Datastore - peburrows/diplomat - 1233Elixir in Action
https://www.manning.com/books/elixir-in-actionElixir in Action</i> teaches you to apply the new Elixir programming language to practical problems associated with scalability, concurrency, fault tolerance, and high availability.</p> - 1234Coinbase API V1 Client for Elixir
https://github.com/gregpardo/coinbase-elixirCoinbase API V1 Client for Elixir. Contribute to gregpardo/coinbase-elixir development by creating an account on GitHub. - 1235An Elixir library to interact with Chargebee
https://github.com/WTTJ/chargebeexAn Elixir library to interact with Chargebee. Contribute to WTTJ/chargebeex development by creating an account on GitHub. - 1236Find Brazilian addresses by postal code, directly from Correios API. No HTML parsers.
https://github.com/prodis/correios-cep-elixirFind Brazilian addresses by postal code, directly from Correios API. No HTML parsers. - prodis/correios-cep-elixir - 1237Opbeat client for Elixir
https://github.com/teodor-pripoae/opbeatOpbeat client for Elixir. Contribute to teodor-pripoae/opbeat development by creating an account on GitHub. - 1238Active Merchant is a simple payment abstraction library extracted from Shopify. The aim of the project is to feel natural to Ruby users and to abstract as many parts as possible away from the user to offer a consistent interface across all supported gateways.
https://github.com/activemerchant/active_merchantActive Merchant is a simple payment abstraction library extracted from Shopify. The aim of the project is to feel natural to Ruby users and to abstract as many parts as possible away from the user ... - 1239Elixir in Action, Second Edition
https://www.manning.com/books/elixir-in-action-second-edition<iframe type="text/html" src="https://www.youtube.com/embed/n1me0PxQ8NA" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe> </div> Revised and updated for Elixir 1.7, Elixir in Action, Second Edition</i> teaches you how to apply Elixir to practical problems associated with scalability, fault tolerance, and high availability. Along the way, you'll develop an appreciation for, and considerable skill in, a functional and concurrent style of programming. </p> - 1240Telegram Bot API Wrapper written in Elixir
https://github.com/zhyu/nadiaTelegram Bot API Wrapper written in Elixir. Contribute to zhyu/nadia development by creating an account on GitHub. - 1241Elixir client for the Airbrake service.
https://github.com/fazibear/airbrakexElixir client for the Airbrake service. Contribute to fazibear/airbrakex development by creating an account on GitHub. - 1242A complete payment library for Elixir and Phoenix Framework
https://github.com/aviabird/gringottsA complete payment library for Elixir and Phoenix Framework - aviabird/gringotts - 1243Lastfm API wrapper for Elixir
https://github.com/jrichocean/ElixirfmLastfm API wrapper for Elixir. Contribute to jrichocean/Elixirfm development by creating an account on GitHub. - 1244Learn Elixir - Best Elixir Tutorials | Hackr.io
https://hackr.io/tutorials/learn-elixirLearning Elixir? Check out these best online Elixir courses and tutorials recommended by the programming community. Pick the tutorial as per your learning style: video tutorials or a book. Free course or paid. Tutorials for beginners or advanced learners. Check Elixir community's reviews & comments. - 1245Simple implementation of the Cleverbot API in Elixir
https://github.com/BlakeWilliams/Elixir-CleverbotSimple implementation of the Cleverbot API in Elixir - BlakeWilliams/Elixir-Cleverbot - 1246Meet Elixir
https://www.pluralsight.com/courses/meet-elixirWrite concurrent programs with the Elixir language. - 1247Elixir in Action, Third Edition
https://www.manning.com/books/elixir-in-action-third-editionFully updated to Elixir 1.15, this authoritative bestseller reveals how Elixir tackles problems of scalability, fault tolerance, and high availability.</b> Thousands of developers have learned to build applications in Elixir by using Saša Jurić’s Elixir in Action</i>. You’ll skip the programming basics or 101 introductions; this book builds on your existing knowledge to get you quickly writing real Elixir code. Along the way, you'll develop an appreciation for, and considerable skill in, functional and concurrent programming. Inside Elixir in Action, Third Edition</i> you’ll find: Updates for Elixir 1.15</li> Elixir modules, functions, and type system</li> Functional and concurrent programming</li> Introduction to distributed system design</li> Creating deployable releases</li> </ul> Fully updated to Elixir 1.15, this book contains new coverage of working with application configuration and the latest OTP releases. It teaches you the underlying principles and functional concepts of Elixir, and how each piece fits into the bigger picture of building production-ready systems with Elixir, Erlang, and the OTP framework. - 1248knewter/dpd_client
https://github.com/knewter/dpd_clientContribute to knewter/dpd_client development by creating an account on GitHub. - 1249Elixir library for the (undocumented) Rap Genius (and also Rock, Tech, Pop, Country, etc) API
https://github.com/jeffweiss/exgeniusElixir library for the (undocumented) Rap Genius (and also Rock, Tech, Pop, Country, etc) API - jeffweiss/exgenius - 1250jeregrine/mixpanel_data_client
https://github.com/jeregrine/mixpanel_data_clientContribute to jeregrine/mixpanel_data_client development by creating an account on GitHub. - 1251Twitter client library for elixir.
https://github.com/parroty/extwitterTwitter client library for elixir. . Contribute to parroty/extwitter development by creating an account on GitHub. - 1252(WIP) Elixir wrapper for the Digital Ocean API v2.
https://github.com/lukeed/elixir-digitalocean(WIP) Elixir wrapper for the Digital Ocean API v2. - lukeed/elixir-digitalocean - 1253Elixir library for creating short URLs using Google's URL Shortener API.
https://github.com/jonahoffline/link_shrinkexElixir library for creating short URLs using Google's URL Shortener API. - jonahoffline/link_shrinkex - 1254CLI and Elixir API Client for the Marvel API
https://github.com/bryanjos/marvelCLI and Elixir API Client for the Marvel API . Contribute to bryanjos/marvel development by creating an account on GitHub. - 1255elixir interface for fetching SEC filings from EDGAR
https://github.com/rozap/edgarexelixir interface for fetching SEC filings from EDGAR - rozap/edgarex - 1256currently is a tool to display cards currently assigns on Trello.
https://github.com/chatgris/currentlycurrently is a tool to display cards currently assigns on Trello. - chatgris/currently - 1257hisea/dockerex
https://github.com/hisea/dockerexContribute to hisea/dockerex development by creating an account on GitHub. - 1258The Little Elixir & OTP Guidebook
https://www.manning.com/books/the-little-elixir-and-otp-guidebookThe Little Elixir & OTP Guidebook</i> gets you started programming applications with Elixir and OTP. You begin with a quick overview of the Elixir language syntax, along with just enough functional programming to use it effectively. Then, you'll dive straight into OTP and learn how it helps you build scalable, fault-tolerant and distributed applications through several fun examples. </p> - 1259Just a simple myanmar exchange rate checker and caculator based on Central Bank of Myanmar API with elixir
https://github.com/Arkar-Aung/mmExchangeRateJust a simple myanmar exchange rate checker and caculator based on Central Bank of Myanmar API with elixir - Arkar-Aung/mmExchangeRate - 1260Elixir Twitter Client
https://github.com/radzserg/rstwitterElixir Twitter Client. Contribute to radzserg/rstwitter development by creating an account on GitHub. - 1261Elixir client for the Docker Remote API
https://github.com/hexedpackets/docker-elixirElixir client for the Docker Remote API. Contribute to hexedpackets/docker-elixir development by creating an account on GitHub. - 1262A payment processing library for Elixir
https://github.com/joshnuss/commerce_billingA payment processing library for Elixir. Contribute to joshnuss/commerce_billing development by creating an account on GitHub. - 1263An Elixir library for generating and parsing NACHA files for US ACH & EFT bank transfers
https://github.com/RiverFinancial/nachaAn Elixir library for generating and parsing NACHA files for US ACH & EFT bank transfers - RiverFinancial/nacha - 1264Feedly client for Elixir
https://github.com/essenciary/feedlexFeedly client for Elixir. Contribute to essenciary/feedlex development by creating an account on GitHub. - 1265Pay is an Elixir Lib to deal with Paypal and other payment solutions.
https://github.com/era/payPay is an Elixir Lib to deal with Paypal and other payment solutions. - era/pay - 1266Keen.io API Client for Elixir
https://github.com/bryanjos/keenexKeen.io API Client for Elixir. Contribute to bryanjos/keenex development by creating an account on GitHub. - 1267essenciary/pocketex
https://github.com/essenciary/pocketexContribute to essenciary/pocketex development by creating an account on GitHub. - 1268:camera: Instagram API client for the Elixir language (elixir-lang)
https://github.com/zensavona/elixtagram:camera: Instagram API client for the Elixir language (elixir-lang) - Zensavona/elixtagram - 1269The Elixir library that is used to communicate with the IPFS REST endpoint.
https://github.com/zabirauf/elixir-ipfs-apiThe Elixir library that is used to communicate with the IPFS REST endpoint. - zabirauf/elixir-ipfs-api - 1270AskimetEx is a lib for use TypePad's AntiSpam services or Askimet endpoints in elixir projects.
https://github.com/mijailr/askimet_exAskimetEx is a lib for use TypePad's AntiSpam services or Askimet endpoints in elixir projects. - mijailr/askimet_ex - 1271Assembla API client for Elixir
https://github.com/Assembla/ex_assembla_apiAssembla API client for Elixir. Contribute to assembla/ex_assembla_api development by creating an account on GitHub. - 1272Omise Client Library for Elixir
https://github.com/omise/omise-elixirOmise Client Library for Elixir. Contribute to omise/omise-elixir development by creating an account on GitHub. - 1273Balanced Api Client for Elixir
https://github.com/bryanjos/balanced-elixirBalanced Api Client for Elixir. Contribute to bryanjos/balanced-elixir development by creating an account on GitHub. - 1274A simple Elixir interface to Bing's translation API.
https://github.com/ikeikeikeike/bing_translatorA simple Elixir interface to Bing's translation API. - GitHub - ikeikeikeike/bing_translator: A simple Elixir interface to Bing's translation API. - 1275Google Cloud Messaging client library for elixir
https://github.com/dukex/gcmexGoogle Cloud Messaging client library for elixir. Contribute to dukex/gcmex development by creating an account on GitHub. - 1276A semver library for Elixir
https://github.com/lee-dohm/semverA semver library for Elixir. Contribute to lee-dohm/semver development by creating an account on GitHub. - 1277Twilio API client for Elixir
https://github.com/danielberkompas/ex_twilioTwilio API client for Elixir. Contribute to danielberkompas/ex_twilio development by creating an account on GitHub. - 1278blendmedia/mexpanel
https://github.com/blendmedia/mexpanelContribute to blendmedia/mexpanel development by creating an account on GitHub. - 1279Evernote API client for Elixir
https://github.com/jwarlander/everexEvernote API client for Elixir. Contribute to jwarlander/everex development by creating an account on GitHub. - 1280An Elixir module for generating Gravatar urls.
https://github.com/scrogson/exgravatarAn Elixir module for generating Gravatar urls. Contribute to scrogson/exgravatar development by creating an account on GitHub. - 1281Facebook Graph API Wrapper written in Elixir
https://github.com/mweibel/facebook.exFacebook Graph API Wrapper written in Elixir. Contribute to mweibel/facebook.ex development by creating an account on GitHub. - 1282:money_with_wings: PayPal REST API client for the Elixir language (elixir-lang)
https://github.com/zensavona/paypal:money_with_wings: PayPal REST API client for the Elixir language (elixir-lang) - GitHub - Zensavona/PayPal: :money_with_wings: PayPal REST API client for the Elixir language (elixir-lang) - 1283A walk through the Elixir language in 30 exercises.
https://github.com/seven1m/30-days-of-elixirA walk through the Elixir language in 30 exercises. - seven1m/30-days-of-elixir - 1284Elixir library for fetching Google Spreadsheet data in CSV format
https://github.com/GrandCru/GoogleSheetsElixir library for fetching Google Spreadsheet data in CSV format - GrandCru/GoogleSheets - 1285Elixir client for Tagplay API
https://github.com/tagplay/elixir-tagplayElixir client for Tagplay API. Contribute to tagplay/elixir-tagplay development by creating an account on GitHub. - 1286Elixir library to access the Pusher REST API.
https://github.com/edgurgel/pusherElixir library to access the Pusher REST API. Contribute to edgurgel/pusher development by creating an account on GitHub. - 1287BitMEX client library for Elixir.
https://github.com/nobrick/bitmexBitMEX client library for Elixir. Contribute to nobrick/bitmex development by creating an account on GitHub. - 1288securingsincity/ex_codeship
https://github.com/securingsincity/ex_codeshipContribute to securingsincity/ex_codeship development by creating an account on GitHub. - 1289An elixir wrapper for Asana
https://github.com/trenpixster/asanaficatorAn elixir wrapper for Asana. Contribute to trenpixster/asanaficator development by creating an account on GitHub. - 1290Fast and reliable Elixir client for StatsD-compatible servers
https://github.com/lexmag/statixFast and reliable Elixir client for StatsD-compatible servers - lexmag/statix - 1291Dublin Bus API
https://github.com/carlo-colombo/dublin-bus-apiDublin Bus API. Contribute to carlo-colombo/dublin-bus-api development by creating an account on GitHub. - 1292Google Play API in Elixir :computer:
https://github.com/sheharyarn/explayGoogle Play API in Elixir :computer:. Contribute to sheharyarn/explay development by creating an account on GitHub. - 1293Facebook API
https://github.com/oivoodoo/exfacebookFacebook API. Contribute to oivoodoo/exfacebook development by creating an account on GitHub. - 1294Exception tracking from Elixir to Airbrake
https://github.com/adjust/airbaxException tracking from Elixir to Airbrake. Contribute to adjust/airbax development by creating an account on GitHub. - 1295Elixir syntax highlighting for Notepad++
https://github.com/Hades32/elixir-udl-nppElixir syntax highlighting for Notepad++. Contribute to Hades32/elixir-udl-npp development by creating an account on GitHub. - 1296benjamintanweihao/elixir-cheatsheets
https://github.com/benjamintanweihao/elixir-cheatsheets/Contribute to benjamintanweihao/elixir-cheatsheets development by creating an account on GitHub. - 1297All about erlang programming language [powerd by community]
https://github.com/0xAX/erlang-bookmarksAll about erlang programming language [powerd by community] - 0xAX/erlang-bookmarks - 1298Little bit of Elixir in every new tab
https://github.com/efexen/elixir-tabLittle bit of Elixir in every new tab. Contribute to efexen/elixir-tab development by creating an account on GitHub. - 1299Simple Elixir package for the govtrack.us API
https://github.com/walterbm/govtrack-elixirSimple Elixir package for the govtrack.us API. Contribute to walterbm/govtrack-elixir development by creating an account on GitHub. - 1300Dropbox Core API client for Elixir
https://github.com/ammmir/elixir-dropboxDropbox Core API client for Elixir. Contribute to ammmir/elixir-dropbox development by creating an account on GitHub. - 1301Elixir library to interact with Sendgrid's API
https://github.com/bradleyd/exgridElixir library to interact with Sendgrid's API. Contribute to bradleyd/exgrid development by creating an account on GitHub. - 1302Elixir Programming Language Forum
https://elixirforum.com/The Elixir Forum - for Elixir programming language enthusiasts! - 1303Elixir's coolest deprecation logger
https://github.com/whitfin/deppieElixir's coolest deprecation logger. Contribute to whitfin/deppie development by creating an account on GitHub. - 1304Elixir Language Definition Extension for Panic Nova
https://github.com/stollcri/elixir.novaextensionElixir Language Definition Extension for Panic Nova - stollcri/elixir.novaextension - 1305Most simple Elixir wrapper for xmerl xpath
https://github.com/expelledboy/exmlMost simple Elixir wrapper for xmerl xpath. Contribute to expelledboy/exml development by creating an account on GitHub. - 1306Zanox API
https://github.com/rafaelss/zanoxZanox API. Contribute to rafaelss/zanox development by creating an account on GitHub. - 1307Simple reporting App reviews library
https://github.com/KazuCocoa/simple_app_reporter_exSimple reporting App reviews library. Contribute to KazuCocoa/simple_app_reporter_ex development by creating an account on GitHub. - 1308Elixir library for the Force.com / Salesforce / SFDC REST API
https://github.com/jeffweiss/forcexElixir library for the Force.com / Salesforce / SFDC REST API - jeffweiss/forcex - 1309Vim plugin to generate elixir method and a test
https://github.com/jadercorrea/elixir_generator.vimVim plugin to generate elixir method and a test. Contribute to jadercorrea/elixir_generator.vim development by creating an account on GitHub. - 1310:dress: Dress up your stdout
https://github.com/veelenga/dress:dress: Dress up your stdout. Contribute to veelenga/dress development by creating an account on GitHub. - 1311Simple wrapper for the Vultr API in Elixir
https://github.com/avitex/elixir-vultrSimple wrapper for the Vultr API in Elixir. Contribute to avitex/elixir-vultr development by creating an account on GitHub. - 1312A data validation library for Elixir based on Prismatic Scheme
https://github.com/prio/shapeA data validation library for Elixir based on Prismatic Scheme - prio/shape - 1313Realtime currency conversion for Elixir
https://github.com/paulodiniz/xeRealtime currency conversion for Elixir. Contribute to paulodiniz/xe development by creating an account on GitHub. - 1314A curated list of awesome Elixir and Command Query Responsibility Segregation (CQRS) resources.
https://github.com/slashdotdash/awesome-elixir-cqrsA curated list of awesome Elixir and Command Query Responsibility Segregation (CQRS) resources. - slashdotdash/awesome-elixir-cqrs - 1315An Elixir client for the Mixpanel HTTP API
https://github.com/michihuber/mixpanel_exAn Elixir client for the Mixpanel HTTP API. Contribute to michihuber/mixpanel_ex development by creating an account on GitHub. - 1316Google Pub/Sub client for Elixir
https://github.com/peburrows/kaneGoogle Pub/Sub client for Elixir. Contribute to peburrows/kane development by creating an account on GitHub. - 1317Create and send composable emails with Elixir and SendGrid.
https://github.com/alexgaribay/sendgrid_elixirCreate and send composable emails with Elixir and SendGrid. - alexgaribay/sendgrid_elixir - 1318A Mix Wrapper for Neovim
https://github.com/brendalf/mix.nvimA Mix Wrapper for Neovim. Contribute to brendalf/mix.nvim development by creating an account on GitHub. - 1319Vim integration for the Elixir formatter.
https://github.com/mhinz/vim-mix-formatVim integration for the Elixir formatter. Contribute to mhinz/vim-mix-format development by creating an account on GitHub. - 1320ParabaikElixirConverter is just a Elixir version of Parabaik converter
https://github.com/Arkar-Aung/ParabaikElixirConverterParabaikElixirConverter is just a Elixir version of Parabaik converter - Arkar-Aung/ParabaikElixirConverter - 1321Run Elixir tests inside VIM
https://github.com/moofish32/vim-ex_testRun Elixir tests inside VIM. Contribute to moofish32/vim-ex_test development by creating an account on GitHub. - 1322danmcclain/voorhees
https://github.com/danmcclain/voorheesContribute to danmcclain/voorhees development by creating an account on GitHub. - 1323UK postcode parsing and validation for Elixir
https://github.com/KushalP/uk_postcodeUK postcode parsing and validation for Elixir. Contribute to KushalP/uk_postcode development by creating an account on GitHub. - 1324write plugins for Neovim using Elixir
https://github.com/dm1try/nvimwrite plugins for Neovim using Elixir. Contribute to dm1try/nvim development by creating an account on GitHub. - 1325Cashier is an Elixir library that aims to be an easy to use payment gateway, whilst offering the fault tolerance and scalability benefits of being built on top of Erlang/OTP
https://github.com/swelham/cashierCashier is an Elixir library that aims to be an easy to use payment gateway, whilst offering the fault tolerance and scalability benefits of being built on top of Erlang/OTP - swelham/cashier - 1326Facility, Prosperity and Maintainability.
https://github.com/mbasso/mandrakeFacility, Prosperity and Maintainability. Contribute to mbasso/mandrake development by creating an account on GitHub. - 1327Elixir iex REPL in an Atom tab.
https://github.com/indiejames/atom-iexElixir iex REPL in an Atom tab. Contribute to indiejames/atom-iex development by creating an account on GitHub. - 1328[Deprecated] An Elixir client library for the Bandwidth Voice and Messaging APIs
https://github.com/bandwidthcom/elixir-bandwidth[Deprecated] An Elixir client library for the Bandwidth Voice and Messaging APIs - Bandwidth/elixir-bandwidth - 1329Elixir client for PagerDuty
https://github.com/ride/pagexdutyElixir client for PagerDuty. Contribute to epsanchezma/pagexduty development by creating an account on GitHub. - 1330Elixir plugin for SublimeText 3 providing code completion and linting.
https://github.com/vishnevskiy/ElixirSublimeElixir plugin for SublimeText 3 providing code completion and linting. - vishnevskiy/ElixirSublime - 1331Unsplash API client for Elixir
https://github.com/waynehoover/unsplash-elixirUnsplash API client for Elixir. Contribute to waynehoover/unsplash-elixir development by creating an account on GitHub. - 1332A module for validating http params and queries
https://github.com/zbarnes757/jeauxA module for validating http params and queries. Contribute to zbarnes757/jeaux development by creating an account on GitHub. - 1333An IBAN account numbers and BIC validation tool for Elixir.
https://github.com/railsmechanic/banksterAn IBAN account numbers and BIC validation tool for Elixir. - railsmechanic/bankster - 1334Elixir + Neovim = :couple:
https://github.com/dm1try/ilexirElixir + Neovim = :couple:. Contribute to dm1try/ilexir development by creating an account on GitHub. - 1335phoenixframework-Brazil/phoenix-snippets
https://github.com/phoenixframework-Brazil/phoenix-snippetsContribute to phoenixframework-Brazil/phoenix-snippets development by creating an account on GitHub. - 1336Introducing Elixir
http://shop.oreilly.com/product/0636920030584.doElixir is an excellent language if you want to learn about functional programming, and with this hands-on introduction, you’ll discover just how powerful and fun Elixir can be. This language … - Selection from Introducing Elixir [Book] - 1337Elixir wrapper for UrbanAirship API.
https://github.com/oscar-lopez/exurbanElixir wrapper for UrbanAirship API. Contribute to oscar-lopez/exurban development by creating an account on GitHub. - 1338Converts an Elixir map to an XML document.
https://github.com/gunnar2k/elixir-map-to-xmlConverts an Elixir map to an XML document. Contribute to gunnar2k/elixir-map-to-xml development by creating an account on GitHub. - 1339PDF, MOBI, EPUB documents for Elixir's Getting Started tutorial.
https://github.com/potatogopher/elixir-getting-startedPDF, MOBI, EPUB documents for Elixir's Getting Started tutorial. - potatogopher/elixir-getting-started - 1340A Elixir library for translating between hiragana, katakana, romaji and sound.
https://github.com/ikeikeikeike/exromajiA Elixir library for translating between hiragana, katakana, romaji and sound. - ikeikeikeike/exromaji - 1341The Little Schemer in Elixir.
https://github.com/jwhiteman/a-little-elixir-goes-a-long-wayThe Little Schemer in Elixir. Contribute to jwhiteman/a-little-elixir-goes-a-long-way development by creating an account on GitHub. - 1342An Atom package for Elixir
https://github.com/msaraiva/atom-elixirAn Atom package for Elixir. Contribute to msaraiva/atom-elixir development by creating an account on GitHub. - 1343Elixir Integration Into Vim
https://github.com/slashmili/alchemist.vimElixir Integration Into Vim. Contribute to slashmili/alchemist.vim development by creating an account on GitHub. - 1344Simple Elixir macros for linear retry, exponential backoff and wait with composable delays
https://github.com/safwank/ElixirRetrySimple Elixir macros for linear retry, exponential backoff and wait with composable delays - safwank/ElixirRetry - 1345An Amazon Product Advertising API client for Elixir
https://github.com/zachgarwood/elixir-amazon-product-advertising-clientAn Amazon Product Advertising API client for Elixir - Grantimus9/elixir-amazon-product-advertising-client - 1346Elixir library to convert GIFs and videos to silent videos.
https://github.com/talklittle/silent_videoElixir library to convert GIFs and videos to silent videos. - talklittle/silent_video - 1347Elixir language support and debugger for VS Code, powered by ElixirLS.
https://github.com/JakeBecker/vscode-elixir-lsElixir language support and debugger for VS Code, powered by ElixirLS. - JakeBecker/vscode-elixir-ls - 1348Internationalization and localization support for Elixir.
https://github.com/elixir-lang/gettextInternationalization and localization support for Elixir. - elixir-gettext/gettext - 1349Utility to download Elixir Sips screencast videos written in Elixir (subscription to Elixir Sips required)
https://github.com/DavsX/SipsDownloaderUtility to download Elixir Sips screencast videos written in Elixir (subscription to Elixir Sips required) - kovdavid/SipsDownloader - 1350Phoenix in Action
https://manning.com/books/phoenix-in-actionPhoenix is a modern web framework built for the Elixir programming language. Elegant, fault-tolerant, and performant, Phoenix is as easy to use as Rails and as rock-solid as Elixir's Erlang-based foundation. Phoenix in Action</i> builds on your existing web dev skills, teaching you the unique benefits of Phoenix along with just enough Elixir to get the job done.</p> - 1351XML Sitemap generator for Plug / Phoenix Framework
https://github.com/nerdslabs/plugmapXML Sitemap generator for Plug / Phoenix Framework - nerdslabs/plugmap - 1352JIRA client library for Elixir
https://github.com/mattweldon/exjiraJIRA client library for Elixir. Contribute to mattweldon/exjira development by creating an account on GitHub. - 1353Redtube API Wrapper written in Elixir
https://github.com/kkirsche/Redtube_ElixirRedtube API Wrapper written in Elixir. Contribute to kkirsche/Redtube_Elixir development by creating an account on GitHub. - 1354Slack real time messaging and web API client in Elixir
https://github.com/BlakeWilliams/Elixir-SlackSlack real time messaging and web API client in Elixir - BlakeWilliams/Elixir-Slack - 1355An Elixir wrapper which communicates with the Telegram-CLI.
https://github.com/ccsteam/ex-telegram-clientAn Elixir wrapper which communicates with the Telegram-CLI. - ccsteam/ex-telegram-client - 1356SparkPost client library for Elixir https://developers.sparkpost.com
https://github.com/SparkPost/elixir-sparkpostSparkPost client library for Elixir https://developers.sparkpost.com - SparkPost/elixir-sparkpost - 1357🧾 FORM: Business X-Forms
https://github.com/synrc/form🧾 FORM: Business X-Forms. Contribute to synrc/form development by creating an account on GitHub. - 1358Erlware Commons is an Erlware project focused on all aspects of reusable Erlang components.
https://github.com/erlware/erlware_commonsErlware Commons is an Erlware project focused on all aspects of reusable Erlang components. - erlware/erlware_commons - 1359Encode and decode elixir terms to XML-RPC parameters
https://github.com/ewildgoose/elixir-xml_rpcEncode and decode elixir terms to XML-RPC parameters - ewildgoose/elixir-xml_rpc - 1360An Elixir Client for the Honeywell Developer API
https://github.com/jeffutter/honeywell-elixirAn Elixir Client for the Honeywell Developer API. Contribute to jeffutter/honeywell-elixir development by creating an account on GitHub. - 1361XML parser for Elixir
https://github.com/nhu313/QuinnXML parser for Elixir. Contribute to nhu313/Quinn development by creating an account on GitHub. - 1362VK API wrapper for Elixir
https://github.com/ayrat555/balalaika_bearVK API wrapper for Elixir . Contribute to BalalaikaIndustries/balalaika_bear development by creating an account on GitHub. - 1363Erlang shell tools
https://github.com/proger/erlshErlang shell tools. Contribute to proger/erlsh development by creating an account on GitHub. - 1364Generate TwiML with Elixir
https://github.com/danielberkompas/ex_twimlGenerate TwiML with Elixir. Contribute to danielberkompas/ex_twiml development by creating an account on GitHub. - 1365A refheap API client library in Elixir.
https://github.com/Raynes/reapA refheap API client library in Elixir. Contribute to Raynes/reap development by creating an account on GitHub. - 1366a Mandrill wrapper for Elixir
https://github.com/slogsdon/mandrill-elixira Mandrill wrapper for Elixir. Contribute to slogsdon/mandrill-elixir development by creating an account on GitHub. - 1367A basic Elixir wrapper for version 3 of the MailChimp API
https://github.com/duartejc/mailchimpA basic Elixir wrapper for version 3 of the MailChimp API - duartejc/mailchimp - 1368Elixir state machines for Twilio calls
https://github.com/danielberkompas/telephonistElixir state machines for Twilio calls. Contribute to danielberkompas/telephonist development by creating an account on GitHub. - 1369An headline and link puller for Reddit and its various subreddits
https://github.com/MonkeyIsNull/reddhlAn headline and link puller for Reddit and its various subreddits - MonkeyIsNull/reddhl - 1370Elixir Tooling Integration Into Emacs
https://github.com/tonini/alchemist.elElixir Tooling Integration Into Emacs. Contribute to tonini/alchemist.el development by creating an account on GitHub. - 1371Fast YAML native library for Erlang / Elixir
https://github.com/processone/fast_yamlFast YAML native library for Erlang / Elixir. Contribute to processone/fast_yaml development by creating an account on GitHub. - 1372Editor/IDE independent background server to inform about Elixir mix projects
https://github.com/tonini/alchemist-serverEditor/IDE independent background server to inform about Elixir mix projects - tonini/alchemist-server - 1373Yaml parser for Elixir based on native Erlang implementation
https://github.com/KamilLelonek/yaml-elixirYaml parser for Elixir based on native Erlang implementation - KamilLelonek/yaml-elixir - 1374:droplet: Publish/Subscribe utility module
https://github.com/simonewebdesign/elixir_pubsub:droplet: Publish/Subscribe utility module. Contribute to simonewebdesign/elixir_pubsub development by creating an account on GitHub. - 1375Fast, stream based XML Sitemap generator in Elixir
https://github.com/tomtaylor/sitemapperFast, stream based XML Sitemap generator in Elixir - breakroom/sitemapper - 1376Qiita API v2 Interface for Elixir
https://github.com/ma2gedev/qiita_exQiita API v2 Interface for Elixir. Contribute to ma2gedev/qiita_ex development by creating an account on GitHub. - 1377Elixir core library for connecting to bitpay.com
https://github.com/bitpay/elixir-clientElixir core library for connecting to bitpay.com. Contribute to bitpay/elixir-client development by creating an account on GitHub. - 1378Fast Expat based Erlang XML parsing library
https://github.com/processone/fast_xmlFast Expat based Erlang XML parsing library. Contribute to processone/fast_xml development by creating an account on GitHub. - 1379The asynchronous version of Elixir's "with", resolving the dependency graph and executing the clauses in the most performant way possible!
https://github.com/fertapric/async_withThe asynchronous version of Elixir's "with", resolving the dependency graph and executing the clauses in the most performant way possible! - fertapric/async_with - 1380A TextMate and Sublime Text Bundle for the Elixir programming language
https://github.com/elixir-lang/elixir-tmbundleA TextMate and Sublime Text Bundle for the Elixir programming language - elixir-editors/elixir-tmbundle - 1381Wrapper of the Erlang :global module
https://github.com/mgwidmann/globalWrapper of the Erlang :global module. Contribute to mgwidmann/global development by creating an account on GitHub. - 1382An Elixir client for the parse.com REST API
https://github.com/elixircnx/parse_elixir_clientAn Elixir client for the parse.com REST API. Contribute to elixircnx/parse_elixir_client development by creating an account on GitHub. - 1383An Erlang/Elixir client library for the Trak.io REST API.
https://github.com/novabyte/pathwayAn Erlang/Elixir client library for the Trak.io REST API. - novabyte/pathway - 1384Converts XML String to Elixir Map data structure with string keys
https://github.com/homanchou/elixir-xml-to-mapConverts XML String to Elixir Map data structure with string keys - homanchou/elixir-xml-to-map - 1385Fast, extensible and easy to use data structure validation for elixir with nested structures support.
https://github.com/bydooweedoo/isFast, extensible and easy to use data structure validation for elixir with nested structures support. - bydooweedoo/is - 1386Validation for National Registration Identity Card numbers (NRIC)
https://github.com/falti/ex_nricValidation for National Registration Identity Card numbers (NRIC) - falti/ex_nric - 1387What is Pub/Sub? | Pub/Sub Documentation | Google Cloud
https://cloud.google.com/pubsub/overviewUnderstand how Pub/Sub works and the different terms associated with Pub/Sub - 1388An Elixir client for DogStatsd https://www.datadoghq.com/
https://github.com/adamkittelson/dogstatsd-elixirAn Elixir client for DogStatsd https://www.datadoghq.com/ - adamkittelson/dogstatsd-elixir - 1389Easily access the Shopify API with Elixir.
https://github.com/nsweeting/shopifyEasily access the Shopify API with Elixir. Contribute to nsweeting/shopify development by creating an account on GitHub. - 1390An Elixir Client for the Particle Cloud API
https://github.com/jeffutter/particle-elixirAn Elixir Client for the Particle Cloud API. Contribute to jeffutter/particle-elixir development by creating an account on GitHub. - 1391Elixir client for exchangerate platform API
https://github.com/81dr/ex_changerateElixir client for exchangerate platform API. Contribute to 81dr/ex_changerate development by creating an account on GitHub. - 1392A Riemann client for Elixir, surprise!
https://github.com/koudelka/elixir-riemannA Riemann client for Elixir, surprise! Contribute to koudelka/elixir-riemann development by creating an account on GitHub. - 1393Elixir is a dynamic, functional language for building scalable and maintainable applications
https://github.com/elixir-lang/elixirElixir is a dynamic, functional language for building scalable and maintainable applications - elixir-lang/elixir - 1394Elixir wrapper for FFmpeg command line interface
https://github.com/talklittle/ffmpexElixir wrapper for FFmpeg command line interface. Contribute to talklittle/ffmpex development by creating an account on GitHub. - 1395Ecto's composable query multitool (.count, .random, .earliest, .latest, .find, .at, .on, etc.)
https://github.com/facto/plasmEcto's composable query multitool (.count, .random, .earliest, .latest, .find, .at, .on, etc.) - joshrieken/plasm - 1396Elixir implementation of the Git object storage, but with the goal to implement the same semantic with other storage and topics
https://github.com/awetzel/gitexElixir implementation of the Git object storage, but with the goal to implement the same semantic with other storage and topics - kbrw/gitex - 1397FitEx is a Macro-Module which provides a bit of sugar for function definitions.
https://github.com/timdeputter/FitExFitEx is a Macro-Module which provides a bit of sugar for function definitions. - timdeputter/FitEx - 1398Migrate your active record migrations to ecto compatible migrations
https://github.com/aforward/ar2ectoMigrate your active record migrations to ecto compatible migrations - aforward/ar2ecto - 1399A schema based keyword list option validator.
https://github.com/albert-io/optimalA schema based keyword list option validator. Contribute to albert-io/optimal development by creating an account on GitHub. - 1400Vim configuration files for Elixir
https://github.com/elixir-lang/vim-elixirVim configuration files for Elixir. Contribute to elixir-editors/vim-elixir development by creating an account on GitHub. - 1401Embedded translations for Elixir
https://github.com/belaustegui/transEmbedded translations for Elixir. Contribute to crbelaus/trans development by creating an account on GitHub. - 1402Simple dot/bracket notation parsing/conversion for Maps/Lists
https://github.com/whitfin/dot-notes-elixirSimple dot/bracket notation parsing/conversion for Maps/Lists - whitfin/dot-notes-elixir - 1403A module to decode/encode xml into a tree structure
https://github.com/Overbryd/exomlA module to decode/encode xml into a tree structure - Overbryd/exoml - 1404StatsD Client for Elixir (EOL: We Recommend Statix)
https://github.com/CargoSense/ex_statsdStatsD Client for Elixir (EOL: We Recommend Statix) - CargoSense/ex_statsd - 1405Elixir Internationalization library
https://github.com/change/linguistElixir Internationalization library. Contribute to change/linguist development by creating an account on GitHub. - 1406Hacks to add shell history to Erlang's shell
https://github.com/ferd/erlang-historyHacks to add shell history to Erlang's shell. Contribute to ferd/erlang-history development by creating an account on GitHub. - 1407Elixir library for generating XML
https://github.com/joshnuss/xml_builderElixir library for generating XML. Contribute to joshnuss/xml_builder development by creating an account on GitHub. - 1408UIFaces API client for Elixir applications.
https://github.com/katgironpe/ui_facesUIFaces API client for Elixir applications. Contribute to kathgironpe/ui_faces development by creating an account on GitHub. - 1409Connector to Vert.x event bus via TCP Event Bus Bridge
https://github.com/PharosProduction/ExVertxConnector to Vert.x event bus via TCP Event Bus Bridge - PharosProduction/ExVertx - 1410Elixir library for reading Java properties files from various sources.
https://github.com/stocks29/exjpropElixir library for reading Java properties files from various sources. - stocks29/exjprop - 1411Some Elixir support
https://github.com/mykewould/crutchesSome Elixir support. Contribute to mykewould/crutches development by creating an account on GitHub. - 1412Gettext Automatic Translator in Elixir
https://github.com/alexfilatov/getatrexGettext Automatic Translator in Elixir. Contribute to alexfilatov/getatrex development by creating an account on GitHub. - 1413Elixir vs Ruby | How Switching To Elixir Made Our Team Better
https://foxbox.com/blog/elixir-vs-ruby/Elixir is designed for programmer happiness. Here is why Elixir is better than Ruby, and why you should choose it as your programming language of choice. - 1414Digital Ocean API v2 Elixir Client
https://github.com/kevinmontuori/digocDigital Ocean API v2 Elixir Client. Contribute to bunnylushington/digoc development by creating an account on GitHub. - 1415A parameter validation library - based on Ecto
https://github.com/martinthenth/goalA parameter validation library - based on Ecto. Contribute to martinthenth/goal development by creating an account on GitHub. - 1416A frontend-independent IDE "smartness" server for Elixir. Implements the JSON-based "Language Server Protocol" standard and provides debugger support via VS Code's debugger protocol.
https://github.com/JakeBecker/elixir-lsA frontend-independent IDE "smartness" server for Elixir. Implements the JSON-based "Language Server Protocol" standard and provides debugger support via VS Code's debugger ... - 1417YAML 1.2 and JSON parser in pure Erlang
https://github.com/yakaz/yamerlYAML 1.2 and JSON parser in pure Erlang. Contribute to yakaz/yamerl development by creating an account on GitHub. - 1418A Elixir library for translating between hiragana, katakana, romaji, kanji and sound. It uses Mecab.
https://github.com/ikeikeikeike/exkanjiA Elixir library for translating between hiragana, katakana, romaji, kanji and sound. It uses Mecab. - ikeikeikeike/exkanji - 1419Simple Elixir wrapper for the GitHub API
https://github.com/edgurgel/tentacatSimple Elixir wrapper for the GitHub API. Contribute to edgurgel/tentacat development by creating an account on GitHub. - 1420The DNSimple API client for Elixir.
https://github.com/dnsimple/dnsimple-elixirThe DNSimple API client for Elixir. Contribute to dnsimple/dnsimple-elixir development by creating an account on GitHub. - 1421A curated list of awesome Erlang libraries, resources and shiny things.
https://github.com/drobakowski/awesome-erlangA curated list of awesome Erlang libraries, resources and shiny things. - drobakowski/awesome-erlang - 1422Elixir data validation library
https://github.com/bcoop713/skoomaElixir data validation library. Contribute to bobfp/skooma development by creating an account on GitHub. - 1423Elixir GTIN & UPC Generation and Validation Library
https://github.com/kickinespresso/ex_gtinElixir GTIN & UPC Generation and Validation Library - kickinespresso/ex_gtin - 1424A unified interface to Elixir and Erlang key/value stores.
https://github.com/christhekeele/mnemonixA unified interface to Elixir and Erlang key/value stores. - christhekeele/mnemonix - 1425Style Guide for the Elixir language, implemented by Credo
https://github.com/rrrene/elixir-style-guideStyle Guide for the Elixir language, implemented by Credo - rrrene/elixir-style-guide - 1426Common combinators for Elixir
https://github.com/robot-overlord/quarkCommon combinators for Elixir. Contribute to witchcrafters/quark development by creating an account on GitHub. - 1427Elixir client library for the Tradehub blockchain
https://github.com/anhmv/tradehub-elixirElixir client library for the Tradehub blockchain. Contribute to mcvnh/tradehub-elixir development by creating an account on GitHub. - 1428Build software better, together
https://github.com/katgironpe/random_userGitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 1429A YAML encoder for Elixir.
https://github.com/ufirstgroup/ymlrA YAML encoder for Elixir. Contribute to ufirstgroup/ymlr development by creating an account on GitHub. - 1430An alternative BEAM implementation, designed for WebAssembly
https://github.com/lumen/lumenAn alternative BEAM implementation, designed for WebAssembly - GetFirefly/firefly - 1431Siftscience API Library for Elixir
https://github.com/C404/sift_exSiftscience API Library for Elixir. Contribute to C404/sift_ex development by creating an account on GitHub. - 1432Home
https://github.com/elixir-lang/elixir/wikiElixir is a dynamic, functional language for building scalable and maintainable applications - elixir-lang/elixir - 1433Fast SAX parser and encoder for XML in Elixir
https://github.com/qcam/saxyFast SAX parser and encoder for XML in Elixir. Contribute to qcam/saxy development by creating an account on GitHub. - 1434kbrw/sweet_xml
https://github.com/awetzel/sweet_xmlContribute to kbrw/sweet_xml development by creating an account on GitHub. - 1435Data Validation for Elixir
https://github.com/CargoSense/vexData Validation for Elixir. Contribute to CargoSense/vex development by creating an account on GitHub. - 1436読める、読めるぞぉ!!
https://github.com/Joe-noh/yomel読める、読めるぞぉ!! Contribute to Joe-noh/yomel development by creating an account on GitHub. - 1437APNS for Elixir
https://github.com/chvanikoff/apns4exAPNS for Elixir. Contribute to chvanikoff/apns4ex development by creating an account on GitHub. - 1438Unofficial Elixir Client for the Authorize.NET API
https://github.com/marcelog/elixir_authorizenetUnofficial Elixir Client for the Authorize.NET API - marcelog/elixir_authorizenet - 1439Build software better, together
https://github.com/attm2x/m2x-elixirGitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 1440Organize material to teach functional programming using Elixir
https://github.com/kblake/functional-programmingOrganize material to teach functional programming using Elixir - kblake/functional-programming - 1441Elixir library that provides macros which allow you to encapsulate business logic and validate incoming parameters with predefined contract.
https://github.com/madeinussr/exopElixir library that provides macros which allow you to encapsulate business logic and validate incoming parameters with predefined contract. - implicitly-awesome/exop - 1442A Darksky.net (formerly forecast.io) weather API client for Elixir
https://github.com/techgaun/darkskyxA Darksky.net (formerly forecast.io) weather API client for Elixir - techgaun/darkskyx - 1443Sunsetting Atom
https://atom.io/packages/language-elixirWe are archiving Atom and all projects under the Atom organization for an official sunset on December 15, 2022. - 1444Telegram bot framework and API client written in Elixir
https://github.com/telegex/telegexTelegram bot framework and API client written in Elixir - telegex/telegex - 1445Elixir support for VSCode https://marketplace.visualstudio.com/items?itemName=mjmcloug.vscode-elixir
https://github.com/mat-mcloughlin/vscode-elixirElixir support for VSCode https://marketplace.visualstudio.com/items?itemName=mjmcloug.vscode-elixir - mat-mcloughlin/vscode-elixir - 1446Instagram client library for Elixir/Phoenix apps
https://github.com/arthurcolle/exstagramInstagram client library for Elixir/Phoenix apps. Contribute to stochastic-thread/exstagram development by creating an account on GitHub. - 1447Exercism exercises in Elixir.
https://github.com/exercism/xelixirExercism exercises in Elixir. Contribute to exercism/elixir development by creating an account on GitHub. - 1448Elixir library for accessing the Desk.com API
https://github.com/deadkarma/exdeskElixir library for accessing the Desk.com API. Contribute to bryanbrunetti/exdesk development by creating an account on GitHub. - 1449An Elixir Library for Stripe
https://github.com/robconery/stripity-stripeAn Elixir Library for Stripe. Contribute to beam-community/stripity-stripe development by creating an account on GitHub. - 1450Elixir library for Conekta api calls
https://github.com/echavezNS/conekta-elixirElixir library for Conekta api calls. Contribute to altyaper/conekta-elixir development by creating an account on GitHub. - 1451Elixir client libraries for accessing Google APIs.
https://github.com/GoogleCloudPlatform/elixir-google-apiElixir client libraries for accessing Google APIs. - googleapis/elixir-google-api - 1452Syncfusion Free Ebooks | Elixir Succinctly
https://www.syncfusion.com/ebooks/elixir-succinctlyAuthor Emanuele DelBono guides readers along the first steps of mastering the Elixir programming language in Elixir Succinctly. Providing a brief overview ... - 1453Elixir for Programmers
https://codestool.coding-gnome.com/courses/elixir-for-programmersQuick-start: Programmers can learn Elixir faster. Write functional, concurrent, and reliable applications. Learn Elixir, OTP, and Phoenix. - 1454Elixir JSON-RPC client for the Ethereum blockchain 0x063D3d782598744AF1252eBEaf3aA97D990Edf72
https://github.com/exthereum/ethereumexElixir JSON-RPC client for the Ethereum blockchain 0x063D3d782598744AF1252eBEaf3aA97D990Edf72 - mana-ethereum/ethereumex - 1455Kamil Skowron
https://www.youtube.com/c/kamilskowronHi 👋 I'm Kamil Skowron, a backend software developer with a passion for functional programming. I would like to dedicate the Frathon channel to promote functional programming where I will be publishing "real world" programming videos. - 1456Elixir Foundation
https://www.youtube.com/playlist?list=PLjQo0sojbbxXc4aWg5i2umjv7U8YDoHQTFor anyone getting into elixir and functional programming. This playlist is a great way to start! Become a Member and access all Videos! https://www.youtube.... - 145701 Curso de Elixir - Instalación de Elixir en Ubuntu.
https://www.youtube.com/watch?v=-K74G9nlzSY&list=PLMLox3fRb_I4_4-DnU3yS_EglDAuVpeEgCurso de Elixir: en este primer capitulo del curso vamos a ver como podemos instalar Elixir y el ecosistema de Erlang dentro de Ubuntu junto con todas las de... - 1458Stripe | Financial Infrastructure to Grow Your Revenue
https://stripe.com/.Stripe powers online and in-person payment processing and financial solutions for businesses of all sizes. Accept payments, send payouts, and automate financial processes with a suite of APIs and no-code tools. - 1459Datastore
https://cloud.google.com/datastore/Datastore is a highly scalable NoSQL database for your web and mobile applications.
FAQ'sto know more about the topic.
mail [email protected] to add your project or resources here 🔥.
- 1What is Elixir and why is it used?
- 2How does Elixir differ from Ruby?
- 3What are the key features of Elixir?
- 4What is the Phoenix framework?
- 5How does Elixir handle concurrency?
- 6What are some common use cases for Elixir?
- 7What are Elixir's performance advantages?
- 8How can I learn Elixir effectively?
- 9What is a GenServer in Elixir?
- 10What are the best practices for Elixir development?
- 11What libraries and tools should I know for Elixir?
- 12What is the role of pattern matching in Elixir?
- 13How does Elixir support metaprogramming?
- 14What is the Elixir ecosystem like?
- 15What challenges might I face when learning Elixir?
- 16How do I manage dependencies in Elixir?
- 17Why does my Elixir application crash with 'badarg' error?
- 18How can I fix 'function not exported' error in Elixir?
- 19What should I do when my Elixir application hangs?
- 20How do I resolve 'no function clause matching' error in Elixir?
- 21Why is my Elixir application slow?
- 22How do I handle exceptions in Elixir?
- 23Why am I getting 'timeout' errors in my Elixir application?
- 24How do I optimize my Elixir code for better performance?
- 25How can I improve the error handling in my Elixir application?
- 26How do I resolve 'ArgumentError' in Elixir?
- 27What causes 'bad match' errors in Elixir?
- 28How do I debug Elixir applications effectively?
- 29What is the best way to manage state in Elixir?
- 30How can I ensure my Elixir application is fault-tolerant?
- 31What is the difference between 'spawn' and 'Task' in Elixir?
- 32How do I use pattern matching in Elixir?
- 33What are the common pitfalls to avoid in Elixir?
- 34How can I handle asynchronous operations in Elixir?
- 35What are the best practices for writing tests in Elixir?
- 36How do I manage dependencies in Elixir projects?
- 37What is the purpose of Mix in Elixir?
- 38How can I integrate Elixir with a database?
- 39What is a GenServer in Elixir?
- 40How do I resolve 'ArgumentError' in Elixir?
- 41What causes 'bad match' errors in Elixir?
- 42How do I debug Elixir applications effectively?
- 43What is the best way to manage state in Elixir?
- 44How can I ensure my Elixir application is fault-tolerant?
- 45What is the difference between 'spawn' and 'Task' in Elixir?
- 46How do I use pattern matching in Elixir?
- 47What are the common pitfalls to avoid in Elixir?
- 48How can I handle asynchronous operations in Elixir?
- 49What are the best practices for writing tests in Elixir?
- 50How do I manage dependencies in Elixir projects?
- 51What is the purpose of Mix in Elixir?
- 52How can I integrate Elixir with a database?
- 53What is a GenServer in Elixir?
- 54How can I manage dependencies across different environments in Elixir?
- 55What is the purpose of supervision trees in Elixir?
- 56How do I implement a REST API in Elixir?
- 57How can I deploy an Elixir application?
- 58What are the benefits of using Elixir for web development?
- 59What are processes in Elixir, and how do they work?
- 60How can I use macros in Elixir?
- 61How can I optimize performance in Elixir applications?
- 62What is the difference between a process and a thread in Elixir?
- 63What is the role of `:ets` in Elixir applications?
- 64How do I perform error handling in Elixir?
- 65What is Ecto and how does it relate to Elixir?
- 66How do I work with JSON in Elixir?
- 67What is the significance of `supervisor` in Elixir?
- 68How does Elixir handle concurrency?
- 69What is Phoenix LiveView and its benefits?
- 70How do I test Elixir applications effectively?
- 71What is the purpose of `:telemetry` in Elixir?
- 72How can I use Elixir with Docker?
- 73What are some common performance pitfalls in Elixir?
- 74How do I implement background jobs in Elixir?
- 75What are Elixir protocols and how do I use them?
- 76How can I improve my Elixir application's security?
- 77What are some popular libraries in the Elixir ecosystem?
- 78How do I set up a new Elixir project?
- 79What is the Elixir community like?
- 80What are the benefits of using Elixir for web development?
- 81What is a GenServer in Elixir?
- 82How can I handle configuration in an Elixir application?
- 83What is the difference between `Map` and `Struct` in Elixir?
- 84What are Elixir Mix tasks and how do I create one?
- 85How do I manage dependencies in Elixir?
- 86What is a Supervisor in Elixir?
- 87How do I perform pattern matching in Elixir?
- 88What is the difference between `receive` and `send` in Elixir?
- 89How can I deploy an Elixir application?
- 90What are Elixir's data types?
- 91What is Ecto and how do I use it?
- 92How can I use Elixir for real-time applications?
- 93What is the role of the BEAM in Elixir?
- 94How does Elixir handle errors and exceptions?
- 95What is the purpose of `Mix` in Elixir?
- 96How can I test my Elixir application?
- 97What is a protocol in Elixir?
- 98How does Elixir handle concurrency?
- 99What is the Elixir release system?
- 100What are the key differences between Elixir and Erlang?
- 101How do I create and manage dependencies in Elixir?
- 102What is the significance of the `def` keyword in Elixir?
- 103What is a macro in Elixir?
- 104How do I create an Elixir module?
- 105What are `:atoms` in Elixir?
- 106How do I handle JSON in Elixir?
- 107What are the common use cases for Elixir?
- 108What is the role of the Elixir community?
- 109What are Elixir's strengths in web development?
- 110How do I manage state in Elixir?
- 111What are Elixir's data types?
- 112How do I use pattern matching in Elixir?
- 113What is the Elixir mix tool?
- 114What are Elixir macros?
- 115How do I handle concurrent tasks in Elixir?
- 116What are agents in Elixir?
- 117What is the purpose of structs in Elixir?
- 118How does Elixir handle errors?
- 119What is the Phoenix framework?
- 120What are the key differences between Elixir and Ruby?
- 121How can I learn Elixir effectively?
- 122What is the Elixir community like?
- 123How does Elixir handle dependencies?
- 124What are the benefits of functional programming in Elixir?
- 125What is the significance of the BEAM VM in Elixir?
- 126What is a GenServer in Elixir?
- 127How can I deploy an Elixir application?
- 128What is Ecto in Elixir?
- 129Why should I choose Full Elixir over other programming languages?
- 130Why is fault tolerance important in Full Elixir applications?
- 131Why is the functional programming paradigm beneficial in Full Elixir?
- 132Why is Full Elixir popular for building web applications?
- 133Why does Full Elixir emphasize immutability?
- 134Why is concurrency a key feature of Full Elixir?
- 135Why is Full Elixir suitable for microservices architecture?
- 136Why is testing emphasized in Full Elixir development?
- 137Why is the Full Elixir community important for developers?
- 138Why does Full Elixir support metaprogramming?
- 139Why is documentation important in Full Elixir?
- 140Why does Full Elixir prioritize community-driven development?
- 141Why is performance optimization critical in Full Elixir?
- 142Why is Full Elixir considered a great choice for real-time applications?
- 143Why is functional programming beneficial in Full Elixir?
- 144Why is pattern matching significant in Full Elixir?
- 145Why is documentation culture encouraged in Full Elixir?
- 146Why is testing emphasized in Full Elixir development?
- 147Why is Elixir's concurrency model advantageous?
- 148Why is the Phoenix framework important for Full Elixir?
- 149Why should I choose Full Elixir for microservices architecture?
- 150Why is Elixir's fault tolerance essential for production systems?
- 151Why is the Elixir community significant for developers?
- 152Why is Elixir's ecosystem beneficial for web development?
- 153Why is Elixir's performance important for high-traffic applications?
- 154Why is Elixir's immutability beneficial for state management?
- 155Why is Elixir suitable for building APIs?
- 156Why is the Elixir syntax considered user-friendly?
- 157Why is Elixir popular for data processing applications?
- 158Why is Elixir's functional programming paradigm advantageous?
- 159Why is Full Elixir favored for real-time applications?
- 160Why is Elixir a good choice for e-commerce platforms?
- 161Why should I consider Elixir for building mobile backends?
- 162Why is Elixir a strong candidate for cloud-native applications?
- 163Why is Elixir popular for building distributed systems?
- 164Why is Elixir's community important for developers?
- 165Why is Elixir's ecosystem beneficial for developers?
- 166Why is Elixir a great choice for microservices architecture?
- 167Why is Elixir beneficial for building scalable web applications?
- 168Why is Elixir well-suited for building APIs?
- 169Why is Elixir ideal for building chat applications?
- 170Why is Elixir useful for building IoT applications?
- 171Why is Elixir a great option for building gaming servers?
- 172Why is Elixir beneficial for data analysis applications?
- 173Why is Elixir a strong choice for building content management systems?
- 174Why is Elixir advantageous for building e-commerce applications?
- 175Why is Elixir beneficial for building SaaS applications?
- 176Why is Elixir a good fit for real-time data processing?
- 177Why is Elixir advantageous for building financial applications?
- 178Why is Elixir suitable for building monitoring and observability tools?
- 179Why is Elixir a great choice for developing microservices?
- 180Why is Elixir effective for building event-driven architectures?
- 181Why is Elixir suitable for building machine learning applications?
- 182Why is Elixir a good choice for building distributed systems?
- 183Why is Elixir advantageous for building collaborative applications?
- 184Why is Elixir a strong choice for building streaming applications?
- 185Why is Elixir effective for building APIs?
- 186Why is Elixir beneficial for developing chat applications?
- 187Why is Elixir a strong choice for building dashboards?
- 188Why is Elixir effective for building gaming applications?
- 189Why is Elixir advantageous for developing automated testing frameworks?
- 190Why is Elixir suitable for building financial applications?
- 191Why is Elixir a strong choice for building real-time applications?
- 192Why is Elixir effective for developing SaaS applications?
- 193Why is Elixir beneficial for building content management systems?
- 194Why is Elixir a good choice for building e-commerce platforms?
- 195Why is Elixir effective for building social media applications?
- 196Why is Elixir suitable for building machine learning applications?
- 197Why is Elixir beneficial for building IoT applications?
- 198Why is Elixir a great choice for developing collaborative tools?
- 199Why is Elixir effective for building educational platforms?
- 200Why is Elixir preferred for developing chat applications?
- 201Why is Elixir advantageous for building gaming applications?
- 202Why is Elixir a strong choice for building health tech applications?
- 203Why is Elixir effective for developing API services?
- 204Why is Elixir advantageous for building automation tools?
- 205Why is Elixir effective for building microservices?
- 206Why is Elixir suitable for building e-commerce platforms?
- 207Why is Elixir effective for building financial applications?
- 208Why is Elixir advantageous for developing logistics and supply chain solutions?
- 209Why is Elixir suitable for building customer support applications?
- 210Why is Elixir effective for building social media platforms?
- 211Why is Elixir advantageous for developing educational platforms?
- 212Why is Elixir suitable for building news and media applications?
- 213Why is Elixir effective for building content management systems?
- 214Why is Elixir advantageous for building Internet of Things (IoT) applications?
- 215Why is Elixir effective for developing event-driven applications?
- 216Why is Elixir beneficial for real-time collaboration tools?
- 217Why is Elixir effective for building video streaming applications?
- 218Why is Elixir suitable for building job scheduling applications?
- 219Why is Elixir advantageous for building APIs?
- 220Why is Elixir effective for building mobile backends?
- 221Why is Elixir suitable for building chat applications?
- 222Why is Elixir effective for building gaming applications?
- 223Why is Elixir advantageous for building workflow automation tools?
- 224Why is Elixir suitable for developing enterprise applications?
- 225Why is Elixir effective for building microservices architectures?
- 226Why is Elixir suitable for developing financial applications?
- 227Why is Elixir effective for building e-commerce platforms?
- 228Why is Elixir advantageous for building health tech applications?
- 229Why is Elixir suitable for developing social impact applications?
- 230Why is Elixir effective for building API gateways?
- 231Why is Elixir beneficial for building healthcare applications?
- 232Why is Elixir effective for developing fintech applications?
- 233Why is Elixir suitable for building social media platforms?
- 234Why is Elixir effective for developing e-commerce solutions?
- 235Why is Elixir advantageous for IoT applications?
- 236Why is Elixir effective for building real-time analytics platforms?
- 237Why is Elixir suitable for developing content management systems?
- 238Why is Elixir effective for building enterprise resource planning (ERP) systems?
- 239Why is Elixir advantageous for developing educational platforms?
- 240Why is Elixir a good choice for building gaming applications?
- 241Why is Elixir effective for developing logistics and supply chain applications?
- 242Why is Elixir advantageous for building travel and booking applications?
- 243Why is Elixir suitable for developing customer relationship management (CRM) systems?
- 244Why is Elixir effective for developing media streaming applications?
- 245Why is Elixir suitable for developing smart city applications?
- 246Why is Elixir effective for developing machine learning applications?
- 247Why is Elixir beneficial for building chat applications?
- 248Why is Elixir suitable for building blockchain applications?
- 249Why is Elixir a strong choice for building event-driven architectures?
- 250Why is Elixir beneficial for building collaborative applications?
- 251Why is Elixir effective for developing SaaS applications?
- 252Why is Elixir suitable for building microservices architectures?
- 253Why is Elixir advantageous for building data-intensive applications?
- 254Why is Elixir effective for building automation and orchestration tools?
Queriesor most google FAQ's about Elixir.
mail [email protected] to add more queries here 🔍.
- 1
should i learn elixir - 3
is elixir worth learning - 4
what is elixir programming language used for - 5
who is creator of elixir - 6
where elixir is used - 7
when elixir is get popular - 8
who uses elixir language - 9
are elixir strings worth it - 10
why use elixir language - 11
why elixir language - 12
who uses elixir strings - 13
what is elixir software - 14
- 15
what is elixir programming - 16
is elixir a functional language - 17
- 18
when was elixir created - 19
is elixir a good language - 20
why learn elixir - 21
what is elixir used for programming - 22
what is elixir language used for - 23
who uses elixir - 24
what is elixir programming used for
More Sitesto check out once you're finished browsing here.
https://www.0x3d.site/0x3d is designed for aggregating information.https://nodejs.0x3d.site/NodeJS Online Directoryhttps://cross-platform.0x3d.site/Cross Platform Online Directoryhttps://open-source.0x3d.site/Open Source Online Directoryhttps://analytics.0x3d.site/Analytics Online Directoryhttps://javascript.0x3d.site/JavaScript Online Directoryhttps://golang.0x3d.site/GoLang Online Directoryhttps://python.0x3d.site/Python Online Directoryhttps://swift.0x3d.site/Swift Online Directoryhttps://rust.0x3d.site/Rust Online Directoryhttps://scala.0x3d.site/Scala Online Directoryhttps://ruby.0x3d.site/Ruby Online Directoryhttps://clojure.0x3d.site/Clojure Online Directoryhttps://elixir.0x3d.site/Elixir Online Directoryhttps://elm.0x3d.site/Elm Online Directoryhttps://lua.0x3d.site/Lua Online Directoryhttps://c-programming.0x3d.site/C Programming Online Directoryhttps://cpp-programming.0x3d.site/C++ Programming Online Directoryhttps://r-programming.0x3d.site/R Programming Online Directoryhttps://perl.0x3d.site/Perl Online Directoryhttps://java.0x3d.site/Java Online Directoryhttps://kotlin.0x3d.site/Kotlin Online Directoryhttps://php.0x3d.site/PHP Online Directoryhttps://react.0x3d.site/React JS Online Directoryhttps://angular.0x3d.site/Angular JS Online Directory